




Пусть мы хотим построить линейную (относительно параметров) многофакторную модель от нескольких зависимых переменных. Общий тип линейной модели можно записать в виде:
 (1)
(1)
где X0 - фиктивная переменная, равная единице;
Xi (i=1,2,..., k) может быть некоторой функцией от переменной t или включать смешанные произведения, квадраты, различные другие комбинации или преобразования исходных факторов.
Анализ и построение будем вести в терминах матричной алгебры.
Условимся в обозначениях:
 - вектор наблюдений Y;
- вектор наблюдений Y;
 - матрица независимых переменных;
- матрица независимых переменных;
 - вектор параметров, подлежащих оцениванию;
- вектор параметров, подлежащих оцениванию;
 - вектор оценок вектора
- вектор оценок вектора  ;
;
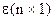 - вектор ошибок.
- вектор ошибок.
Оценку b вектора находят по методу наименьших квадратов, используя формулу:
b=(X1X)-1X1Y
Это решение обладает следующим свойством. Вектор b есть оценка , которая минимизирует сумму квадратов отклонений  1 безотносительно к тому, каков характер распределения ошибок, а элементы вектора b представляют собой несмещенные оценки элементов , обладающие минимальными дисперсиями среди любых линейных функций наблюдений, являющихся несмещенными оценками.
1 безотносительно к тому, каков характер распределения ошибок, а элементы вектора b представляют собой несмещенные оценки элементов , обладающие минимальными дисперсиями среди любых линейных функций наблюдений, являющихся несмещенными оценками.
Предсказываемые значения отклика получаются из уравнения  . Вектор остатков задается выражением
. Вектор остатков задается выражением 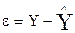 . Если модель содержит член
. Если модель содержит член  , то справедливо соотношение
, то справедливо соотношение  , где
, где  (i=1,2,..., n) - i-ый элемент вектора .
(i=1,2,..., n) - i-ый элемент вектора .
Основная таблица дисперсионного анализа уравнения регрессии может быть составлена следующим образом (Дрейпер, Смит, 1973, 1986):
| Источник | Сумма квадратов | Степень свободы | Средний квадрат |
| Регрессия | b1X1Y | p | MS2 |
| Остаток | Y1Y-b1X1Y | n-p | 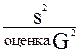 , если модель корректна , если модель корректна
|
| Общий | Y1Y | n | - |
Если в модели имеется коэффициент , то сумму квадратов (SS), обусловленную регрессией, можно разбить на слагаемые:
SS(b0)=n  2 ;
2 ;
SS( )=SS(
)=SS(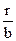 )=b1X1Y- n 2
)=b1X1Y- n 2
Эти суммы основаны на 1 и (p-1) степенях свободы соответственно.
Если имеются повторяющиеся наблюдения, то остаточную сумму квадратов можно разложить на две составляющие - SS (чистая ошибка), связанную с «чистой» ошибкой и имеющую nп степеней свободы, и SS (неадекватность) - сумму квадратов, связанную с неадекватностью и имеющую (n-p-nп) степеней свободы. Причем, при проведении повторяющихся опытов должны выдерживаться уровни всех независимых переменных X1,X2,...,Xk.
С учетом сделанных замечаний, таблица дисперсионного анализа имеет следующий вид:
| Источник | Сумма квадратов | Степень свободы | Средний квадрат |
| b0 | SS (b0) | - | |
|
| SS (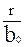 ) )
| p-1 | MS ()
|
| Неадекватность | SS (неадекватность) | n-p-nп | MS (неадекватность) |
| Чистая ошибка | S (чистая ошибка) | nп | MS (чистая ошибка) |
| Общий | Y1Y | n | - |
Отношение R2=  =
= 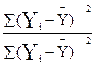 =
=  представляет собой квадрат множественного коэффициента корреляции (множественный коэффициент детерминации).
представляет собой квадрат множественного коэффициента корреляции (множественный коэффициент детерминации).
R2 есть мера полезности параметров  (bi) в регрессионной модели (i=1,2,...,p). Однако при добавлении новых слагаемых к модели необходимо быть уверенным, что увеличение R2 не связано с тем фактом, что число параметров в модели становится близким к числу наблюдений (состояние насыщения).
(bi) в регрессионной модели (i=1,2,...,p). Однако при добавлении новых слагаемых к модели необходимо быть уверенным, что увеличение R2 не связано с тем фактом, что число параметров в модели становится близким к числу наблюдений (состояние насыщения).
Если мы полагаем, что распределено нормально с нулевым математическим ожиданием и дисперсией, равной 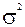 и что независимы друг от друга, то для исследования уравнения регрессии можно проделать следующее:
и что независимы друг от друга, то для исследования уравнения регрессии можно проделать следующее:
1. Найти вектор остатков, даваемый выражением e=  и исследовать их. Если модель содержит член , то справедливо соотношение
и исследовать их. Если модель содержит член , то справедливо соотношение  ;
;
2. По формуле D(b)=  -1 найти дисперсии и вариации оценок b (в качестве оценки
-1 найти дисперсии и вариации оценок b (в качестве оценки  используют S2);
используют S2);
3. Из уравнения  получить предсказываемое значение отклика. Причем, если
получить предсказываемое значение отклика. Причем, если 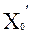 есть (1*p) - вектор, являющийся строкой матрицы X, то величина отклика
есть (1*p) - вектор, являющийся строкой матрицы X, то величина отклика 
 при X0, предсказываемая с помощью уравнения регрессии, имеет дисперсию:
при X0, предсказываемая с помощью уравнения регрессии, имеет дисперсию:

(1-L) - доверительные границы для средней величины Y при X0 и  получается по формуле
получается по формуле
 , где t - коэффициент Стьюдента, v=n-p;
, где t - коэффициент Стьюдента, v=n-p;
4. Осуществить проверку всего уравнения регрессии с помощью отношения средних квадратов

рассматриваемого как F(p-1,n-p) - распределенная величина (проверяется гипотеза H0:  ). Если дисперсионное отношение превосходит табличное значение F(p-1,n-p,1-L), где L - заданный уровень риска, то это означает, что получено статистически значимое уравнение регрессии. Чтобы полученное уравнение регрессии можно было считать удовлетворительным для целей предсказания, наблюдаемое значение F - отношение среднего квадрата, обусловленного регрессией, и остаточной дисперсией должно значительно превышать выбранную точку F- распределения.
). Если дисперсионное отношение превосходит табличное значение F(p-1,n-p,1-L), где L - заданный уровень риска, то это означает, что получено статистически значимое уравнение регрессии. Чтобы полученное уравнение регрессии можно было считать удовлетворительным для целей предсказания, наблюдаемое значение F - отношение среднего квадрата, обусловленного регрессией, и остаточной дисперсией должно значительно превышать выбранную точку F- распределения.
5. При наличии параллельных наблюдений провести проверку неадекватности модели путем рассмотрения отношения

как F[(n-p-nп), nп] - распределенной случайной величины и сравнения ее с F[(n-p-nп), nп, (1-L)]. Если нет рассогласования, то S2, равная  , есть несмещенная оценка .
, есть несмещенная оценка .
Для проверки значимости (статистической надежности) коэффициентов парной корреляции используют обычно t - критерий Стьюдента, рассчитываемый по формуле:

Полученное значение сопоставляется с табличным для выбранного уровня надежности (вероятности ошибки) при (n-r) степенях свободы (входной параметр таблиц).
Например, при r=0,896; n=20 получаем
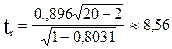
tтабл.=2,1 для 5% уровня надежности.
Испытание статистической надежности коэффициента множественной корреляции производится с помощью F- критерия. При этом проверяется гипотеза об отсутствии в генеральной совокупности связи между функцией и совокупностью учтенных факторов аргументов, т.е. в том, что в действительности  .
.

Доказано, что если располагая ограниченным числом наблюдений, постепенно расширять совокупность переменных, учитываемых в уравнении регрессии, коэффициент множественной корреляции будет возрастать, но теоретическая линия регрессии станет воспроизводить все случайные зигзаги эмпирической линии (корреляционной поверхности). Поэтому действительная теснота связи между функцией и учитываемыми аргументами по мере приближения n к  все сильнее преувеличивается. Считается, что этого можно избежать при следующем примерном условии
все сильнее преувеличивается. Считается, что этого можно избежать при следующем примерном условии

В противном случае необходима коррекция коэффициента корреляции. Эта коррекция выполняется по формуле:
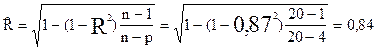 ,
,
где  - откорректированное значение R.
- откорректированное значение R.
Найти откорректированное значение коэффициента множественной корреляции, если n=20; R=4; Rрасч.=0,87.
[R=0,84]
Для оценки значимости и проверки полезности включения в модель того или иного фактора используют несколько критериев. Например, если наблюдается значительный рост R2 при добавлении Xi в уравнение регрессии, то подобранное уравнение более полно объясняет вариацию в данных. Остаточный средний квадрат есть оценка дисперсии относительно регрессии. Поэтому, чем меньше S2, тем более точными будут предсказания.
Должна уменьшаться и оценка стандартной ошибки в процентах от среднего отклика, т.е. можно считать, что включение Xi уменьшает стандартную ошибку оценки до величины порядка 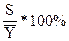 среднего отклика. Можно также рассмотреть дополнительную долю суммы квадратов, порожденную регрессией, которая связана с включением в модель данного члена Xi. Средний квадрат, который получается из этой дополнительной суммы, может быть затем сопоставлен с оценкой S2 параметра , для определения значимости различия между ними. Если средний квадрат значимо превышает оценку S2, то рассматриваемый член следует включить в модель. Если же этого нет, то его можно считать излишним и исключить из модели. Сопоставление средних квадратов с величиной S2 производится с помощью F- критерия. При более общих подходах дополнительная сумма квадратов вычисляется исходя из остаточных сумм квадратов, а не из сумм квадратов, обусловленных регрессией.
среднего отклика. Можно также рассмотреть дополнительную долю суммы квадратов, порожденную регрессией, которая связана с включением в модель данного члена Xi. Средний квадрат, который получается из этой дополнительной суммы, может быть затем сопоставлен с оценкой S2 параметра , для определения значимости различия между ними. Если средний квадрат значимо превышает оценку S2, то рассматриваемый член следует включить в модель. Если же этого нет, то его можно считать излишним и исключить из модели. Сопоставление средних квадратов с величиной S2 производится с помощью F- критерия. При более общих подходах дополнительная сумма квадратов вычисляется исходя из остаточных сумм квадратов, а не из сумм квадратов, обусловленных регрессией.
Метод всех возможных регрессий.
Пусть необходимо установить, какие независимые переменные являются наиболее важными. Решать задачу будем используя метод, требующий получения каждого и всех возможных регрессионных уравнений (метод всех возможных регрессий). В общем случае необходимо исследовать 2 k уравнений (где k - число независимых переменных). Регрессионные уравнения подразделяются на серии, каждая из которых содержит m переменных (m=1,2,...,k). В качестве критерия, в соответствии с которым упорядочиваются варианты внутри серий, принимается величина R2. После сравнения вариантов принимается решение о том, какие независимые переменные Xi лучше всего использовать.
Если используется более пяти переменных, то существенно возрастают затраты машинного времени и общая трудоемкость решения задачи в связи с трудностями исследования всех результатов вычисления, выданных на печать. Поэтому, при рассмотрении метода ограничимся серией, состоящей из всех трехфакторных уравнений.
Данные в нижеследующей таблице относятся к исследованию показателей качества работы зерноуборочных комбайнов. Здесь Xi - урожайность, число оборотов молотильного барабана, влажность зерна и т.д.; Y1 и Y2 - показатели, характеризующие качество работы комбайна.
В результате расчетов получим три серии уравнений. В первой серии содержится семь однофакторных уравнений
| Y1 | Y2 | X1 | X2 | X3 | X4 | X5 | X6 | X7 |
| 0,08 | 2,6 | 18,8 | 47,3 | 40,3 | ||||
| 0,34 | 16,6 | 3,2 | 20,6 | 47,3 | 49,1 | |||
| 1,08 | 17,5 | 3,8 | 21,4 | 47,3 | 45,8 | |||
| 2,3 | 0,33 | 3,1 | 14,2 | 36,8 | 40,9 | |||
| 1,62 | 1,56 | 3,2 | 12,2 | 36,8 | 32,1 | |||
| 3,5 | 4,56 | 3,6 | 16,9 | 39,1 | 38,1 | |||
| 4,4 | 7,9 | 4,4 | 16,9 | 39,1 | 38,1 | |||
| 5,2 | 8,38 | 5,2 | 16,9 | 39,1 | 38,1 | |||
| 0,49 | 17,8 | 2,5 | 20,8 | 47,3 | 39,9 |
(модель  ), во второй - все двухфакторные уравнения (модель
), во второй - все двухфакторные уравнения (модель  ), в третьей - все трехфакторные уравнения.
), в третьей - все трехфакторные уравнения.
| Сумма | квадратов | |||
| № включаемых переменных | R2 | F- критерий | обусловленная регрессией W (нескорректированная) | Остаток H |
| 0,73 | 19,5 | 60,72 | 7,36 | |
| 0,1 | 0,79 | 43,0 | 25,08 | |
| 0,17 | 1,5 | 45,1 | 22,97 | |
| … | … | … | … | … |
| … | … | … | … | … |
| 0,881 | 12,397 | 64,78 | 3,31 | |
| 0,978 | 74,48 | 67,81 | 0,11 | |
| 0,984 | 107,41 | 67,6 | 0,42 | |
| 0,896 | 14,39 | 65,19 | 2,89 | |
| 0,979 | 78,897 | 67,51 | 0,57 | |
| 0,899 | 14,961 | 65,28 | 2,80 | |
| 0,852 | 9,690 | 63,99 | 4,10 | |
| и т.д. |
Руководствуясь величиной R2, упорядочим варианты внутри серий и включим лидеров в нижеследующую таблицу.
| Серия | Переменные и уравнения | R2 | F |


| 0,736 0,908 | 19,5 69,4 | |

| 0,978 0,932 | 133,4 41,3 | |


| 0,985 0,979 | 107,4 78,9 |
Полученные результаты показывают, что после введения двух переменных дальнейший прирост величины R2 мал. Однако нет однозначного статистического метода для определения, какое уравнение (с какими переменными) является лучшим. Исследование всех возможных уравнений не дает четкого ответа на этот вопрос. Оптимальное число переменных в уравнении регрессии можно иногда установить (если подучены все регрессионные уравнения), рассмотрев зависимость величины остаточного среднего квадрата от числа переменных.
В данном случае можно ограничиться двумя переменными. По-видимому, следует выбрать  из серии 2, поскольку наилучшее однофакторное уравнение включает х7 и прирост R2 при переходе от серии 2 к серии 3 мал. В общем случае, однако, график не позволяет составить определенный набор из заданного числа переменных и не гарантирует того, что не существует лучшего набора с меньшим числом переменных. Поэтому в каждом конкретном случае необходим глубокий содержательный анализ полученных уравнений. Так, для нашего случая включение х1 и х7 в модель оправдано и по той причине, что оба эти параметра (подача хлебной массы и зазор на выходе молотильного барабана) являются регулируемыми.
из серии 2, поскольку наилучшее однофакторное уравнение включает х7 и прирост R2 при переходе от серии 2 к серии 3 мал. В общем случае, однако, график не позволяет составить определенный набор из заданного числа переменных и не гарантирует того, что не существует лучшего набора с меньшим числом переменных. Поэтому в каждом конкретном случае необходим глубокий содержательный анализ полученных уравнений. Так, для нашего случая включение х1 и х7 в модель оправдано и по той причине, что оба эти параметра (подача хлебной массы и зазор на выходе молотильного барабана) являются регулируемыми.
Ступенчатый регрессионный метод. При использовании этого метода первоначально получают регрессионное уравнение для переменной Х, наиболее сильно коррелированной с Y. После этого находят остатки  и рассматривают их как значения нового отклика. На следующем этапе строится регрессионная зависимость нового отклика от одной из оставшихся переменных хk, которая более остальных коррелированна с этим новым откликом, и т.д. до любой желаемой стадии. Конечное регрессионное уравнение по данному методу может быть получено путем последовательных подстановок регрессионных уравнений от стадии к стадии до получения окончательного уравнения. Например, на первом этапе можно записать
и рассматривают их как значения нового отклика. На следующем этапе строится регрессионная зависимость нового отклика от одной из оставшихся переменных хk, которая более остальных коррелированна с этим новым откликом, и т.д. до любой желаемой стадии. Конечное регрессионное уравнение по данному методу может быть получено путем последовательных подстановок регрессионных уравнений от стадии к стадии до получения окончательного уравнения. Например, на первом этапе можно записать
 ,
,
на втором
 и т.д.
и т.д.
Следует, однако, помнить, что коэффициенты в регрессионном уравнении получаются в данном случае не по методу наименьших квадратов (МНК), т.е. этот метод не дает МНК- оценок коэффициентов уравнения и поэтому будет всегда менее точным. В то же время ступенчатый регрессионный метод позволяет вводить переменные таким образом, чтобы можно было сохранить ожидаемое направление действия любых эффектов (это обстоятельство особенно важно при решении некоторых задач: корректировка данных относительно тренда или сезонности и т.д.). Кроме того, выделив интересующие переменные ступенчатым регрессионным методом, можно затем перейти к построению и анализу уравнения регрессии с помощью метода наименьших квадратов.
Для иллюстрации метода мы вновь воспользуемся прежними исходными данными (для Y2).
Матрица корреляции между Y и Xi имеет вид (в дальнейшем будем обозначать просто Y):
 Х2 Х3 Х4 Х5 Х6
Х2 Х3 Х4 Х5 Х6
0,917 0,901 0,973 0,630 -0,982
0,945 0,876 0,635 -0,925
r(Y,Xi)= 0,914 0,784 -0,942
0,712 -0,993
-0,710
Построим регрессионное уравнение для Y в зависимости от Х6, поскольку наибольший коэффициент корреляции наблюдается именно между ними.
 и вычислим остатки
и вычислим остатки
 для каждого значения Х6.
для каждого значения Х6.

Воспользовавшись этими остатками как откликом, найдем коэффициенты корреляции между остающимися переменными и откликом
X2 X3 X4 X5
r(z1,x2,3,4,5)= 0.043-0.239-0.282-0.574
Вычисление коэффициента корреляции показало, что наиболее коррелированной с остатками переменной является Х5. Поэтому составим регрессионное уравнение, связывающее Z1i с Х5 (z1i=-2,2;1,14;1,62;-0,22;1,98;-1,42;-0,52;-0,8;0,43). Подобранное уравнение регрессии:

найдем теперь остатки  ;
; 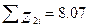 (z2i=1,39;0,33;0,81;-0,76;1,54;-0,15;-1,27;-1,31).
(z2i=1,39;0,33;0,81;-0,76;1,54;-0,15;-1,27;-1,31).
Коэффициенты корреляции между Z2i и оставшимися факторами имеют следующие значения:
X2 X3 X4
r(z2,Xi)= 0.499 0.258 0.154
На третьем этапе наиболее существенной переменной оказывается Х2. Для нее и построим регрессионную зависимость 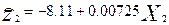 .
.
Вычислим новые остатки (z3i=1.39;0.33;0.81;-1,2;1,1;-0,98;-0,59;-0,4;-0,44) и для определения очередной существенной переменной найдем коэффициенты корреляции z(z3,Xi)
r(z3,Xi)=(-0,246-0,323) и т.д.
Использование ступенчатого регрессионного метода позволило нам выделить наиболее существенные переменные для включения в математическую модель.
Исследование остатков в процессе выделения значимых факторов методами регрессионного анализа позволяют оценить правомерность сделанных предположений относительно независимости и нормальности распределения ошибок.
Замечание. Первоначальное изучение влияния различных факторов на протекание какого-либо явления, процесса начинают обычно с вычисления корреляционной матрицы (матрицы корреляции) между независимыми переменными и откликом. При этом, если исследователя интересует возможность предсказания значений, например, переменной Х1 по Х2, …, Хn , то трудно устоять перед соблазном вычислять вначале только корреляции между Х1 и остальными переменными и отбросить те из переменных, коэффициенты корреляции с которыми равны нулю или очень малы. Это, возможно, позволило бы уменьшить число переменных, включаемых в математическую модель. Однако, такая процедура может привести к неверным результатам, поскольку, если одна величина коррелированна с другой, то это возможно является отражением всего лишь того факта, что обе они коррелированны с некоторой третьей величиной или с совокупностью величин. Очевидно, что матрица корреляций определяет всю совокупность частных корреляций. Но малость коэффициентов корреляции нулевого порядка между Х1 и другими переменными не гарантирует малости коэффициентов более высокого порядка (напомним, что если имеется n величин Х1, …, Хn, то мы можем изучать корреляцию между любыми двумя из них, когда среди оставшихся зафиксированы значения произвольного подмножества величин. Если, например, при исследовании трех величин Х1, Х2, Х3 рассматривается корреляция между Х1 и Х2 при фиксированном значении Х3, то соответствующий коэффициент корреляции записывают как r12.3 и говорят, что он имеет порядок, равный единице, т.е. порядок определяется числом переменных, значения которых фиксируются. А так как множественный коэффициент корреляции должен быть не меньше наибольшей из корреляций любого порядка, то с помощью описанной выше процедуры мы можем отбросить ценную информацию.
Так, для трех переменных, например, может оказаться, что и r12, и r13 очень малы, а r12.3 велик. Действительно, предположим, что r12=0,1; r13=0; r23=0,996. Тогда r12.3, вычисляемый по формуле 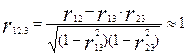 .
.
Поскольку множественный коэффициент корреляции R1(2,3)≥│r12.3│, то в данном случае R1(2,3)=1, т.е. Х1 является точной линейной функцией от Х2 и Х3, несмотря на вышеуказанные значения коэффициентов корреляции нулевого порядка. Показателен в этом отношении и пример, приведенный для иллюстрации ступенчатого регрессионного метода. Так переменная Х4 была одним из наиболее вероятных претендентов на включение в регрессионное уравнение (ryx4=0,973). Однако, после того, как переменную Х6 включили в модель, оказалось, что влияние Х4 на Y совсем невелико (ryx4x6=-0,282).
После того, как выделены значимые факторы и по каждому из них собрана необходимая информация, приступают к построению математической модели, формально описывающей исследуемый процесс. Это означает, что должен быть выбран вид зависимости (1) и оценены коэффициенты bi.
Если матрица исходных данных получена по результатам спланированного (активного) эксперимента, то общий вид модели постулировался еще при составлении плана эксперимента, а получение оценок для коэффициентов модели обычно (при ортогональной матрице планирования) связано с выполнением простейших арифметических операций. Методы оптимального управления процессом на основании построенной по результатам активного эксперимента модели достаточно подробно описаны в литературе.
Специфические особенности имеет процесс построения математической модели объекта по данным активного эксперимента, полученным на действующем объекте. В этом случае для получения информации о процессе необходимо постоянно осуществлять небольшие вариации факторов, влияющих на критерий оптимизации. А так как эти вариации на действующем объекте обычно возможны лишь в ограниченных пределах, то для выполнения эффекта изменения переменных нужно многократно повторять одни и те же опыты; полученная информация должна вновь использоваться для воздействия на процесс с целью его улучшения и т.д., т.е. производство должно работать в условиях «обратной связи».
Таким образом, будет происходить непрерывное приспособление производства к изменяющимся условиям его функционирования, самосовершенствование системы. Такая методология системы называется эволюционным планированием (ЭВОП).
Эволюционное планирование сочетает экспериментирование на объекте с управлением последним при наличии обратной связи. Различают два типа обратной связи – научную (или техническую) и эмпирическую. Если при принятии решения о корректировке процесса используются не только те сведения, которые получены в результате предшествующей вариации условий, но и привлекаются новые научно-технические идеи, то такую обратную связь называют научной или технической. Научная обратная связь имеет глубокий характер. Интерпретация полученных результатов и выработка решений, направляемых на улучшение процесса, проводится с участием высококвалифицированных специалистов различных направлений.
Если информация, используемая при принятии решений, базируется только на сведениях, полученных при вариации процесса, то обратную связь называют эмпирической. Эмпирическая обратная связь может носить ограниченный характер: она проводится по определенным формализованным правилам и касается, в основном, изменения уровней варьируемых факторов. Для ее реализации, как правило, не требуется специалистов высокой квалификации. Управление объектом здесь может быть передано управляющим машинам.
В настоящее время известен и применяется ряд методов эволюционного планирования: метод Бокса, вращаемое квадратичное ЭВОП, случайное ЭВОП, симплекс-ЭВОП или последовательный симплексный метод.
Первые три метода формализованы недостаточно полно и не содержат строгих рекомендаций, когда и как надо менять факторы, влияющие на процесс. Здесь предполагается управление процессом с научной обратной связью, т.е. с привлечением мнений квалифицированных специалистов. Последний метод (симплекс-ЭВОП) формализован значительно больше. В этом случае оказывается возможным управление с эмпирической обратной связью.
Несмотря на большие преимущества активного эксперимента, осуществить его в реальных производственных условиях удается далеко не всегда. Поэтому Сиськовым (1971) предлагается при определении оптимальных значений параметров производственного процесса, обеспечивающих повышение потребительского качества продукции, использовать методы активного эксперимента на основе информации, получаемой для установления корреляционной зависимости. В этом случае для построения математических моделей применяют факторное планирование эксперимента.
Математическое описание объекта в окрестности точки базового режима Х=(Х1, Х2, Х3, …, Хn) может быть получен варьированием каждого из факторов Хi на двух уровнях Хib и Xin, отличающихся от базового уровня Х10 на величину шага варьирования ±ΔXi.
При планировании эксперимента проводят преобразования независимых переменных путем их приведения к безразмерным переменным Di. Это преобразование проводится по формуле  .
.
Такое преобразование дает возможность построить ортогональную матрицу планирования и значительно облегчает дальнейшие расчеты, так как в этом случае верхние и нижние уровни варьирования Хib и Хin в относительных единицах составляют Хib=1 и Хin=-1. При этом исходят из известных общих предпосылок, на которых базируется регрессионный анализ.
Исходная матрица наблюдений преобразуется в следующей последовательности.
- для каждого из факторов определяют уровни варьирования, например, нижний, средний (базовый) и верхний;
- среднему уровню (Хi0) соответствует средняя величина (Хi);
- за шаг варьирования принимается среднее линейное отклонение di, определяемое по формуле:
 , тогда нижний уровень составит Хi-di, верхний уровень будет равен Хi+di; определенные таким образом уровни варьирования факторов кодируются: нижний уровень – (-1), базовый уровень – (0) и верхний уровень – (+1);
, тогда нижний уровень составит Хi-di, верхний уровень будет равен Хi+di; определенные таким образом уровни варьирования факторов кодируются: нижний уровень – (-1), базовый уровень – (0) и верхний уровень – (+1);
- по выбранным уровням составляют матрицу планирования, в которой предусматривают все возможные сочетания уровней по различным факторам;
- планирование эксперимента состоит в выборе строк среди исходных данных, предназначенных для использования метода корреляции, соответствующих каждому сочетанию уровней факторов; отобранные строки с соответствующими значениями функции записывают в матрицу планирования эксперимента;
- так как каждый уровень фактора выражается конкретным значением фактора, а среди строк исходных данных такого значения может не оказаться, то целесообразно сами уровни факторов выражать определенными пределами варьирования:
 для нижнего уровня xi-1.5di
для нижнего уровня xi-1.5di
xi-0.5di;
для базового уровня xi-0.5di
xi+0.5di ;
для верхнего уровня xi+0.5di
xi+1.5di;
- пределы варьирования каждого уровня кодируются: для нижнего – (-1), для базового – (0), для верхнего – (+1);
- если значение фактора в исходных данных совпадает с одной из границ интервала, то это значение включают в тот интервал, для которого оно является верхней границей.
Используя простоту метода активного эксперимента в его применении к информации, получаемой для корреляционного анализа, можно хотя бы в первом приближении определить те области значений факторов, которые содержат оптимумы. Однако при этом следует учитывать, что искусственно загрубляя модель, мы можем потерять весьма ценную информацию и получить ложное представление о степени влияния того или иного фактора на функцию. Кроме того, может оказаться, что из преобразованной матрицы исходных данных вообще нельзя получить матрицу полного факторного эксперимента.
Построение математической модели на основании информации, собранной в результате пассивного (или активно-пассивного) эксперимента, может осуществляться с использованием уже рассмотренных ступенчатого регрессионного метода и метода всех возможных регрессий, а также шагового регрессионного метода и ряда других. По мнению Н. Дрейпера и Г. Смита (1986), которое представляется нам вполне обоснованным, последний является наиболее удачным из известных методов регрессионного анализа. Суть шагового регрессионного метода заключается в дополнительном исследовании на каждой стадии переменных, включенных в модель на предшествующих стадиях. Переменная, введенная ранее в модель, на более поздней стадии может оказаться несущественной из-за взаимосвязи между ней и другими переменными, содержащимися теперь в модели. Любая переменная, которая на данном шаге дает незначимый вклад, исключается из модели. Этот процесс продолжается до тех пор, пока уже никакая переменная не добавляется в уравнение и не исключается из него. Включение и исключение переменных в шаговом регрессионном методе происходит в результате последовательного (шаг за шагом) преобразования и анализа расширенной корреляционной матрицы
R T Y
A= T S O
-J O O,
где R (К×К) – корреляционная матрица для К независимых переменных, Т (1×К) – корреляционный вектор для К переменных с откликом Y, Т΄ (К×1) – транспонированный вектор Т, J (К×К) – единичная матрица.
Рассмотрим процедуру построения математической (регрессионной) модели с использованием шагового регрессионного метода.
Исходные данные представлены в таблице. Здесь Y – среднее значение микроповрежденности зерна при комбайновой уборке, Хi – число оборотов молотильного барабана, влажность зерна и другие факторы.
| Х1 | Х2 | X3 | X4 | X5 | X6 | Y |
| 1.00 | 0.8 | |||||
| 1.00 | 14.0 | |||||
| 1.15 | 6.0 | |||||
| 1.17 | 21.0 | |||||
| 1.03 | 10.0 | |||||
| 1.00 | 0.1 | |||||
| 1.10 | 22.0 | |||||
| 1.10 | 18.0 | |||||
| 1.10 | 20.0 | |||||
| 1.20 | 1.0 |
Матрица парных коэффициентов корреляции для представленных исходных данных имеет вид:
| |
| 1,00 | 0,70 | 0,78 | -0,41 | -0,71 | -0,18 | 0,37 |
| 1,00 | 0,37 | -0,43 | -0,79 | 0,17 | 0,68 | |
| 1,00 | 0,12 | -0,26 | -0,37 | -0,23 | ||
| 1,00 | 0,78 | -0,02 | -0,87 | |||
| 1,00 | 0,20 | -0,8 | ||||
| 1,00 | 0,23 | |||||
| 1,00 |
Расширим матрицу исходных данных так, что Х7=Х3/Х5, Х8=Х6×Х2, Х9=Х6/Х2, Х10=Х3/Х4. Условимся также, что для включения и исключения переменной будет использоваться одинаковое критическое значение F-критерия, равное 3,29. Такое соглашение дает возможность упростить процедуру сравнения опытных (получаемых в процессе построения уравнения) значений F-критерия с табличным.
| Шаг | F-критерий для включения/исключения(!) | Вклю-чаемая пере-менная | Доля объясненной вариации | Стандартное отклонение для остатков | Натураль-ный В-коэффици-ент | Свобод-ный член регрес-сионного уравне-ния В11 | Стандарт-ные ошибки В-коэффици-ентов |
| Х4 25,96 | Х4 | 76,4% | 4,5 | Для Х4= -7,046 | 38,77 | В4 1,38 | |
| Х8 8,36 | Х8 | 89,26% | 3,29 | Для Х4= -5,78 Для Х8= 0,68 | 22,3939 | В4 1,089 В8 0,236 | |
| !Х4 28,16 !Х8 8,36 Х10 31,05 | Х10 | 98,26% | 1,43 | Для Х4 -8,81 Для Х8 1,06 Для Х10 -1,64 | 46,0 | В4 0,72 В8 0,122 В10 0,29 | |
| !Х4 149,3 !Х8 74,3 !Х10 31,0 Х9 6,2 | Х9 | 99,2% | 1,08 | Для Х4 -9,15 Для Х8 0,76 Для Х9 -98,19 Для Х10 -1,80 | 61,51 | В4 0,554 В8 0,149 В9 39,24 В10 0,224 | |
| !Х4 283,3 !Х8 25,0 !Х9 6,2 !Х10 84,5 Х6 7,1 | Х6 | 99,7% | 0,699 | Для Х4 -8,68 Для Х6 61,75 Для Х8 -1,15 Для Х9 -502,33 Для Х10 -1,104 | 47,49 | В4 0,40 В6 23,07 В8 0,72 В9 153,2 В10 0,30 | |
| !Х4 459,7 !Х6 7,1 !Х8 2,5 !Х9 10,7 !Х10 13,3 Х3 3,05 | !Х8 Х3 | 99,54% | 0,80 | Для Х4 -8,95678 Для Х6 25,21208 Для Х9 -258,55664 Для Х10 -1,52176 | 55,07983 | В4 0,42034 В6 3,64723 В9 18,07390 В10 0,17355 |

