




Т bi = bi / Sbi, i = 0, 1, 2, …, m, (2.12)
имеющая распределение Стьюдента.
Правило проверки заключается в выполнении следующих действий.
1. Вычисляется наблюдаемое значение критерия для i -го коэффициента (2.12).
2. По заданным уровням значимости 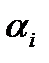 , i = 0, 1, …, m и степени свободы
, i = 0, 1, …, m и степени свободы  по таблице распределения Стьюдента определяются критические значения распределения t крит(
по таблице распределения Стьюдента определяются критические значения распределения t крит( ).
).
3. Сравниваются наблюдаемые и критические значения между собой. Результатом сравнения является вывод о значимости коэффициентов b 0, b 1, b 2, …, bm.
2. Интервальные оценки коэффициентов уравнения регрессии.
Так как объем выборки ограничен, то b 0, b 1, b 2, …, b m – случайные величины, поэтому желательно найти доверительные интервалы для истинных значений 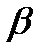 0, 1, 2, …, m. Для этого также используется t – критерий Стьюдента. Интервальные оценки коэффициентов уравнения регрессии определяются по формулам
0, 1, 2, …, m. Для этого также используется t – критерий Стьюдента. Интервальные оценки коэффициентов уравнения регрессии определяются по формулам
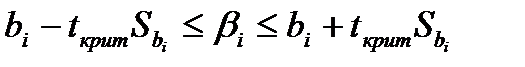 (2.13)
(2.13)
3. Проверка общего качества уравнения регрессии.
Для этой цели, как и в случае парной регрессии, используется коэффициент детерминации R2:
R 2 = 1 -  еi 2 / (yi -
еi 2 / (yi - 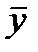 )2. (2.14)
)2. (2.14)
В множественной регрессии каждая новая переменная хi приводит к увеличению R 2, хотя это еще не означает, что уравнение регрессии становится более значимым. Чтобы исключить эту зависимость от числа переменных, иногда используют так называемый скорректированный коэффициент детерминации:
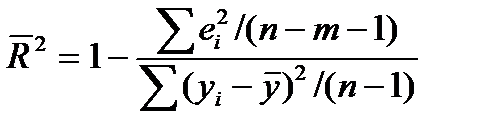 . (2.15)
. (2.15)
Или эту формулу можно преобразовать к виду:
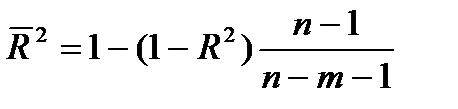 . (2.16)
. (2.16)
4. Анализ статистической значимости коэффициента детерминации.
По величине R 2 можно только предполагать насколько значимо или не значимо уравнение регрессии. Даже при небольшой величине R 2 (< 0,5) не всегда следует отказываться от уравнения регрессии. Для этого необходимо проверить статистическую значимость самого коэффициента детерминации. Для чего проверяются гипотезы
Н 0: R 2 = 0,
Н 1: R 2 > 0.
Для проверки используется распределение Фишера. Вычисляется F – статистика:
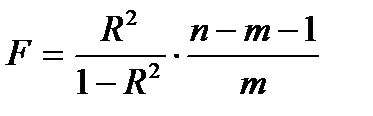 . (2.17)
. (2.17)
При заданном уровне значимости  по таблице критических точек Фишера находится fкр, и если F > fкр, то R 2 статистически значим.
по таблице критических точек Фишера находится fкр, и если F > fкр, то R 2 статистически значим.
5. Проверка выполнимости предпосылок МНК с помощью статистики Дар бина-Уотсона.
Статистическая значимость коэффициентов регрессии и близкое к единице значение коэффициента детерминации R 2 еще не гарантируют высокое качество уравнения регрессии. Если не выполняются необходимые предпосылки МНК об отклонениях  , то коэффициенты регрессии и само уравнение являются не вполне состоятельными, а это значит что внешние признаки «хорошего» уравнения не отвечают действительности. Поэтому следующим этапом проверки качества уравнения регрессии является проверка соответствия выборочных данных предпосылкам МНК. Для этого воспользуемся статистикой Дарбина – Уотсона, которая устанавливает, в частности, наличие или отсутствие статистической зависимости между ошибками . Так как истинные значения неизвестны, то проверка осуществляется в отношении оценок ошибок еi. При этом проверяется некоррелированность соседних значений еi.
, то коэффициенты регрессии и само уравнение являются не вполне состоятельными, а это значит что внешние признаки «хорошего» уравнения не отвечают действительности. Поэтому следующим этапом проверки качества уравнения регрессии является проверка соответствия выборочных данных предпосылкам МНК. Для этого воспользуемся статистикой Дарбина – Уотсона, которая устанавливает, в частности, наличие или отсутствие статистической зависимости между ошибками . Так как истинные значения неизвестны, то проверка осуществляется в отношении оценок ошибок еi. При этом проверяется некоррелированность соседних значений еi.
Статистика Дарбина – Уотсона DW рассчитывается по формуле:
 . (2.18)
. (2.18)
По таблицам критических точек Дарбина – Уотсона, входными параметрами которых являются: n – число наблюдений; m – количество объясняющих переменных; - уровень значимости, определяются два числа: d 1 – нижняя граница; du – верхняя граница.
Выводы осуществляются по следующей схеме.
Если DW < d 1, то это свидетельствует о положительной автокорреляции остатков.
Если DW > 4 - d 1, то это свидетельствует об отрицательной автокорреляции остатков.
При du < DW < 4 – du принимается гипотеза об отсутствии автокорреляции остатков.
Если d 1 < DW < du или 4 – du < DW < 4 – d 1, то остается неопределенность по вопросу наличия или отсутствия автокорреляции остатков.
В случае обнаружения признака автокорреляции необходимо скорректировать уравнение регрессии в соответствии с рекомендациями Главы IV
6. Прогноз значений зависимой переменной.
По аналогии с парной регрессией может быть построена интервальная оценка для среднего значения прогноза. Здесь речь идет о возможных значениях Yр при определенных значениях вектора объясняющей переменной Хр = (1, х 1 р , х 2 р , …, хmр)т.
Интервальный прогноз для среднего значения вычисляется следующим образом:
 р
р 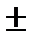 tкр S
tкр S 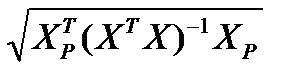 , (2.19)
, (2.19)
где р = b 0 + b 1 x 1 р + b 2 x 2 р + …+ bm xmр; t кр – критическое значение, полученное по распределению Стьюдента при количестве степеней свободы 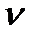 = n - m- 1 и заданной вероятности
= n - m- 1 и заданной вероятности  /2.
/2.

