




В лабораторной работе № 1 выявили, что на чистый доход (y) предприятий оказывают влияния такие факторы, как использованный капитал (x2) и численность служащих (x3).
Для нахождения остатков  можно воспользоваться инструментом анализа данных Регрессия. Порядок действий следующий:
можно воспользоваться инструментом анализа данных Регрессия. Порядок действий следующий:
а) в главном меню выберите Сервис/Анализ данных/Регрессия. Щелкните по кнопке ОК;
б) заполните диалоговое окно ввода данных и параметров ввода как показано на рисунке 3.1:
Входной интервал Y – диапазон, содержащий данные результативного признака;
Входной интервал Х – диапазон, содержащий данные всех пяти факторов;
Метки – флажок, который указывает, содержит ли первая строка названия столбцов или нет;
Константа – ноль – флажок, указывающий на наличие или отсутствие свободного члена в уравнении;
Выходной интервал – достаточно указать левую верхнюю ячейку будущего диапазона;
Новый рабочий лист - можно задать произвольное имя нового листа;
Остаток - флажок, указывает вывод остатков  и теоретические значения результативного признака.
и теоретические значения результативного признака.
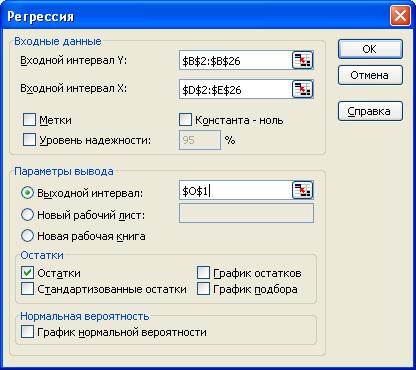
Рисунок 3.1 – Регрессия с остатками
Результаты регрессионного и корреляционного анализа, а также вспомогательные характеристики представлены на рисунке 3.2.

Рисунок 3.2 – Вывод остатковu9:
Проверим остатки полученного уравнения регрессии на гетероскедастичность.
Графический анализ остатков
Построим графики остатков для каждого уравнения (рисунки 3.3 и 3.4)

Рисунок 3.3 – График остатков для фактора х2

Рисунок 3.4 – График остатков для фактора х3
Как видно на рисунке отклонения не лежат внутри полуполосы постоянной ширины, это говорит, о зависимости дисперсионных остатков от величины х3 и о их непостоянстве, т.е. о наличии гетероскедастичности.
Тест Голфелда-Квандта
Выдвигаются гипотезы:
Но:  - гомоскедастичность;
- гомоскедастичность;
Н1:  - гетероскедастичность.
- гетероскедастичность.
Порядок проведения теста следующий:
1 Все n наблюдений упорядочиваются по величине X2 и X3 (таблицы 3.1 и 3.2).
Таблица 3.1 – Упорядоченные значения по фактору х2
| № предприятия | 
| 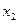
|
| 0,4 | ||
| 0,7 | 0,4 | |
| 2,2 | 0,5 | |
| 2,4 | 0,9 | |
| 3,3 | 1,3 | |
| 2,9 | 1,6 | |
| 2,3 | 1,6 | |
| 2,5 | 1,9 | |
| 2,9 | 2,2 | |
| 2,9 | 2,4 | |
| 3,6 | 3,2 | |
| 3,5 | 3,3 | |
| 3,4 | ||
| 3,5 |
Продолжение таблицы 3.1
| № предприятия |
|
|
| 3,4 | 3,6 | |
| 3,5 | 3,7 | |
| 3,3 | 3,8 | |
| 2,7 | 4,2 | |
| 2,3 | 5,1 | |
| 3,5 | 5,3 | |
| 2,5 | 5,3 | |
| 3,2 | 5,6 | |
| 4,2 | 6,1 | |
| 8,5 | 16,8 | |
| 5,7 | 27,5 |
2 Исключим С центральных наблюдений, разобьем совокупность на две части: а) со значениями x ниже центральных; б) со значениями x выше центральных.
Пусть С=5, это наблюдения с порядковыми номерами 11-15.
Таблица 3.2 – Упорядоченные значения по фактору х3
| № предприятия | 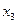
|
|
| 1,6 | ||
| 8,9 | 2,2 | |
| 9,2 | 2,3 | |
| 10,3 | 2,9 | |
| 12,9 | 2,4 | |
| 16,4 | 3,5 | |
| 16,5 | 2,5 | |
| 19,3 | 3,3 |
Продолжение таблицы 3.2
| 22,8 | 3,5 | |
| 23,8 | 3,5 | |
| 24,9 | 3,3 | |
| 25,2 | 3,6 | |
| 27,2 | 2,9 | |
| 31,1 | 2,3 | |
| 32,9 | 3,2 | |
| 36,9 | 2,5 | |
| 37,2 | 2,9 | |
| 40,4 | ||
| 40,8 | 4,2 | |
| 50,4 | 0,7 | |
| 53,8 | 2,7 | |
| 54,6 | 3,4 | |
| 81,5 | ||
| 133,5 | 5,7 | |
| 286,5 | 8,5 |
3 Оцениваются отдельные регрессии для первой подвыборки (10 первых наблюдений) и для третьей подвыборки (10 последних наблюдений). Если предположение о пропорциональности дисперсий отклонений значениям X верно, то дисперсия регрессии по первой подвыборке (сумма квадратов отклонений  ) будет существенно меньше дисперсии регрессии по третьей подвыборке (суммы квадратов отклонений
) будет существенно меньше дисперсии регрессии по третьей подвыборке (суммы квадратов отклонений  ).
).
4 По каждой части находим уравнение регрессии (рисунок 3.5):

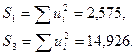

Рисунок 3.5 – Вывод итогов для подвыборок для фактора х2
5 Для сравнения соответствующих дисперсий строится следующая F-статистика: 
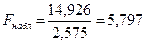 ,
,
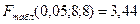 .
.
При сделанных предположениях относительно случайных отклонений построенная F-статистика имеет распределение Фишера с числами степеней свободы v1=v2=(n-C-2m)/2.
6 Если  , то гипотеза об отсутствии гетероскедастичности отклоняется (
, то гипотеза об отсутствии гетероскедастичности отклоняется ( - выбранный уровень значимости).
- выбранный уровень значимости).
По проведенным расчетам мы получили, что  следовательно в ряду остатков обнаружена гетероскедастичность.
следовательно в ряду остатков обнаружена гетероскедастичность.
Аналогично проводится анализ для фактора х3.

