




Принципы спецификации эконометрической модели:
1. Эконометрическая модель возникает в итоге записи математическим языком взаимосвязей исходных данных и искомых неизвестных. В процессе такой записи стараются привлекать линейные алгебраические функции.
2.Количество уравнений модели обязано совпадать с числом искомых неизвестных. Этот принцип необходим для трансформации модели к приведенной форме (где каждая эндогенная переменная представляется в виде явной функции только экзогенных переменных).
3. Переменные модели датируются, что позволяет нам получить динамическую модель, в которой текущие эндогенные переменные объясняются значениями предопределенных.
4. Поведенческие уравнения модели включают в себя случайные возмущения, таким образом, мы отражаем в спецификации влияние на текущие эндогенные переменные неучтенных факторов (повышая тем самым адекватность модели).
На основании всех четырех принципов спецификации в самом общем случае структурная форма эконометрической модели имеет вид:

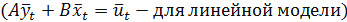
а приведенная форма:
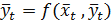

Эконометрическая модель Самуэльсона–Хикса делового цикла экономики
Спецификация модели (структурная форма):

текущие эндогенные переменные (объясняемые):
¾  - уровень потребления в текущем периоде
- уровень потребления в текущем периоде
¾  - объем инвестиций в текущем периоде
- объем инвестиций в текущем периоде
¾  - государственные расходы в текущем периоде
- государственные расходы в текущем периоде
¾  - объем ВВП в текущем периоде
- объем ВВП в текущем периоде
предопределенные переменные (объясняющие):
¾  – объем ВВП в предшествующем периоде
– объем ВВП в предшествующем периоде
¾  – объем ВВП в предпредшествующем периоде
– объем ВВП в предпредшествующем периоде
¾  – государственные расходы в предшествующем периоде
– государственные расходы в предшествующем периоде
Приведенная форма модели:

Компактная запись
Обозначив векторы текущих эндогенных переменных  и предопределенных переменных
и предопределенных переменных  , мы можем записать модель Самуэльсона-Хикса в компактном виде:
, мы можем записать модель Самуэльсона-Хикса в компактном виде:

Составив матрицы  и
и  получим компактную запись:
получим компактную запись:

5. Схема построения эконометрических моделей (на примере эконометрической модели Оукена).
Для начала отметим основные 4-е этапа построения эконометрических моделей:
1)построение спецификации эконометрической модели;
2)сбор и проверка статистической информации об объекте-оригинале в виде конкретных значений экзогенных и эндогенных переменных, включённых в спецификацию модели;
3)оценивание неизвестных параметров модели (настройка или идентификация модели);
4)проверка адекватности оценённой модели (проверка соответствия настроенной модели объекту- оригиналу; верификация).
1. Рассмотрим эконометрическую модель Оукена. Будем считать, что Темп прироста реального ВВП зависит от изменения уровня безработицы. Тогда модель можно представить в виде:
 , где Yt- Темп прироста реального ВВП,
, где Yt- Темп прироста реального ВВП,
xt - изменения уровня безработицы,  -константа.
-константа.
Yt-эндогенная переменная.
Xt- экзогенная.
a0,a1 – параметры модели, подлежащие оценке.
Параметр  имеет смысл среднего квадратического разброса вокруг нуля возможных значений случайного возмущения
имеет смысл среднего квадратического разброса вокруг нуля возможных значений случайного возмущения  , отражающего влияние на уровень текущего темпа прироста реального ВВП не определенных в модели факторов.
, отражающего влияние на уровень текущего темпа прироста реального ВВП не определенных в модели факторов.
2.Таблица с данными. Сбор статической информации в виде конкретных значений экзогенных и эндогенных переменных, входящих в спецификацию модели.
Собранная статическая информация требуется для оценивания неизвестных параметров модели (настройка модели). Собранная информация разделяется на 2 части:
· Обучающая выборка (предназначена для определения параметров модели)
· Контролирующая выборка (для проверки адекватности информации)
3.На 3 этапе по обучающей выборке методами математической статистики отыскиваются оценки 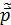 (приближенный значения) неизвестных параметров.
(приближенный значения) неизвестных параметров.
4.На 4 этапе оцененная модель  исследуется на адекватность.
исследуется на адекватность.
Модель признается адекватной, если ошибки прогнозов значений эндогенной переменной из контролирующей выборки не превышают критических уровней.
Прогнозы вычисляются по приведенной форме:

6. Порядок оценивания линейной эконометрической модели из изолированного уравнения в Excel. Смысл выходной статистической информации функции ЛИНЕЙН.
 У нас построена линейная эконометрическая модель с изолированными переменными:
У нас построена линейная эконометрическая модель с изолированными переменными:
Рассмотрим спецификацию данного вида.
В этой модели экзогенных переменных х1 и х2 и одна эндогенная переменная уt. Случайное возмущение u предполагается гомоскедастичным. Спецификация содержит 4 параметра: а0, а1, а2,  .
.
Модели данного типа называются линейными эконометрическими моделями в виде изолированных уравнений с несколькими объясняющими переменными или линейной множественной регрессии.
Порядок оценивания модели состоит в следующем:
Ввести исходные данные или открыть из существующего файла, содержащего анализируемые данные;
В данном случае выделяем область пустых ячеек 5*3 (5 строк, 3 столбца) для вывода результатов регрессионной статистики (функция линейн).
В общем случае: подготавливаем область, состоящую всегда из 5 строк, а столбцов столько, сколько коэффициентов требуется оценить, но минимум 2(а0, а1).
Активизировать Мастер функций любым из способов:
В главном меню выбрать Вставка/Функция
На панели инструментов Стандартная щелкнуть на кнопке Вставка функции;
В окне Категория выбрать Статистические, в окне Функция – ЛИНЕЙН, щелкнуть ОК;
Заполнить аргументы функции:
Известные значения y – диапазон, содержащий данные результативного признака;
Известные значения x – диапазон, содержащий данные факторов независимого признака;
Константа – логическое значение, которое указывает на наличие или на отсутствие свободного члена в уравнении. Если Константа =1, то свободный член рассчитывается обычным образом, если Константа=0, то свободный член равен 0;
Статистика – логическое значение, которое указывает, выводить дополнительную информацию или нет. Если статистика =1, то дополнительная информация выводится, если Статистика =0, то выводятся только оценки параметров уравнения.
Нажать комбинацию клавиш <CTRL>+<SHIFT>+<ENTER>.
Щелкнуть ОК.
Дополнительная регрессионная статистика будет выводиться в порядке, указанном в следующей схеме:
| a2~ | a1~ | a0~ оценка коэффициента |
| S(a2~) | S(a1~) | S(a0~) стандартные ошибки |
| R^2 доля дисперсии эндогенной переменной, объясн. уравнением регрессии |  оценка среднего квадратичного отклонения остатка (оценка случайного возмущения) оценка среднего квадратичного отклонения остатка (оценка случайного возмущения)
| Н/Д |
| F статистика Фишера, предназначенная для проверки статической значимости коэф. детерминации | υ2 стемени свободы | Н/Д |
 регрессионная сумма квадратов регрессионная сумма квадратов
|  остаточная сумма квадратов остаточная сумма квадратов
| Н/Д |
7. Случайная переменная и закон её распределения. Нормальный закон распределения и его параметры.
Переменная величина x c областью изменения X называется случайной, если свои возможные значения q из множества X она принимает в результате некоторого опыта со случайными элементарными исходами вида 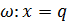 .
.
x- дискретная случайная переменная, если множество Х состоит из конечного или счетного количества констант  .
.
З-н распределения дискретной случайной переменной- функция  скалярного аргумента q с областью определения
скалярного аргумента q с областью определения  , характеризующая возможность появления в опыте значений q случайной переменной x.
, характеризующая возможность появления в опыте значений q случайной переменной x.
З-н распределения дискретной случайной переменной называется вероятностной функцией, значение которой равны вероятностям появления в опыте возможного значения сл. переменной: 
Нормальный закон распределения случайной величины имеет вид (НормРаспр, НормОбр):

параметры: математическое ожидание m и среднее квадратическое отклонение - сигма.
Нормальный закон возникает тогда, когда случайная переменная х формируется под воздействием большого числа независимых факторов.
8. Случайная переменная и закон её распределения. Распределение хи-квадрат.
Переменная величина называется случайной, если свои возможные значения она принимает в рез-те некоторого опыта, и до его завершения не возможно предсказать какое точно значение она примет.
З-н распределения дискретной случайной переменной- функция скалярного аргумента q с областью определения , характеризующая возможность появления в опыте значений q случайной переменной x.
З-н распределения дискретной случайной переменной называется вероятностной функцией, значение которой равны вероятностям появления в опыте возможного значения сл. переменной: 
Закон распределения хи-квадрат случайной величины имеет вид(ХИ2РАСП,ХИ2ОБР):
 ,
,
 , где n-натуральное число(параметр закона).
, где n-натуральное число(параметр закона).
9. Случайная переменная и закон её распределения. Распределение Стьюдента, Квантиль, t крит уровня  и её расчёт в Excel.
и её расчёт в Excel.
Опр1. Случайной называют переменную которая в результате испытания примет одно и только одно возможное значение, наперед не известное и зависящее от случайных причин, которые невозможно заранее учесть.
Опр2. Переменная x с областью изменения X называется случайной, если свои возможные значения q из множества X переменная x принимает в результате некоторого опыта со случайными элементарными исходами вида .
Закон распределения – функция 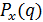 скалярного аргумента q, определенная на всей числовой прямой, характеризующую объективную возможность появления в опыте значений q случайной переменной x.
скалярного аргумента q, определенная на всей числовой прямой, характеризующую объективную возможность появления в опыте значений q случайной переменной x.
Полной характеристикой СП служит её дифференциальный закон распределения (ЗР). Так называется функция  скалярного аргумента q, определённая на всей числовой прямой, характеризующая объективную возможность появления в опыте
скалярного аргумента q, определённая на всей числовой прямой, характеризующая объективную возможность появления в опыте  значений СП x. Если x – ДСП, то
значений СП x. Если x – ДСП, то
Для дискретной величины 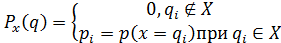

Для непрерывной величины 
Закон распределения Стьюдента случайной величины имеет вид(СтьюдРАСП-значение з-на распределения):
 ,
,
Г- гамма функция Эйлера, m- число степеней своб.
Пусть имеется выборка наблюденных в n+1 независимых испытаниях значений стандартной нормально распределенной случайной переменной x (т.е. x  N(0;1)): (x1, х2,…,хn, хn+1)
N(0;1)): (x1, х2,…,хn, хn+1)
Для расчёта tкрит используем ф-цию – дробь Стьюдента с n степенями свободы.

Этот закон позволяет нам при любом фиксированном числе 1-α из интервала (0, 1) вычислить величину t1-α – двустороннюю (1-α)-квантиль распределения Стьюдента с числом свободы n (к-т Стьюдента tкрит). Величину t1-α можно рассчитать в Excel по аргументам α, n при помощи функции СТЬЮДРАСПОБР.
10. Ковариация Cov(x, y), и коэффициент корреляции, Cor(x, y) пары случайных переменных (x, y). Частная ковариация и частный коэффициент корреляции.
Экономические переменные объекта (случайные или детерминированные), как правило, являются зависимыми величинами. Ковариации и коэффициент корреляции служат мерилами такой зависимости. Так, если (x, y) – пара случайных переменных (СП), то их ковариацией называется константа Cxy :
Cxy = Cov(x, y) = E(x · y) – E(x) · E(y). (1)
Из формулы (1) видно, что для вычисления Cxy нужно знать закон распределения Pxy (q, r) пары (x, y). Если он неизвестен, что и бывает на практике, то ковариацию можно оценить по выборке из генеральной совокупности Xx,y:
{(x1, y1), (x2, y2),... (xn, yn)}, (2)
Оценкой ковариации служит величина
 (3)
(3)
именуемая выборочной ковариацией. Каждая пара в выборке (2) имеет один и тот же закон распределения, Pxy (q, r); компонеты двух различных пар, например, (x1, y1) и (x2, y2) являются независимыми случайными переменными. Добавим, что случайные переменные (xi, xj) из выборки (2) обладают одинаковыми количественными характеристиками; аналогично, случайные переменных (yi,yj) имеют одинаковые количественные характеристики.
Оценка (3) совершеннее оценки (4) в том смысле, что она обладает свойством несмещённости,
 (4)
(4)
отсутствующим у оценки, которая, в силу данного обстоятельства, является смещённой оценкой ковариации.
Наконец, отметим, что физическая размерность Cxy равна произведению физических размерностей СП x и y. Но часто удобно использовать безразмерную (нормированную) ковариацию rxy ,
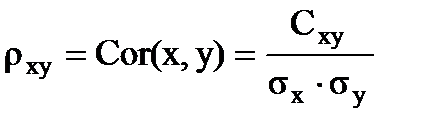 ,
,
которая именуется коэффициентом корреляции. Замечательно, что всегда
–1 £ rxy £ +1,
причём если |rxy | = 1, то y = a0 + a1 · x. Так что при |rxy | = 1 между переменными (x, y) существует функциональная (жесткая) линейная зависимость. Если же 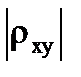 = 0, то связь между переменными x и y либо вообще отсутствует, либо же имеет место функциональная (жесткая), но нелинейная зависимость.
= 0, то связь между переменными x и y либо вообще отсутствует, либо же имеет место функциональная (жесткая), но нелинейная зависимость.
Свойства
1. Операции ковариации и корреляции симметричны относительно своих аргументов;
2. Ковариация и корреляция между независимыми переменными равны 0;
3. 

4.  ;
;
5.  ;
;
6. 
7. 
11. Случайная переменная и закон её распределения. Закон распределения Фишера. Квантиль, F крит уровня  и её расчёт в Excel.
и её расчёт в Excel.
Опр1. Случайной называют переменную которая в результате испытания примет одно и только одно возможное значение, наперед не известное и зависящее от случайных причин, которые невозможно заранее учесть.
Опр2. Переменная x с областью изменения X называется случайной, если свои возможные значения q из множества X переменная x принимает в результате некоторого опыта со случайными элементарными исходами вида .
Закон распределения – функция скалярного аргумента q, определенная на всей числовой прямой, характеризующую объективную возможность появления в опыте значений q случайной переменной x.
Полной характеристикой СП служит её дифференциальный закон распределения (ЗР). Так называется функция скалярного аргумента q, определённая на всей числовой прямой, характеризующая объективную возможность появления в опыте значений СП x. Если x – ДСП, то
Для дискретной величины
Случайная переменная (СП) x именуется дискретной (ДСП), если множество X состоит из конечного или счётного количества констант qi, то есть
X = {q1, q2,..., qn }.
Для непрерывной величины
Если X есть некоторый интервал числовой прямой, конечный или бесконечный, то есть
X = (a, b), то СП x называется непрерывной (НСП).

