




При построении математических моделей приходится сталкиваться со случаями, когда на выходные характеристики объекта исследования действует множество различных факторов и анализ литературных источников на позволяет отобрать наиболее значимые из них. В этих условиях с помощью опроса специалистов можно оценить значимость фактора и установить на основе этих оценок, следует ли тому или иному фактору собирать информацию. Материалы анкетного опроса могут оказаться полезными и при определении очередности введения переменных в математическую модель.
Используя различные способы организации анкетного опроса. В одном случае каждому опрашиваемому специалисту предлагается назвать неограниченное количество факторов, влияющих на исследуемый показатель, и оценить степень их влияния. В другом случае исследователь заранее составляет перечень факторов, а задача эксперта заключается в их ранжировании. Обычно более широко используется второй из указанных способов, при этом специалистам предоставляется возможность проранжировать включенные в набор факторы, а также включать дополнительные факторы, оказывающие влияние, по мнению эксперта, на показатель.
Если число факторов относительно невелико (10 - 15), то каждому эксперту предлагают проранжировать факторы в соответствии со степенью их влияния на функцию (моделируемый показатель). Опросная анкета в этом случае может иметь вид:
Опросная анкета
| № п/п | Наименование факторов | Размерность факторов | Ранг |
| ... | |||
| n |
Фактору, который, по мнению данного специалиста, оказывает наибольшее влияние на изучаемый процесс, присваивает ранг 1, следующему - ранг 2 и т.д.
При большом числе ранжируемых факторов последние объединяются в группы, и эксперт сначала ранжирует группы факторов, а на следующем этапе определяет место отдельных факторов внутри группы.
Анализ данных анкетного опроса начинается с составления анкеты, так называемой матрицы рангов (таблица 1).
Матрица рангов
Таблица 1
 Факторы
Опрашиваемые Факторы
Опрашиваемые
| ... |
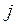
| ... | n | 
| |||
| x11 | x12 | x13 | ... | x1j | ... | x1n | ||
| x21 | x22 | x23 | ... | x2j | ... | x2n | ||
| x31 | x32 | x33 | ... | x3j | ... | x3n | ||
| ... | ||||||||
| ... | ||||||||
| ... | ||||||||
| i | xi1 | xi2 | xi3 | ... | xij | ... | xin | |
| ... | ||||||||
| ... | ||||||||
| ... | ||||||||
| m | xm1 | xm2 | xm3 | xmj | xmn | |||

|
В таблице 1 xij - ранг j - го фактора и i - го исследователя; m - число исследователей, n - число факторов.
Если специалисту не удается различить по силе влияния некоторые факторы, то он вынужден приписывать им один и тот же ранговый номер. В этом случае вводится так называемые «связанные ранги». Например, трем факторам в анкете i - го специалиста присвоен ранг 3. Их ранговый номер в сводной анкете равен:
 .
.
Если следующие два фактора в анкете i - го исследователя имели ранг 4 и 5, то в сводной анкете их ранг будет равен 6 и 7, т.е. происходит переформирование рангов.
Иногда в сводной анкете появляются дробные ранги. Например, если в анкете 8 и 9 фактору приписан ранг 8, то в сводной анкете их ранг будет 8,6. (Розанов, Френкель, 1969).
После заполнения сводной анкеты следует провести проверку. Для этого ищется контрольная сумма по строкам:
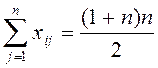 .
.
Далее вычисляется сумма всех строк. Они должны быть равны друг другу и одновременно контрольной сумме.
Когда есть уверенность, что матрица рангов составлена правильно, можно перейти к выявлению существенности влияния отобранных факторов на изучаемый показатель, с точки зрения опрошенных специалистов. Для этого в таблице 1 подсчитываются суммы всех отдельных столбцов. При этом:
 .
.
Фактор, который с точки зрения специалистов, оказывает наибольшее влияние на изучаемый показатель, имеет наименьшую сумму рангов, а фактор, оказывающий самое слабое влияние - наибольшую сумму рангов.
Для того, чтобы полнее использовать информацию, содержащуюся в анкетах, после сводки результатов переходят к статистической их обработке. Анкета обычно содержит два рода сведений: основные - ответ эксперта о порядке расположения факторов и вспомогательные - характеристики самого опрашиваемого (должность, образование, профессиональный стаж и т.п.). Статистический анализ предполагает использование обеих групп сведений. При этом необходимо учитывать специфические особенности полученной информации. Значение ранга не является количественной оценкой фактора, а представляет собой лишь измерение по шкале порядка. Кроме того, при заполнении анкеты эксперт решает не ряд одномерных задач о месте каждого фактора, а одну многомерную задачу об относительном расположении всех факторов набора. Результаты оценки места отдельных факторов взаимозависимы. Коллективное мнение о порядке следования факторов может быть обоснованно установлено только при достаточно хорошей согласованности ответов опрашиваемых специалистов. Поэтому обработка результатов анкетного опроса обязательно включает оценку степени согласованности мнений экспертов и выяснение причин неоднородности.
На первом этапе исследования проверяют адекватность таблиц начальных и переформированных рангов. Эта проверка осуществляется в связи с тем, что дальнейшая работа проводится на переформированных рангах. Поэтому необходима их адекватность. Причина неадекватности:
а) неоднозначное понимание специалистами каждого фактора;
б) выбраны недостаточно квалифицированные специалисты.
Предположим, что m = 15, n = 12.
Адекватность перехода от рангов начальной таблицы к таблице переформированных рангов проверяют по коэффициенту ранговой кореляции
 - Спирмена:
- Спирмена:
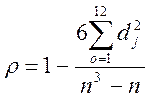 ,
,
где: 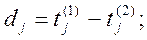
 - ранги фактора для первой и второй таблиц соответственно.
- ранги фактора для первой и второй таблиц соответственно.
Если коэффициент незначимо отличен от единицы, то это говорит о том, что матрица переформированных рангов адекватна матрице первоначальных рангов. Поэтому в дальнейшем с одинаковым правом можно использовать как первую, так и вторую таблицы, в зависимости от того, какая из них удобнее для применяемого в каждом конкретном случае метода. В случае, если значимо отличается от единицы, то это покажет, что при переформировании произошло изменение первоначальной информации, что совершенно недопустимо. Ранговый коэффициент кореляции может использоваться и в качестве меры близости ответов двух экспертов в случаях, когда используется строгая ранжировка факторов (число мест равно числу факторов). Он, по существу, является коэффициентом беспорядка.
Предположим, что ранги  расположены в натуральном порядке 1,2,..., n, и что соответствующие ранги
расположены в натуральном порядке 1,2,..., n, и что соответствующие ранги  образуют перестановку чисел 1,2,..., n. Естественный метод изменения беспорядка - рангов, т.е. отклонения от порядка 1,2,..., n, состоит в подсчете числа инверсий между ними. Например, при n = 4 в - ранжировке 3214 имеются три инверсии (3-2, 3-1, 2-1). Число таких инверсий, которое обозначается буквой V, может изменяться от 0 до 1/2 n(n-1), причем эти граничные значения достигаются на - ранжировках 1,2,..., n и n, (n-1),..., 1.
образуют перестановку чисел 1,2,..., n. Естественный метод изменения беспорядка - рангов, т.е. отклонения от порядка 1,2,..., n, состоит в подсчете числа инверсий между ними. Например, при n = 4 в - ранжировке 3214 имеются три инверсии (3-2, 3-1, 2-1). Число таких инверсий, которое обозначается буквой V, может изменяться от 0 до 1/2 n(n-1), причем эти граничные значения достигаются на - ранжировках 1,2,..., n и n, (n-1),..., 1.
Таким образом, мы приходим к коэффициенту.
 .
.
Распределение Т стремится к нормальному с нулевым средним и дисперсией:

Коэффициент и Т ассимптотически эквивалентны, коэффициент кореляции между ними убывает от 1 при n=2 до своего минимального значения 0,98 при n=5 и затем возрастает к 1 при  .
.
Степень согласованности ответов всех опрошенных специалистов оценивают по коэффициенту конкордации  . Для случая связанных рангов этот коэффициент вычисляется по формуле:
. Для случая связанных рангов этот коэффициент вычисляется по формуле:

где: 

где: t - число связанных рангов в каждой строке матрицы рангов.
Если мнения специалистов полностью совпадают, то коэффициент конкордации равен 1, если же они полностью не совпадают, то коэффициент равен 0. Значимость отличия от нуля можно проверить по  - критерию (Фишера).
- критерию (Фишера).
Получение статистически значимого коэффициента конкордации свидетельствует о неслучайном характере совпадения мнений специалистов, а его величина позволяет оценить степень этого совпадения.
Дальнейший анализ анкетных данных может производиться по методикам, описанным в (Розанов, Френкель, 1969; Розин, 1973, 1976).
Для получения обоснованного согласованного мнения группы экспертов относительно состава и степени значимости включаемых в рассмотрение факторов целесообразно1 использовать активно разрабатывающийся в настоящее время для целей прогнозирования будущего метод Дельфи. Потенциальные достоинства этого метода заключаются в предоставляемой специалистам возможности рассматривать возражения и предложения других членов экспертной группы в атмосфере, свободной от влияния личных качеств участников. С помощью метода Дельфи делается попытка эффективно использовать так называемое «информированное интуитивное суждение» специалиста-эксперта, путем совпадения таких условий, когда он сможет активно взаимодействовать с другими специалистами в этой области или в областях, касающихся прочих аспектов этой проблемы. При этом непосредственное общение специалистов друг с другом заменяется тщательно разработанной программой последовательных индивидуальных опросов, проводимых, как правило, с помощью анкет. Эти опросы чередуются с постоянным информированием специалистов о результатах предыдущего опроса. Весьма важно, что для проведения опросов с применением метода Дельфи могут быть использованы универсальные ЭВМ. Рассмотрим использование дельфийской процедуры для выделения факторов, существенно влияющих на показатели качества работы зерноуборочных комбайнов. Анализ литературных источников не позволил сделать однозначный отбор наиболее существенных факторов для первоначального включения в математическую модель и составления плана эксперимента. Учитывая значительную трудоемкость (не испытаниях 5 комбайнов бывает занято до 50 человек в день) и высокую стоимость проведения отсеивающих экспериментов, возможное влияние на функцию (показатели качества работы) большого числа природных факторов, что затрудняло постановку адекватных сравнительных экспериментов, был проведен анкетный опрос специалистов относительно состава и степени значимости факторов.
При отборе специалистов, помимо объективных характеристик (должность, стаж работы, образование и т.п.) учитывалась также даваемая ими оценка собственной компетентности по интересующему нас вопросу (по 10-бальной шкале).
После составления анкеты (см. Форма 1), в которой перечислялись все выявленные факторы, каждому из членов экспертной группы было предложено проранжировать факторы по степени значимости и ответить на вопрос, как сказывается изменение величины фактора на функции (увеличивает или уменьшает значение функции, в каких пределах изменения оказывают наиболее заметное влияние).
Затем производилась обработка результатов опроса (определялись и проставлялись в анкетах 2-го тура средний, максимальный и минимальный ранги факторов среди всех опрошенных), и экспертов просили пересмотреть и при желании исправить свои предыдущие ответы. Если новый ответ какого-либо эксперта значительно отличался от среднего ранга фактора (не попадал в интервал, расположенный между 25% самых «низких» и 25% самых «высоких» оценок), то этого специалиста просили объяснить причины отклонения его ответа мнения большинства, уточнить условия, при которых, по его мнению, влияние указанного фактора наиболее (наименее) значимо. Подобная система опросов давала возможность тем специалистам, у кого не было твердой уверенности, помещать свои ответы вблизи среднего значения ранга фактора.
Результаты обработки анкет второго тура вновь сообщались членам экспертной группы. Кроме того, им направлялся краткий перечень объяснений, представленных в защиту сильно отличающихся между собой ответов. Затем всех просили вновь провести ранжирование с учетом представленных объяснений причин отклонения мнения некоторых экспертов от мнения большинства. При этих условиях каждый эксперт независимо от направления его специализации (в экспертизе участвовали агрономы, инженеры и комбайнеры) вынужден был учитывать многие аспекты проблемы, на которые он мог бы не обратить внимания, если бы работал в одиночку.
Опросная анкета
Форма 1
| Тур Компетентность | |||||||
| № п/п | Наименование фактора | Размерность | Ранг фактора по степени влияния на величину показателя | Средний ранг фактора среди всех опрошенных | Минимальный ранг фактора среди всех опрошенных | Максимальный ранг фактора среди всех опрошенных | Примечание (в каком интервале изменения оказывают наибольшее влияние и в каком направлении - увеличивает или уменьшает значение функции) |
Как показали проведенные исследования, при использовании такого метода опроса наблюдалась сходимость мнений экспертов к относительно узкому интервалу значений см. табл. 2,3). В случае, если такой сходимости нет, то это может указывать на недостаточную изученность исследуемого явления, на наличие разных научных подходов к данному вопросу, различную интерпретацию данных и др.
Таким образом, применение метода Дельфи и возможных его модификаций оказывается весьма полезным на стадии априорного анализа объекта исследования. Однако, при этом возникает ряд проблем. Как объективно и количественно оценить степень сходимости мнения экспертов при проведении нескольких туров опросов? Как выделить отдельно группировки специалистов и, возможно, выявить причины образования таких группировок (специализация, место работы, стаж и т.п.)? На каком этапе следует прекратить дальнейшие опросы?
Хотя на некоторые из этих вопросов можно ответить, проведя анализ ранжирования методами ранговой кореляции, представляется более наглядным и удобным в смысле простоты вычислительных алгоритмов другое направление решения указанных задач.
Тур 1
Таблица 2
| Номер/ | Эксперты | Диапазон изменения | ||||||||
| наименование | ранга фактора | |||||||||
| 3-14 | ||||||||||
| 2-17 | ||||||||||
| 5-14 | ||||||||||
| 3-13 | ||||||||||
| 4-15 | ||||||||||
| 1-5 | ||||||||||
| 1-3 | ||||||||||
| 4-18 | ||||||||||
| 3-17 | ||||||||||
| 1-6 | ||||||||||
| 3-10 | ||||||||||
| 5-16 | ||||||||||
| 9-18 | ||||||||||
| 10-18 | ||||||||||
| 11-18 | ||||||||||
| 6-17 | ||||||||||
| 14-18 | ||||||||||
| 7-18 |
Тур 2
Таблица 2
| Номер/ Наименование | Эксперты | Средний ранг после 1 тура | Диапазон изменения ранга | ||||||||
| фактора | фактора | ||||||||||
| 4-8 | |||||||||||
| 6-13 | |||||||||||
| 8-12 | |||||||||||
| 3-6 | |||||||||||
| 6-11 | |||||||||||
| 1-3 | |||||||||||
| 9-15 | |||||||||||
| 6-16 | |||||||||||
| 1-4 | |||||||||||
| 4-7 | |||||||||||
| 5-17 | |||||||||||
| 10-18 | |||||||||||
| 13-16 | |||||||||||
| 15-17 | |||||||||||
| 10-16 | |||||||||||
| 17-18 | |||||||||||
| 11-18 |
Пусть имеется m ранжирований n факторов. Представим каждое из них в виде матриц упорядочения, например,  и
и  , элементы которых определяются следующим образом:
, элементы которых определяются следующим образом:

Очевидно, что расстояние (Кемени, Снелл, 1972).

характеризует степень рассогласования между ранжированиями Z и T. Тогда в матрице  , которую назовем матрицей рассогласования, будут представлены все
, которую назовем матрицей рассогласования, будут представлены все  между ранжированиями (Хубаев, 1973).
между ранжированиями (Хубаев, 1973).
Д - симметричная положительная матрица с нулевыми диагональными элементами, поскольку
 .
.
Сумма элементов i-ой строки матрицы Д характеризует степень рассогласования i-го эксперта с остальными. Матрица Д может быть преобразована в матрицу
 .
.
Сравнением сумм элементов  матрицы Д можно количественно оценить степень сходимости мнений специалистов при проведении нескольких туров опросов. Таксономический анализ матрицы Д (Д’) позволяет выделить согласованные группы среди экспертов.
матрицы Д можно количественно оценить степень сходимости мнений специалистов при проведении нескольких туров опросов. Таксономический анализ матрицы Д (Д’) позволяет выделить согласованные группы среди экспертов.
В таблицах 4 и 5 матрицы рассогласования, полученные после машинной обработки анкет первого и второго туров опросов экспертов относительно степени влияния факторов на один из показателей качества работы зерноуборочных комбайнов (дробление зерна).
Как видно из таблиц, общая величина рассогласования после второго тура уменьшилась более, чем в 1,5 раза (рассогласование между средними рангами после 1 и 2 туров равно 64).
Опросы прекращаются, когда величина рассогласования стабилизируется. Обычно это достигается после 2-3 тура опросов.
На следующем этапе матрицу рассогласования необходимо разбить на однородные группы одним из алгоритмов таксономии. В результате таксономического анализа матрицы рассогласования может возникнуть одна из следующих ситуаций (Розин, 1973, 1976):
а) ответы большинства экспертов образуют однородную группу, причем состав групп остается стабильным при различных разбиениях. Отдельные эксперты с резко отличающимся мнением образуют единичные или малочисленные таксоны;
б) в процессе разбиений помимо единичных таксонов выделяется несколько стабильных, четко организованных групп;
в) на разных шагах разбиения образуются нестабильные группы, ответы экспертов приблизительно равномерно рассеяны в пространстве факторов.
В первом случае имеется хорошая согласованность ответов большинства экспертов. Выделенная однородная группа ответов может приниматься за эталон, на ее основе производится упорядочение факторов в соответствии с коллективным мнением. Вторая ситуация позволяет выдвинуть гипотезу о неоднородности коллектива экспертов. В этом случае задача заключается в выявлении набора объективных характеристик экспертов, обуславливающих эту неоднородность, и построении упорядоченной последовательности факторов для каждой выделенной группы экспертов. Появление третьей ситуации - равномерного рассеяния точек - ответов по всему факторному пространству - означает, что, либо неудачно выбран набор факторов в анкете, либо существенно неоднороден и некомпетентен коллектив экспертов, либо и то и другое вместе. В этом случае возможны два решения: переработать анкеты и повторить опрос, или же ранжировать только те факторы, по которым имеется достаточно высокая согласованность мнений экспертов.
В заключение отметим, что применение экспертных методов часто оказывается единственно возможным способом уменьшения размерности пространства факторов. Например, при оптимизации режимов работы зерноуборочной техники в составленный на основании анализа протоколов испытаний машин список было включено более 30 различных факторов: состояние хлебостоя, влажность зерна, соломы, воздуха, параметры технологических регулировок и ряд других. Естественно, возникла необходимость сократить этот список факторов, выделив наиболее значимые из них.
На первый взгляд, эта задача не представляет особых трудностей. На МИСах 80 «Сельхозтехника» ежегодно в соответствии с утвержденным планом проводятся испытания сельскохозяйственных машин и тракторов. За годы испытаний по всем зерноуборочным комбайнам накоплена обширная информация, содержащая данные по тысячам опытов. Естественно, что, имея такую матрицу наблюдений и воспользовавшись стандартными программами статистического анализа, можно легко выделить значимые факторы, чтобы затем, если они окажутся управляемыми, построив математическую модель, активно воздействовать на эффективность использования зерноуборочной техники.
Однако при тщательном анализе матрицы исходных данных обнаружилось, что в ней имеется много выпавших наблюдений (в строчках матрицы исходных данных отсутствовали значения одного или нескольких факторов). Такое положение вынуждало исключать из рассмотрения опыты, в которых отсутствовало значение хотя бы одного из факторов.1 В результате в матрице исходных данных осталось лишь несколько строк.
Таким образом, поскольку число опытов получилось значительно меньше числа факторов, общие статистические методы набора существенных факторов, основанные на анализе матрицы наблюдений, оказались здесь непригодными. Поэтому возникла необходимость уменьшить число включаемых в рассмотрение факторов с тем, чтобы, вновь обратившись к протоколам испытаний, попытаться расширить матрицу наблюдений.
Анализ литературных источников не позволил сделать однозначный отбор наиболее существенных факторов, поскольку в опубликованных работах специалистами высказывались различные, а порой и противоречивые суждения о степени влияния того или иного фактора на показатели качества работы зерноуборочной техники. В сложившейся ситуации было принято решение провести анкетный опрос специалистов (инженеров, агрономов, комбайнеров) с использованием описанной выше дельфийской процедуры. В результате априорного анализа объекта исследования удалось отобрать небольшую группу наиболее существенных факторов, расширить матрицу наблюдений (естественно, что для меньшего числа факторов заполненных строк в матрице оказалось больше) и, использовав стандартные процедуры регрессионного анализа (см. ниже), количественно оценить значимость выделенных факторов и характер их взаимосвязи и построить уравнения, описывающие исследуемый процесс с высокой точностью.
Тема 5: Регрессионные модели в технико-экономических исследованиях
Задачи анализа и моделирования экономических процессов с использованием вероятностных методов, этапы разработки регрессионной модели, выделение значимых факторов для включения в модель.

