




ЧАСТЬ 2. МАТЕМАТИЧЕСКАЯ СТАТИСТИКА
ГЛАВА 1. ОСНОВНЫЕ ПОНЯТИЯ
ЗАДАЧИ МАТЕМАТИЧЕСКОЙ СТАТИСТИКИ
Математическая статистика выделяется из теории вероятностей в самостоятельную область, хотя основные методы и приёмы рассуждений в ней остаются теми же самыми. Причиной этого является специфичность задач математической статистики, являющихся в известной степени обратными к задачам теории вероятностей. Если в теории вероятностей мы считаем заданной модель явления и производим расчёт возможного реального течения этого явления, то в математической статистике мы исходим из известных реализаций каких-либо случайных событий, из так называемых статистических данных, которые обычно носят числовой характер. Математическая статистика разрабатывает различные методы, которые позволяют по этим статистическим данным подобрать подходящую теоретико-вероятностную модель. Например, пусть имеется n независимых наблюдений в схеме Бернулли и пусть в m из них произошло событие A. Одна из задач математической статистики: как по m осуществлениям события A в n независимых испытаниях определить вероятность p=Р (А).
Перечислим те основные задачи, которые решает математическая статистика, на примере схемы Бернулли.
А) Проверка статистических гипотез.
Из каких-либо априорных соображений мы можем предполагать, что p=p 0, где p 0 – некоторое фиксированное значение. По относительной частоте m / n мы должны решить справедлива гипотеза p=p 0 или нет. Поскольку при больших n относительная частота m / n близка к p, то статистический критерий по проверке гипотезы p=p 0 должен основываться на значении модуля разности | m / n - p 0|. Если она большая, то, по-видимому, гипотеза неверна, если же она мала, то у нас нет оснований отвергать гипотезу p=p 0.
Б) Статистическое оценивание неизвестных параметров. Иногда нам требуется по наблюдаемому m указать то число p *, которое можно принять за вероятность p в схеме Бернулли. В нашем примере естественно взять p * = m / n. Оценка должна быть в том или ином смысле близкой к оцениваемому параметру.
В) Доверительные интервалы. Иногда нас интересует не точное значение неизвестного параметра p, а требуется указать тот интервал p - £ p£ p +, в котором с вероятностью, близкой к единице, лежит параметр p. Такой интервал (p -(m), p +(m)), концы которого случайны и зависят от наблюдаемого значения m, называется доверительным интервалом.
ВЫБОРОЧНЫЙ МЕТОД
Терминология многих статистических задач связана со следующей схемой. Пусть имеется урна с карточками, на которых нанесены числа X 1, X 2,…, XN. Из урны случайно выбираются n карточек с числами x 1, x 2,…, xn. Полученный набор чисел
x 1, x 2,…, xn (1.1)
называется выборкой объема n из генеральной совокупности
X 1, X 2,…, XN . (1.2)
Выборка может быть без возвращения, когда каждое подмножество { Xi 1,…, Xin } мощности n из всего множества (1.2) появляется с вероятностью  , и с возвращением, когда каждый упорядоченный набор { Xi 1,…, Xin }, где могут быть повторения появляется с вероятностью
, и с возвращением, когда каждый упорядоченный набор { Xi 1,…, Xin }, где могут быть повторения появляется с вероятностью  . Нетрудно видеть, что в случае выборки с возвращением x 1, x 2,…, xn являются независимыми случайными величинами с законом распределения случайной величины x, которая с одной и той же вероятностью 1/ N принимает каждое из значений (2), если все Xj различны:
. Нетрудно видеть, что в случае выборки с возвращением x 1, x 2,…, xn являются независимыми случайными величинами с законом распределения случайной величины x, которая с одной и той же вероятностью 1/ N принимает каждое из значений (2), если все Xj различны:

В этом случае говорим, что (1.1) есть независимая выборка объёма n, или независимая реализация объёма n случайной величины (СВ) x.
Упорядочивая выборку (1.1) по возрастанию, мы получаем вариационный ряд x (1), x (2),…, x ( n ).
С любой выборкой (1.1) можно связать эмпирическое, или выборочное распределение, приписывая каждому значению xi вероятность 1/ n. Эмпирической (или выборочной) функцией распределения будет F *(x) = nx / n, где nx – число выборочных значений, расположенных на оси абсцисс левее или равных x.
Поскольку выборка (1.1) случайна, то эмпирическая функция распределения при каждом есть случайная величина x.
Для каждой конкретной выборки эмпирическая функция распределения будет своей, но все возможные эмпирические функции распределения одной и той же случайной выборки будут иметь нечто общее, что является информацией о функции распределения генеральной совокупности.
Можно доказать (теорема Гливенко), что с вероятностью 1 при  максимальная разница между эмпирической и генеральной функциями распределения F *(x) и
максимальная разница между эмпирической и генеральной функциями распределения F *(x) и 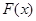 стремится к 0:
стремится к 0:

Практически это означает, что при достаточно большой выборке, функцию распределения генеральной совокупности можно приближенно заменять выборочной функцией распределения.
Пусть  – упорядоченная по величине выборка из генеральной последовательности (вариационный ряд).
– упорядоченная по величине выборка из генеральной последовательности (вариационный ряд).
 Все элементы независимой выборки имеют одинаковую вероятность, равную
Все элементы независимой выборки имеют одинаковую вероятность, равную  Поэтому, согласно определению функции F *(x), имеем
Поэтому, согласно определению функции F *(x), имеем  , при
, при  ;
;  при
при  ,
,  ;
;  , при
, при  . На рис.1 приведен график F *(x). Элементы выборки оказываются точками разрыва этой функции. В точке разрыва
. На рис.1 приведен график F *(x). Элементы выборки оказываются точками разрыва этой функции. В точке разрыва  функция F *(x) скачком переходит от значения
функция F *(x) скачком переходит от значения  (в интервале
(в интервале  ) к значению
) к значению  , удерживая это значение в следующем интервале, то есть F *(x) непрерывна справа.
, удерживая это значение в следующем интервале, то есть F *(x) непрерывна справа.
Рис. 1.
При обработке выборок больших объемов используют метод “сгруппированных данных”: выборка объема  преобразуется в статистический ряд. Для этого весь диапазон изменения выборочных значений
преобразуется в статистический ряд. Для этого весь диапазон изменения выборочных значений  делится на
делится на  равных интервалов. Число интервалов можно выбрать по полуэмпирической формуле
равных интервалов. Число интервалов можно выбрать по полуэмпирической формуле  с округлением до ближайшего целого. Длина интервала
с округлением до ближайшего целого. Длина интервала  равна
равна  / k.
/ k.
Число элементов выборки попавших в  -й интервал, обозначим через
-й интервал, обозначим через  . Величина, равная
. Величина, равная
 ,
,
определяет относительную частоту попадания выборочных значений в -й интервал. Все точки, попавшие в -й интервал, относят к его середине  :
:  .
.
 Статистический ряд записывается в виде таблицы. График, построенный по данным таблицы, называется гистограммой эмпирического или выборочного распределения (рис.2).
Статистический ряд записывается в виде таблицы. График, построенный по данным таблицы, называется гистограммой эмпирического или выборочного распределения (рис.2).
Рис.2 Гистограмма
Математическое ожидание (среднее), дисперсия, моменты эмпирического распределения также будут случайными величинами и будут называться соответственно эмпирическими (или выборочными) математическим ожиданием (средним), дисперсиями, моментами.
Таким образом, выборочное среднее есть среднее арифметическое элементов выборки:
 , (1.3)
, (1.3)
и выборочная дисперсия равна
 (1.4)
(1.4)
Выборочные моменты и центральные моменты порядка r определяются выражениями:
 ,
, 
“Выборочная” терминология сохраняется и в том случае, когда генеральная совокупность (1.2) не состоит из конечного числа элементов N, а просто есть некоторый генератор независимых случайных величин xi с каким-то законом распределения.
Такой идеализацией в математической статистике пользуются или при очень больших N, (например, при статистических обследованиях в демографии, экономике, социологии), или в том случае, когда элементы выборки (1.1) можно получать какой-то однородной процедурой любое число раз (например, результаты измерений, размер деталей при масовом их изготовлении).
В математической статистике случайные величины часто обозначаются буквами xi, yi и т.д., соответствующими обозначениям элементов выборки.
В дальнейшем мы будем в основном заниматься независимыми выборками. Относительно бесповторной выборки докажем лишь следующую теорему. Обозначим через
 ,
, 
среднее и дисперсию генеральной совокупности (1.2).
Теорема 1. Эмпирическое среднее  бесповторной выборки (1.1) имеет следующее математическое ожидание и дисперсию:
бесповторной выборки (1.1) имеет следующее математическое ожидание и дисперсию:
 ,
,  . (1.5)
. (1.5)
Доказательство.
Воспользуемся формулами
 ,
,  . (1.6)
. (1.6)
Вычислим M xi, D xi, cov(xi, xj). Поскольку для вычисления нам нужны лишь двумерные распределения xi, xj, рассмотрим конечное вероятностное пространство (W, F, P), где элементарные события w=(k, l), 1£ k ¹ l £ N, и элементарные вероятности p (w)=1/[ N (N -1)]. Случайные величины xi, xj определим равенствами:
xi (k, l) = Xk, xj (k, l) = Xl.
Тогда
 ,
, 
и при i ¹ j


Подставляя найденные значения в (1.6), получаем формулы (1.5).
Замечание. Для выборки с возвращением дисперсия равна  . По неравенству Чебышевапри N ³ n ® ¥ мы получаем
. По неравенству Чебышевапри N ³ n ® ¥ мы получаем  как в случае выборки с возвращением, так и в случае выборки без возвращения.
как в случае выборки с возвращением, так и в случае выборки без возвращения.
ГЛАВА 2. СТАТИСТИЧЕСКИЕ КРИТЕРИИ
СТАТИСТИЧЕСКИЕ ГИПОТЕЗЫ
Пусть случайная величина x или случайный вектор x=(x1,…,x n) имеет плотность p (x,J), зависящую от параметра J, одномерного или многомерного, принимающего значения из некоторого множества X. В частности, если p (x,J) – одномерная плотность и независимая выборка (1.1) получена из распределения с этой плотностью, то n -мерная плотность, соответствующая выборке (1.1), равна произведению
p (x 1,J) p (x 2,J)… p (xn,J).
Хотя мы будем говорить о p (x,J) как о плотности, всё сказанное с очевидными видоизменениями будет применимо и к дискретным случайным величинам с законом распределения p (x,J) = P{x = x }, где x принимает счётное или конечное число значений.
Значение параметра J вполне определяет плотность p (x,J). Те или иные предположения о значениях параметра J мы будем называть статистическими гипотезами.
Статистическая гипотеза называется простой, если она состоит в предположении, что J=J0, где J0 – некоторое фиксированное значение. Если же наше предположение заключается в том, что J Î X0, где X0 Ì X - подмножество множества параметров X, состоящее более чем из одной точки, то мы говорим о сложной гипотезе.
Пример 1. Пусть  - плотность нормального распределения, зависящая от двумерного параметра
- плотность нормального распределения, зависящая от двумерного параметра  . Гипотеза =
. Гипотеза =  является простой, а гипотеза
является простой, а гипотеза  , где
, где  фиксировано - сложной.
фиксировано - сложной.
Пример 2. Пусть  - вероятность
- вероятность  успехов в схеме Бернулли с независимыми испытаниями. Примером простой гипотезы служит
успехов в схеме Бернулли с независимыми испытаниями. Примером простой гипотезы служит  , а примером сложной
, а примером сложной  .
.
Задача проверки статистических гипотез ставится следующим образом. Известно, что выборка (1.1) получена из распределения, имеющего плотность вида 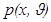 . Относительно параметра
. Относительно параметра 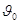 имеется некоторая основная, или проверяемая, гипотеза
имеется некоторая основная, или проверяемая, гипотеза  :
: 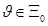 . Мы должны построить такой статистический критерий, который позволяет нам заключить, согласуется ли выборка (1.1) с гипотезой или нет. Обычно критерий строится при помощи критического множества. Из множества
. Мы должны построить такой статистический критерий, который позволяет нам заключить, согласуется ли выборка (1.1) с гипотезой или нет. Обычно критерий строится при помощи критического множества. Из множества 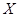 всех возможных значений выборки (1.1) выделяется подмножество
всех возможных значений выборки (1.1) выделяется подмножество  , называемое критическое, что при
, называемое критическое, что при 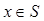 гипотеза отвергается, а в остальных случаях она принимается.
гипотеза отвергается, а в остальных случаях она принимается.
Критическое множество выбирается таким образом, чтобы вероятность

выборке попасть в (когда гипотеза верна) была мала.
Получаемый с помощью критического множества статистический критерий называют иногда - критерием. Естественно, что множество , удовлетворяющее этому требованию можно выбрать многими способами. Более определенный выбор возникает в том случае, когда нам задана конкурирующая или альтернативная гипотеза  .
.
Мы будем рассматривать, главным образом, случай двух простых гипотез: проверяемой гипотезы :  и конкурирующей гипотезы:
и конкурирующей гипотезы:  :
: 
Есть задачи, в которых гипотезы и равноправны. Так обстоит дело при разбиении множества каких-либо объектов на два вида по значениям определенных параметров. Однако очень часто в реальных задачах гипотезы и выступают неравноправно. Например, размер годной детали, изготовляемой на заводе, есть случайная величина, имеющая нормальные распределения с параметрами  ). Предположим, что дефектная деталь имеет соответствующий размер, также нормально распределенный, на уже с параметрами ), где
). Предположим, что дефектная деталь имеет соответствующий размер, также нормально распределенный, на уже с параметрами ), где  . Технический контроль, на который поступают изготовленные детали, исходит из того, что детали должны быть годными, и поэтому проверяют гипотезу , т.е. их годность. В этом случае, - основная гипотеза, и на контроле надо уловить те детали, которые изготовлены в условиях конкурирующей гипотезы .
. Технический контроль, на который поступают изготовленные детали, исходит из того, что детали должны быть годными, и поэтому проверяют гипотезу , т.е. их годность. В этом случае, - основная гипотеза, и на контроле надо уловить те детали, которые изготовлены в условиях конкурирующей гипотезы .

