




D Z/Z = [(D X)2 + (D Y)2]1/2/(X + Y)(29)
очевидно не зависит от соотношения величин X и Y.
Следующий вывод, вытекающий из закона сложения погрешностей, относится к определению погрешности среднего арифметического. Мы уже говорили, что среднее арифметическое из ряда измерений отягчено меньшей погрешностью, чем результат каждого отдельного измерения. Сейчас этот вывод может быть записан в количественной форме. Пусть x 1, x 2,..., хn результаты отдельных измерений, причем каждое из них характеризуется одной и той же дисперсией S 2. Образуем величину y, равную
y = (1/ n)× Axi = x 1/ n + x 2/ n +... + хn / n.
Дисперсии этой величины Sy 2 в соответствии с формулой (26) определяются как
Sy 2 = S 2/ n 2 + S 2/ n 2 +... + S 2/ n 2 = nS 2/ n 2 = S 2/ n (30)
Но y, по определению, это – среднее арифметическое извсех величин xi, и мы можем написать
Sy = S < x > = S / n 1/2. (31)
Средняя квадратическая погрешность среднего арифметического равна средней квадратической погрешности отдельного результата измерений, деленной на корень квадратный из числа измерений.
Это – фундаментальный закон возрастания точности при росте числа наблюдений. Из него следует, что, желая повысить точность измерений в 2 раза, мы должны сделать вместо одного – четыре измерения; чтобы повысить точность в 3 раза, нужно увеличить число измерений в 9 раз, и, наконец, увеличение числа наблюдений в 100 раз приведет всего лишь к десятикратному увеличению точности измерений.
Разумеется, это рассуждение относится лишь к измерениям, при которых точность результата полностью определяется случайной погрешностью. В этих условиях, выбрав n достаточно большим, мы можем существенно уменьшить погрешность результата. Такой метод повышения точности сейчас широко используется, особенно при измерении слабых электрических сигналов.
Рассмотрим снова пример со взвешиванием.
Допустим, что 0.05 г – средняя квадратическая погрешность одного взвешивания, и мы по-прежнему взвешиваем 100 образцов, кладя на весы каждый раз только один из них.
В соответствии с изложенным погрешность определения суммарной массы M этих образцов будет SM = [1S100 S i2]1/2;.
так как погрешности всех измерений одинаковы, а всего измерений 100, то погрешность суммарной массы SM = (100)1/2× S = 10× S = 10´0.05 = 0.5 г.
Таким образом, мы можем утверждать, что из 1000 измерений общей массы, проделанных описанным выше способом, около 320 дадут отклонения от измеренного значения больше чем на 0.5 г, только около 50 – более чем на 1 г, и около трех – результаты которых будут на 1.5 г и более отличаться от истинного значения.
При практической работе очень важно строго разграничивать применение средней квадратической погрешности отдельного измерения nS и средней квадратической погрешности среднего арифметического S < x >.
Последняя применяется всегда, когда нам нужно оценить погрешность того значения, которое мы получили в результате всех произведенных измерений.
В тех случаях, когда мы хотим характеризовать точность применяемого способа измерений, следует использовать погрешность nS или s, если n достаточно велико.
Поясним сказанное следующим примером.
Было сделано десять измерений электрического сопротивления провода R, в результате которых получены значения, приведенные в табл.4.
<R> = S Ri /10 = 274.7, 10S» 1.6, nS < R > = 1.6/101/2» 0.5.
Таблица 4. Измерения сопротивления
| Номер измерения | б | |||||||||
| R |
Таким образом, средняя квадратическая погрешность SR измерения сопротивления данного провода равна 0.5 Ом, или же, переходя к относительным погрешностям, около 0.2%. Но квадратическая погрешность 10 S применяемого метода измерений составляет 1.6 Ом, а относительная его погрешность – около 0.6%.
Если мы описываем метод, которым производилось измерение, то должны указать именно эту последнюю погрешность. Зная ее, можно выбрать нужное число измерений, чтобы, пользуясь табл.1V, получить желаемую случайную погрешность окончательного результата измерений.
Сейчас[9]) принято среднюю квадратическую погрешность результата измерений записывать в скобках непосредственно после результата. В нашем примере для электрического сопротивления R это будет выглядеть так:
R = 274.7 (0.5).
6. СТАТИСТИЧЕСКИЕ ВЕСА
Допустим, что одним и тем же методом с одинаковой степенью точности выполнено k серий измерений. В первой серии число измерений n 1, во второй - n 2 и т.д., в k -й - nk; если каждое измерение характеризуется погрешностью s, то погрешность среднего арифметического для серии с номером i будет в соответствии с формулой (26)[10])
s i = s/(ni)1/2.
Очевидно, что если в одной серии сделано в четыре раза больше измерений, чем в другой, то погрешность результата одной серии будет соответственно в два раза меньше.
Если мы захотим для повышения точности результата усреднять его по средним значениям для обеих серий, то должны учитывать то обстоятельство, что один результат получен с вдвое меньшей погрешностью. С этой целью вводится понятие статистического веса или просто веса наблюдений. В приведенном примере за статистический вес р следует принять число, пропорциональное количеству наблюдений, выполненных в серии, то есть положить
pi = k×ni.
Подставив отсюда значение ni в (16), имеем
pi = k× s2/s i 2
или, положив коэффициент пропорциональности k s2 = К,получим
pi = K/ s i 2.
Если имеется ряд результатов измерений, вообще выполненных в разных условиях, причем для каждого результата известна средняя квадратическая погрешность s i, то и в этом случае можно для совместной обработки результатов приписать им соответствующие статистические веса pi,положив также
pi = B/ s i 2.
Здесь B – произвольное число. Оно обычно выбирается таким, чтобы pi, были по возможности небольшими целыми числами. Часто бывает, что s i заранее неизвестны и отдельным измерениям приписываются веса на основании разного рода качественных соображений, связанных, например, с квалификацией наблюдателей, производивших отдельные измерения, различием в точности измерительных инструментов, с которыми они производились, и т.п.
Введение статистических весов, определенных на глаз, разумеется, нельзя считать строгим приемом, однако он дает возможность хоть как-то использовать всю совокупность наблюдений. Следует иметь в виду, что если веса отдельных наблюдений различаются в 10 и более раз (s i и s k различаются более чем в три раза), то обычно лучше просто отбросить из рассмотрения наблюдения с малыми весами, так как их учет может только испортить хорошие результаты.
Если нам известна совокупность ряда результатов xi с соответствующими им статистическими весами pi, то за наивероятнейшее значение измеряемой величины следует принять уже не среднее арифметическое, а взвешенное среднее, которое также обозначим < x >:
< x > = 1S npixi /1S npi. (32)
Разумеется, если p 1 = p 2 =... = pn, то (32) переходит в (3).
Среднюю квадратическую погрешность для < x > можно получить аналогично тому, как она была определена для равноточных измерений.
В результате
nS < x > = {[1S npi (< x > – xi)2]/[(n –1)×1S npi ]}1/2 (33)
При выборе нужного числа измерений предполагаем, что систематическая погрешность метода достаточно мала. (Подробнее обэтом см. на стр. 67).
7. ОПРЕДЕЛЕНИЕ ДОВЕРИТЕЛЬНОГО ИНТЕРВАЛА
И ДОВЕРИТЕЛЬНОЙ ВЕРОЯТНОСТИ
Ранее мы с помощью табл. II определяли доверительные вероятности для отдельного измерения xi, то есть, вычисляли вероятность того, что xi не будет уклоняться от истинного значения более чем на D x. Очевидно, важнее знать, насколько может уклоняться от истинного значения x среднее арифметическое < x > наших измерений. Для этого также можно воспользоваться табл.IV, взяв, однако, вместо s значение s< x >, то есть s xi / n 1/2.
Тогда для аргумента e, с которым мы входим в табл. II, будем иметь значение
e = D x /s< x > = D x × n 1/2/s. (34)
Мы теперь знаем, как определять доверительную вероятность для любого доверительного интервала, если известна средняя квадратическая погрешность s. Однако для того чтобы определить последнюю, нужно сделать очень много измерений, а это не всегда возможно и удобно. В тех случаях, когда измерения проводятся с помощью уже хорошо исследованного метода, погрешности которого известны, мы заранее знаем s. Как правило, однако, погрешность метода приходится определять в процессе измерений. И обычно мы можем определить только величину nS, соответствующую тому или иному, но всегда сравнительно небольшому числу измерений n (2 S, 3 S, 4 S,..., nS здесь означают средние квадратические погрешности отдельного измерения, определенные по формуле (16) для случаев двух, трех, четырех и т.д. измерений). Если для оценки доверительной вероятности будем считать, что полученные нами значения совпадают с s, и воспользуемся табл.II для нахождения доверительной вероятности, то найдем неверные (завышенные) значения a.
Это результат того, что при определении среднеквадратической погрешности из малого числа наблюдений мы находим эту погрешность с малой точностью. Происходящая вследствие этого неопределенность в определении погрешности приводит ктому, что когда мы заменяем s на nS, то уменьшаем надежность нашей оценки, причем тем сильнее, чем меньше n.
Еще сравнительно недавно (лет 25¸30 назад) указанные обстоятельства не всегда принимались во внимание, да и сейчас зачастую не делают различия между генеральной s2 и выборочной nS2 дисперсией.
Пусть мы определили выборочную дисперсию nS 2 для некоторого числа наблюдений n и хотим определить для заданного нами доверительного интервала ±D x соответствующую ему доверительную вероятность.
Очевидно, что если в формуле (34) заменим s на n S2 то такому доверительному интервалу будет соответствовать меньшая доверительная вероятность. Для того чтобы учесть это обстоятельство, интервал D x можно представить в виде
D x = t a, n × nS / n 1/2, (35)
откуда
t a, n = D x × n 1/2/ nS. (36)
Мы видим, что t a, n – величина, аналогичная e: она играет ту же роль, но в случае, когда число измерений, из которых определена погрешность nS,не очень велико.
Величины t a, n , носящие название коэффициентов Стьюдента, вычислены по законам теории вероятностей для различных значений п и a и приведены в табл. III, также помещенной в Приложении.
Сравнивая табл.III с табл.II, легко убедиться, что при больших n значения t a, n стремятся к соответствующим значениям e. Это естественно, так как с увеличением n величина nS стремится к s.
Используя коэффициенты Стьюдента, мы можем переписать равенство (21) в виде
P ( [<x> – t a, n nS / n 1/2] < x < [< x > + t a, n nS / n 1/2] ) = a. (37)
Пользуясь этим соотношением и табл. III, легко определять доверительные интервалы и доверительные вероятности при любом небольшом числе измерений.
Дадим примеры применения табл. III. Пусть среднее арифметическое из 5 измерений будет 31.2. Средняя квадратическая погрешность, определенная из 5 измерений, равна 0.24. Мы хотим найти доверительную вероятность того, что среднее арифметическое отличается от истинного значения не более чем на 0.2, то есть будет выполниться неравенство 31.0< x < 31.4,
Значение t a,5 определим, подставив полученные результаты в формулу (36), тогда
t a,5 = 0.251/2/0.24 = 1.86.
По табл. III находим для n = 5 при a = 0.8 имеем t 0.8,5 = 1.5, а при a = 0.9 имеем t 0.9,5 = 2.1.
Вообще говоря, можно обычно удовлетвориться ответом,что доверительная вероятность для этого случая лежит межу 0.8 и 0.9. Если нужно получить более точное значение, то вычислим пропорциональную часть подобно тому, как это обычно делается при пользовании таблицами.
Нужную нам величину вычисляем из пропорции
Da/(a2 – a1) = (t a,n – t 0.8, n )/(t0.8,n – t 0.9,n),
откуда
Da = 0.1×(0.36/0.6) = 0.06, a = a1 +Da = 0.8 + 0.06 = 0.86.
Таким образом, доверительная вероятность получается равной 0.86.
Вычислим теперь, какова доверительная вероятность в случае 10 измерений при той же средней квадратической погрешности 0.24 и том же доверительном интервале 31.0¸31.4. По формуле (36) определяем
t a,10 = 0.2×101/2/0.24» 2.6.
Из табл. III находим, что ближайшее меньшее значение
t a,10 = 2.3 для a = 0.95
и ближайшее большее значение
t a,10 = 2.8 для a = 0.98.
Пропорциональную часть найдём из соотношения
Da = 0.3×0.03/0.5» 0.02.
Окончательно a = 0.97.
8. СРАВНИТЕЛЬНАЯ ОЦЕНКА
РЕЗУЛЬТАТОВ СТАТИСТИЧЕСКОЙ ОБРАБОТКИ
Пусть мы получили ряд измерений одной и той же величины. В нем всегда могут оказаться отдельные результаты, подозрительно отличающиеся (в большую или меньшую сторону) от остальных членов ряда.
Следует ли их принимать во внимание при статистической обработке или нужно отбросить, как явно ошибочные?
Очевидно, что нельзя пользоваться интуицией и нужно применять какие-то вероятностные критерии, на основании которых данное измерение признается ошибочным и выбрасывается либо оставляется, как допустимое в данном ряду естественное статистическое отклонение. Не менее важные вопросы возникают при производстве нескольких рядов наблюдений одной и той же физической величины. В результате мы получаем для каждого ряда свои значения < x > и S:
<x >1, < x >2,..., < x > n и S 1, S 2,..., Sn.
Можно ли считать, что все эти результаты принадлежат одной и той же генеральной совокупности или разным? В первом случае их следует обрабатывать совместно и за счет этого уменьшать погрешность результата. Во втором – рассматривать их по отдельности – независимо друг от друга. Очевидно, что все эти вопросы имеют не достоверные, а лишь вероятные ответы. Расхождения между соответствующими результатами считаются значимыми, если вероятность того, что они случайны, превышает некоторую заданную нами величину, например 0.05, 0.01 или 0.001, называемую уровнем значимости.
Выбор того или иного уровня значимости, вообще говоря, произволен и зависит в первую очередь от того, насколько важны последствия ошибочного выбора. Иначе говоря, что произойдет, если считать два числа принадлежащими к одной совокупности, когда они принадлежат к разным и наоборот. Это решается совершенно аналогично вопросу о том, когда можно считать вероятность того или иного события равной нулю (см. стр. 31).
Чем серьезнее последствия такой ошибки, тем при меньшем уровне значимости нужно рассматривать сравниваемые числа как принадлежащие разным совокупностям.
Вначале разберем вопрос о тех погрешностях, с которыми определяется сама погрешность. Если мы находим S из очень большого числа измерений, то получаем величину, как угодно мало отличающуюся от своего предельного значения, но когда n невелико, то S отягчена случайными погрешностями, очевидно, тем меньшими, чем больше n.
Точно так же, как и для результатов измерений, существует закон распределения, дающий возможность установить доверительную вероятность того, что определенная нами из n измерений погрешность nS будет отличаться от s на некоторое заданное нами число.
Для определения доверительного интервала, внутри которого находится s, можно воспользоваться приближенной формулой
s nS» s/[2×(n – 1)]1/2. (38)
Здесь s пS – средняя квадратическая погрешность n S, когда nS вычислено из n измерений; вообще говоря, это выражение справедливо для n, большего 30, но в случае грубых оценок его можно использовать и для меньших n.
Из формулы (38) следует, что при n = 25 s25S = s/7, то есть s определяется с точностью около 7. При n = 50 точность определения s составляет около 10.
Более строгое рассмотрение дает возможность правильной оценки доверительного интервала для s и прималом числе измерений.
Для этого мы введем величину c2, которую определим следующим образом:
 c2 = (n – 1) nS 2/s2.
c2 = (n – 1) nS 2/s2.
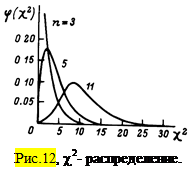
Закон распределения этой величиныизвестен под названием c2-распределения, которое представлено графически на рис.12.
Функция распределения c2 характеризуется асимметричностью, особенно сильной для малых n. Для больших n это распределение переходит в нормальное с дисперсией, определяемой формулой (38). Доверительный интервал для s вычисляется с помощью таблицы, составленной для нормального распределения.
При более точных оценках доверительного интервала для s можно воспользоваться табличными значениями, составленными для c2 -распределения.
Из выражения (39) следует
s2 = [(n – 1)/c2] nS 2 = g2× nS 2. (40)
Табл.III дает возможность определить значения g1 и g2 удовлетворяющие условию
P (g1× n S < s) = a1, P (g2× nS > s) = a2.
Так как c2 -распределение асимметрично, то погрешности равных значений, но противоположного знака не равновероятны, как в случае нормального распределения. Отсюда следует, что при условии
a1 = a2×g1 ¹ 1/g2.

