




Математическая модель ИС может быть сформулирована аналитически (т. е. выведенная из законов физики и химии так называемая физическая или физико-химическая модель) либо экспериментально; в последнем случае ИС рассматривается как черный ящик — это так называемая статистическая модель.
Точность физической модели могут определять:
а) независимые переменные, то есть аргументы функции
F (x1,…xm-1,xm,T,a1,…,ak,z);
б) коэффициенты  функции F, вид которой задан;
функции F, вид которой задан;
в) значения коэффициентов.
Пункт (в) практически исключает задачу формулирования модели; в этом случае модель может быть подвергнута лишь проверке с точки зрения каких-либо специальных требований, но это не является проблемой идентификации.
Идентификация математических моделей — это обширное поле деятельности теории управления. Знание физических явлений и свойств элементов перед их применением для построения ИС играет в метрологии значительно более важную роль; поэтому ряд методов идентификации, присущих пункту (а), здесь не применяется. И цель идентификации, и требуемая высокая точность ее обусловили то, что для метрологии в целом характерны специфичные подходы, и из общих методов для нее приемлемы лишь некоторые. Так, использование статистического метода планирования эксперимента весьма незначительно. Во многих случаях требования точности при идентификации модели для нужд метрологии соответствуют специальным исследованиям в области физики. Примером могут служить исследования эффекта Джозефсона с целью использования этого явления для определения эталона напряжения.
Определение независимых переменных модели
Этот этап отсутствует при определении характеристик, о чем говорилось выше, но он появляется при исследовании источников погрешностей в процессе разработки аппаратуры. Если невозможно построить физическую модель, то нужно применить экспериментальные методы. Сначала выдвигается гипотеза, что данный конструктивный параметр (данное явление, величина и т. п.) является источником погрешности, а затем проводится направленный эксперимент, результаты которого подтверждают либо отвергают принятую гипотезу.
Для крупных объектов (в науке, промышленности, экономике) эксперимент очень дорог либо вообще невозможен; тогда используются различные эвристические методы, ограничивающие диапазон эксперимента, например дельфийский метод, метод образцов и т. д.
Общая черта этих методов — эвристический подход, причем для объективизации результатов используются различные формальные процедуры, уменьшающие вероятность получения ошибочной оценки. Однако эти процедуры дают все же не объективный результат, а лишь лучшим образом выбранное направление дальнейших поисков.
Корреляционный анализ
Для исследования взаимосвязей между случайными переменными используется функция взаимной корреляции. Нормированная функция взаимной корреляции переменных U и V, реализация которых во времени непрерывна, u(t), v(t), t  T, описывается выражением
T, описывается выражением
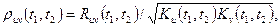 (3.103)
(3.103)
где
 (3.104)
(3.104)
— функция взаимной корреляции, а
 (3.105)
(3.105)
и соответственно  — функции корреляции переменных U, V. Для случайных переменных, стационарных в узком смысле, функция корреляции зависит только от интервала между аргументами
— функции корреляции переменных U, V. Для случайных переменных, стационарных в узком смысле, функция корреляции зависит только от интервала между аргументами 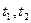 , т. е. от
, т. е. от  , следовательно,
, следовательно,
 (3.106)
(3.106)
Нормированная функция взаимной корреляции принимает значения от —1 до +1. Если переменные независимы, то для них  . Однако в общем случае свойство означает, что между переменными U, V нет корреляции (это не равнозначно их независимости). Лишь для нормальных распределений отсутствие корреляции означает независимость случайных переменных. Значение
. Однако в общем случае свойство означает, что между переменными U, V нет корреляции (это не равнозначно их независимости). Лишь для нормальных распределений отсутствие корреляции означает независимость случайных переменных. Значение  = ± 1 указывает на то, что между переменными существует линейная связь, а именно:
= ± 1 указывает на то, что между переменными существует линейная связь, а именно:
если  то U = kV + a, (3.107a)
то U = kV + a, (3.107a)
если  то U(t +
то U(t +  )=kV(t)+a, (3.107б)
)=kV(t)+a, (3.107б)
где k, a = const. Если ρ = 1, то k > 0; ρ = - 1 означает, что k < 0.
Значение нормированной корреляционной функции указывает на степень и характер зависимости; пусть, например,
V = U + Z, (3.108)
где Z — независимая случайная переменная со свойствами белого шума, E(Z)=0, E(Z—Z)2 =σ z2; тогда после подстановки (3.108) в формулу (3.104) получаем выражение
 (3.109)
(3.109)
и соответственно выражение для коэффициента корреляции
 (3.110)
(3.110)
Чем больше доля случайной составляющей в зависимости V=f(U), характеризуемой случайной переменной Z, тем коэффициент корреляции меньше 1. Мерой пропорции здесь является отношение дисперсий. Если случайная составляющая значительно превышает изменения переменной U, то 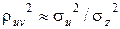 , т. е. коэффициент корреляции уменьшается до нуля.
, т. е. коэффициент корреляции уменьшается до нуля.
Зная распределение, можно вычислить доверительный интервал коэффициента R, вычисленного по результатам пробных измерений. Однако удобнее использовать распределение Стьюдента с п— 2 степенями свободы, которое получается после замены переменной R на t:
 (3.111)
(3.111)
По таблицам этого распределения можно оценить, как число элементов пробного измерения (при ρ = 0) влияет на доверительный уровень значения R, вычисленного из пробы. Если результат определения R(n) приходится на область р<0,5, то предположение, что ρ = 0, более вероятно, чем противоположное. Чтобы результат определения R из эксперимента был достаточно надежным в статистическом смысле, количество измерений должно быть достаточно большим.
Регрессионный анализ
Метод регрессии позволяет построить количественную модель на основе экспериментальных исследований. Данные для построения модели в случае двух переменных имеют форму соответствующих им множеств переменных X и Y, а именно {X, Y}, элементами которых являются 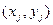 при j = 1,..., k. Обычно из теоретического анализа известно, какая из переменных независима (входная величина), а какая зависима (выходная). Применительно к модели ИС об этом говорят сами обозначения X, У.
при j = 1,..., k. Обычно из теоретического анализа известно, какая из переменных независима (входная величина), а какая зависима (выходная). Применительно к модели ИС об этом говорят сами обозначения X, У.
Регрессионной моделью называется связь между условным значением математического ожидания зависимой переменной и независимой переменной, а именно:
 . (3.112)
. (3.112)
Это регрессия переменной Y относительно переменной X, т. е. регрессия первого рода.
Определение условного математического ожидания у = m (х) может производиться последовательно для каждой точки, если значения  (j =1,.., k)многократно реализованы. На основании оценок
(j =1,.., k)многократно реализованы. На основании оценок  для каждой точки получается множество точек
для каждой точки получается множество точек  , а не функциональная зависимость. В определенных случаях за точку можно принимать небольшой интервал и вычислять в этом интервале среднее значение (это так называемая задача точечной оценки). Для отдельных точек зависимости
, а не функциональная зависимость. В определенных случаях за точку можно принимать небольшой интервал и вычислять в этом интервале среднее значение (это так называемая задача точечной оценки). Для отдельных точек зависимости 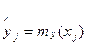 можно также определить доверительные интервалы и погрешности оценки. Функциональную зависимость можно установить в том случае, когда существуют данные теоретического характера, например двумерное распределение вероятностей р (х,у),но тогда экспериментальные данные излишни.
можно также определить доверительные интервалы и погрешности оценки. Функциональную зависимость можно установить в том случае, когда существуют данные теоретического характера, например двумерное распределение вероятностей р (х,у),но тогда экспериментальные данные излишни.
Задача определения модели регрессионным методом, так называемой регрессии второго рода, формулируется несколько иначе. Исходными данными при этом служат результаты экспериментов , j =1,..., k,и отыскивается модель линейного вида — так называемая линейная регрессия, например
 , (3.113)
, (3.113)
либо нелинейного вида — нелинейная регрессия, например
 , (3.114)
, (3.114)
f(x) = W  (x) = b0 + bl x+... +b x
(x) = b0 + bl x+... +b x  . (3.115)
. (3.115)
Считается, что модель известна с точностью до коэффициентов, а также до случайной составляющей ε, охватывающей все погрешности модели. Принимается, что Е (ε) = 0.
Определенная таким образом модель должна удовлетворять условию
 (3.116)
(3.116)
которое и дало название метод наименьших квадратов (МНК). Требованию минимального удаления точек от кривой регрессии соответствуют оценки  коэффициентов модели α, β либо общей модели (3.115). Способ построения модели будет проиллюстрирован на примерах; систематизированное изложение метода можно найти в справочниках по математической статистике.
коэффициентов модели α, β либо общей модели (3.115). Способ построения модели будет проиллюстрирован на примерах; систематизированное изложение метода можно найти в справочниках по математической статистике.
Пример регрессионного метода. Идентифицируется модель ИС для измерения содержания углерода в ванне кислородного конвертера для выплавки стали.
Содержание углерода X как измеряемая координата состояния объекта определяется путем измерения скорости обезуглероживания Y (потоков углерода, отводимых в виде газообразных продуктов сгорания) и нахождения по ней величины X. Полученные экспериментально зависимости представлены на рис. 3.18. Каждая из кривых представляет собой характеристику одной плавки, а данные, соответствующие одной кривой, сильно скоррелированы. В качестве независимых результатов можно принимать лишь точки, относящиеся к разным плавкам. Результаты измерений модели ИС могут быть представлены так, как это показано на рис. 3.19,а,б. В первом случае значения независимой переменной одинаковы, во втором - разные. Используя метод регрессии первого рода, получают точечные оценки регрессии, как это показано на рис. 3.19, в. Если значения независимой переменной различны (как на рис. 3.19, б), то область X делится на интервалы и отыскиваются точечные оценки, как это показано на рис. 3.19, г, для центрального значения интервала либо для средней точки в интервале. При идентификации модели ИС для измерения содержания углерода в ванне конвертера получены точечные оценки регрессии первого рода, показанные на рис. 3.20.

Рис. 3.18. Экспериментальные характеристики конвертерной выплавки стали.
С — содержание углерода в ванне; Vω — скорость обезуглероживания
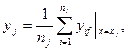 (3.117)
(3.117)
Результат не определяет функцию. В тех же самых точках независимой переменной можно определить доверительный интервал оценки на основе пробного эксперимента. Оценка дисперсии составляет
 (3.118)
(3.118)
а доверительный интервал при заданном доверительном уровне равен
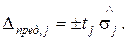 (3.119)
(3.119)
Значение t зависит от распределения 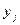 . Методом регрессии первого рода нельзя получить модель ИС в аналитической форме. Кроме того, доверительный интервал определяется по точкам, и для получения достаточной точности каждого значения число измерений п
. Методом регрессии первого рода нельзя получить модель ИС в аналитической форме. Кроме того, доверительный интервал определяется по точкам, и для получения достаточной точности каждого значения число измерений п  должно быть значительным. В многомерных моделях число измерений растет в пропорции
должно быть значительным. В многомерных моделях число измерений растет в пропорции  , где п — число повторений в данной точке х , n
, где п — число повторений в данной точке х , n  — число точек в области каждой из независимых переменных, N — число независимых переменных (N+1 —размерность модели).
— число точек в области каждой из независимых переменных, N — число независимых переменных (N+1 —размерность модели).
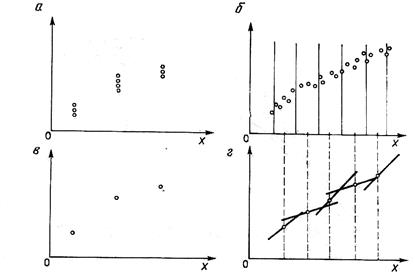
Рис. 3.19. Подбор точек измерения в методе регрессии первого рода

Рис. 3.20. Результаты регрессии первого рода характеристики системы для измерения содержания углерода в ванне конвертера.  - скорость обезуглероживания;
- скорость обезуглероживания; 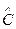 - оценка содержания углерода в ванне
- оценка содержания углерода в ванне
При малом числе точек получается низкая точность и вследствие этого — малая пригодность модели. Аналогичную форму модели удается получить по результатам анализа регрессии первого рода при использовании аппроксимации точек произвольным методом к произвольно выбранной функциональной зависимости. Так, для данных, представленных на рис. 3.19, в локальных пределах можно аппроксимировать результаты линейными зависимостями. Результат такой аппроксимации показан на рис. 3.19, г.
Из методов регрессии второго рода чаще всего используется метод наименьших квадратов, который имеет то свойство, что вычисленные оценки коэффициентов модели не смещены (не отягощены систематической погрешностью) и наиболее эффективны. В МНК постулируется форма модели
 , (3.120)
, (3.120)
где  - коэффициенты модели;
- коэффициенты модели; 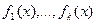 - произвольные однозначные функции аргумента x априори известного вида (здесь предполагается, что модель известна с точностью до коэффициентов); ε — случайный процесс, который моделируется стохастической (а не функциональной) зависимостью Y от X, описываемой моделью (3.120); реализации
- произвольные однозначные функции аргумента x априори известного вида (здесь предполагается, что модель известна с точностью до коэффициентов); ε — случайный процесс, который моделируется стохастической (а не функциональной) зависимостью Y от X, описываемой моделью (3.120); реализации 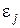 неизвестны, но имеют одинаковую дисперсию
неизвестны, но имеют одинаковую дисперсию 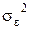 = const[14] и не коррелированы.
= const[14] и не коррелированы.
Линейная относительно коэффициентов форма модели соответствует линейной регрессии. Большое значение имеет предположение об известной до коэффициентов форме модели; при этом все отклонения рассматриваются как случайные погрешности. Существенно, что число степеней свободы, используемое для оценки случайных погрешностей, больше числа случайных переменных. В МНК далее постулируется, что модель (3.120) лучше всего описывает результаты экспериментов, когда погрешности в смысле квадратичной метрики имеют наименьшее значение, а именно:
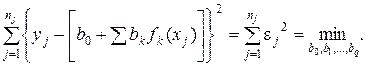 (3.121)
(3.121)
Этому условию должны удовлетворять оценки коэффициентов модели, т. е.  .
.
Возвращаясь к примеру ИС для измерения содержания углерода, отметим, что полученная там функциональная зависимость, которая проведена через точки, определенные в результате анализа регрессии первого рода, является нелинейной. На основе теоретического анализа постулируется модель
Y = 1 – exp [ -k (X-p)], (3.122)
в которой k,p = const — коэффициенты. Данные рис. 3.18 подтверждают эту зависимость. Для получения зависимости, линейной относительно коэффициентов, преобразуем модель (3.122) путем подстановки
U = - ln (1 - Y).
Тогда получается U = b0 + b1X + n
либо X*=a0+a1U+ e, (3.123)
если характеристикаφ (3.5) определяется как обратная функция модели f (3.10). Выше обозначено

B результате получаются значения
 для
для  (3.124a)
(3.124a)
 для
для  (3.124б)
(3.124б)
С целью проверки допущений исследована дисперсия погрешности ε для результатов анализа регрессии первого рода. Результат, показанный на рис. 3.21, свидетельствует о том, что полученные оценки коэффициентов модели не самые эффективные. Чтобы получить более эффективные оценки, необходимо преобразовать модель в форму, в которой дисперсия случайной составляющей e будет постоянна. Если в диапазоне измерений <  > дисперсия e изменяется согласно зависимости
> дисперсия e изменяется согласно зависимости
 (3.125)
(3.125)
причем
 (3.126)
(3.126)
то после подстановки
υ = y/g (x),  (3.127а, б)
(3.127а, б)
 (3.128а, б)
(3.128а, б)
вместо уравнения (3.120) получаем
 (3.129)
(3.129)

Рис. 3.21. Зависимость стандартного отклонения погрешности содержания углерода от измеряемой величины
Тогда условие  в точках оценки регрессии первого родa записывается так:
в точках оценки регрессии первого родa записывается так:
 (3.130)
(3.130)
где
 (3.131)
(3.131)
называется весом (весовым коэффициентом) данной точки.
Выражение (3.130) является условием метода взвешенных наименьших квадратов — сокращенно МВНК. Оценки коэффициентов модели ИС для измерения содержания углерода в ванне конвертера, полученные по МВНК, имеют другие значения в сравнении с результатами метода регрессии первого рода (3.124), а именно:
 для (3.132a)
для (3.132a)  для
для  (3.132б)
(3.132б)
При использовании регрессионного анализа необходима оценка того, является ли вычисленная функция регрессии адекватной результатам измерений. Кроме того, нужно определить доверительный интервал функции регрессии.

