




В результаті досліду отримані наступні показники: сира маса надземної частини (Y) і сира маса підземної частини (Х) рослин календули лікарської (Calendula officinalis L.).
| Варіант 1 | Варіант 2 | Варіант 3 | Варіант 4 | Варіант 5 | Варіант 6 | ||||||
| Х | Y | Х | Y | Х | Y | Х | Y | Х | Y | Х | Y |
| σy=2,25 | σy=3,13 | σy=4,56 | σy=5,01 | σy=4,45 | σy=2,56 |
1. За наведеними даними побудувати кореляційну таблицю і кореляційну сітку.
2. Розрахувати коефіцієнт кореляції прямим способом та способом «довільного початку».
4. Обчислити квадратичну помилку коефіцієнта кореляції.
5. Провести оцінку істотності коефіцієнта кореляції.
6. Обчислити кореляційне відношення (ηy/x), коефіцієнт детермінації та критерій криволінійності для даних ознак.
Лабораторне заняття № 13–14
Тема: Регресійний аналіз випадкових величин
Мета роботи: ознайомиться з алгоритмом обчислення параметрів прямої, що характеризується рівнянням y=a+bx, побудови емпіричної і теоретичної ліній регресії, а також засвоїти техніку вирівнювання регресійних кривих; навчиться обчислювати коефіцієнти лінійних і нелінійних (логарифмічної і ступеневої) функцій, встановлювати стандартну помилку обчислених значень.
Матеріали й устаткування: калькулятор, лінійка, ваги, навчальні посібники, методичний матеріал, гербарні зразки рослин.
Хід роботи
Основні поняття про регресійний аналіз.Величина коефіцієнта кореляції дозволяє з'ясувати тісноту (силу) і напрям зв'язку між ознаками, проте цим не вичерпуються можливості вивчення зв’язку між ними. У багатьох дослідженнях виникає необхідність вивчити не стільки міру кореляції, скільки її форму й характер зміни однієї ознаки залежно від зміни іншої. Останнє особливо важливо в тих випадках, коли фактичні спостереження не охоплюють всієї різноманітності ознаки і мета дослідження полягає в тому, щоб з'ясувати взаємозалежності між даними, яких не достає. Ці завдання вирішуються методами регресійного аналізу.
Регресійний аналіз полягає в тому, щоб відшукати лінію (пряму – у разі лінійної кореляції, параболу першого, другого і так далі порядків при криволінійній залежності) (рис. 9), які найбільш точно виражають залежність однієї ознаки від іншої.

а б
Рис. 9 – Графіки емпіричної регресії (а – лінійної, б – нелінійної)
У кореляційній таблиці 1 (заняття № 10–12) кожному із значень ознаки X відповідає ряд значень ознаки Y, а кожному Y – декілька значень ознаки X. Можна скласти дві таблиці, що показують зміну значень однієї ознаки залежно від варіювання іншої ознаки (табл. 30 і 31).
Таблиця 30 – Залежність числа зерен від довжини колоса
| Х | Довжина колоса (у см) | |||||||

| 19,0 | 20,7 | 24,1 | 25,5 | 28,0 | 29,0 | 29,5 | 31,0 |
Таблиця 31 – Залежність довжини колосу від числа зерен
| Y | Число зерен у колосі | |||||

| 7,5 | 7,8 | 8,8 | 9,7 | 10,8 | 12,1 |
Побудувавши за даними табл. 30 і 31 графік, ми отримаємо дві криві (рис. 10), що є емпіричними лініями регресії і що показують залежність однієї ознаки від іншої. Якщо ознаки взаємонезалежні, то лінії регресії будуть прямими, розташованими під прямим кутом. Емпіричні лінії регресії, як правило, будуть ламаними, що є результатом впливу випадкових причин, що виявляються у вигляді варіювання значень результативної ознаки. Тому виникає завдання знайти пряму лінію, що якнайкраще відобразить залежність однієї змінної від іншої.
| Довжина колосу (у см) | 
|
| Число зерен |
Рис. 10 – Емпіричні лінії регресії
(×–×–× – X/Y; о–о–о – Y/X)
Крива лінійної регресії може бути побудована за формулою:
 (60)
(60)
де Y0 – теоретичне значення ознаки Y (групова середня);  – середня арифметична ознаки Y;
– середня арифметична ознаки Y;  – середня арифметична ознаки X;
– середня арифметична ознаки X;  – коефіцієнт регресії. Аналогічною є формула для знаходження теоретичної лінії за регресією X по Y:
– коефіцієнт регресії. Аналогічною є формула для знаходження теоретичної лінії за регресією X по Y:
 (61)
(61)
2. Обчислення коефіцієнтів регресії. Коефіцієнти лінійної регресії можуть бути обчислені двома способами. Якщо регресійному аналізу передувало обчислення коефіцієнта кореляції, то:
 ;
;  (62)
(62)
де sx і sy – середні квадратичні відхилення відповідних спостережень.
Першу величину 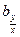 – називають коефіцієнтом регресії Y на X, другу – коефіцієнтом регресії X на Y. Частіше всього з двох коефіцієнтів регресії обчислюють тільки один. Якщо коефіцієнт кореляції невідомий, то:
– називають коефіцієнтом регресії Y на X, другу – коефіцієнтом регресії X на Y. Частіше всього з двох коефіцієнтів регресії обчислюють тільки один. Якщо коефіцієнт кореляції невідомий, то:
 ;
;  (63)
(63)
Приклад. При дослідженні залежності продуктивності рослин соняшнику від числа рослин на ділянці (6,4 м2) був обчислений r=–0,626. Ламана (а) на рис. 11 є емпіричною лінією регресії середнього врожаю рослини (X) на число рослин (Y). Ставиться завдання обчислити коефіцієнт цієї регресії, тобто число, що показує, на яку величину в середньому зменшується врожай однієї рослини при збільшенні числа рослин на одиницю. Попутно обчислимо другий коефіцієнт, що характеризує зміну числа рослин залежно від середнього врожаю на одну рослину, хоча він і не має практичного значення. Коефіцієнти регресії обчислимо двома способами.
| Кількість рослин | 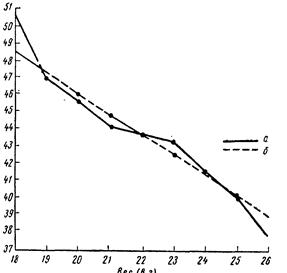
|
| Вага (у г) |
Рис. 11 – Лінія регресії: а – емпірична; б – теоретична
Перший спосіб – за формулою (62). Початкові дані: r=–0,626; ∑(X– )2=593,900; ∑(Y– )2=528,4432; n=160.
Спочатку обчислюємо середні квадратичні відхилення sx і sy:
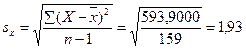 ;
;

 ;
; 
Другий спосіб – за формулою (63). Початкові дані:  , інші – з попереднього способу.
, інші – з попереднього способу.
 ;
; 
Перший коефіцієнт показує, що із збільшенням числа рослин (на ділянці) на одиницю врожай насіння з одного кошика в середньому зменшується на 1,18 грамів, другий – що із збільшенням середнього урожаю кошика на 1 грам число рослин зменшується на 1,32.
3. Рівняння лінійної регресії. Обчислення коефіцієнтів регресії має двоякий сенс. З одного боку, величина b вказує на те, як у середньому змінюється (збільшується або зменшується, звертаючи увагу на знак біля b) результативна ознака на одиницю факторіального, з іншої – коефіцієнт регресії необхідний для обчислення теоретичних значень результативної ознаки для будь-яких значень факторіального, навіть для таких, які не спостерігалися в даному експерименті. Обчислені за рівнянням (60) або (61) теоретичні середні групові значення ознаки X або Y утворюють теоретичну лінію регресії, а прийом заміни фактичних групових середніх обчисленими за рівнянням регресії називають вирівнюванням рядів.
Приклад. Обчислення теоретичних групових середніх за рівнянням регресії. Згідно формулі (60), теоретичні значення групових середніх визначають за рівнянням:

Для попереднього прикладу обчислено: середнє число рослин на ділянці  ; середній врожай рослини
; середній врожай рослини  г; =–1,18 г на рослину. Підставляючи ці величини в рівняння, знаходимо
г; =–1,18 г на рослину. Підставляючи ці величини в рівняння, знаходимо  . Обчислення Y0 наведено в табл. 32.
. Обчислення Y0 наведено в табл. 32.
Таблиця 32 – Обчислення теоретичних значень Y0 за рівнянням лінійної регресії
| Число рослин на ділянці (Х) | 1,18Х | Y0 (69,7–1,18Х) | Фактичні групові середні
| 

| 
|
| 21,2 | 48,5 | 50,6 | –2,1 | 4,41 | |
| 22,4 | 47,3 | 46,9 | 0,4 | 0,16 | |
| 23,6 | 46,1 | 45,7 | 0,4 | 0,16 | |
| 24,8 | 44,9 | 44,2 | 0,7 | 0,49 | |
| 26,0 | 43,7 | 43,8 | –0,1 | 0,01 | |
| 27,1 | 42,6 | 43,3 | –0,7 | 0,49 | |
| 28,3 | 41,4 | 41,5 | –0,1 | 0,01 | |
| 29,5 | 40,2 | 40,0 | 0,2 | 0,04 | |
| 30,7 | 39,0 | 37,7 | 1,3 | 1,69 | |
| ∑ | 7,46 |
На рис. 11 пунктиром показана теоретична лінія регресії.
В табл. 32 розраховані Y0, що спостерігаються в цьому досліді значенні X. Аналогічним чином можна обчислити Y0 для будь-якого іншого X. Так, для 17 рослин очікуваний середній врожай рослини буде Y0=69,7–1,18×17=49,6 г, для 30 рослин – 34,3 г і т.д.
Величини d табл. 32 є відхиленнями теоретичної лінії регресії від емпіричної, або як кажуть, відхилення від регресії. Вони дозволяють оцінити помилку, що виникає при підборі лінії регресії.
4. Оцінка істотності регресії. При регресійному аналізі проводять зазвичай дві оцінки вибіркових коефіцієнтів регресії: а) оцінку величини відхилень від лінії регресії і б) оцінку істотності b, тобто значущість його відхилення від нуля. Оцінка відхилення від регресії має наступний сенс. Оскільки всі величини, складові рівняння регресії, отримані в результаті вибіркового спостереження, то для Y0 властиві випадкові коливання, тобто вони обчислені з якоюсь помилкою. З попереднього матеріалу відомо, що помилку спостережень краще всього характеризує середнє квадратичне відхилення, яке в даному випадку визначається як відхилення від регресії за формулою (64):
 (64)
(64)
Для прикладу  . Величина
. Величина 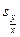 або
або  буде тим менше, чим менше розбіжність між фактичними і обчисленими груповими середніми. Оцінка істотності коефіцієнта регресії дозволяє переконатися в тому, що залежність між ознаками, що співставляються, не випадкова, а статистично значуща. Критерій істотності для коефіцієнта регресії
буде тим менше, чим менше розбіжність між фактичними і обчисленими груповими середніми. Оцінка істотності коефіцієнта регресії дозволяє переконатися в тому, що залежність між ознаками, що співставляються, не випадкова, а статистично значуща. Критерій істотності для коефіцієнта регресії  при k=n–2.
при k=n–2.
Квадратична помилка коефіцієнта регресії  (65).
(65).
У нашому прикладі  , а
, а 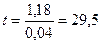 .
.
Отже, при найстрогішому підході до оцінки результатів досліду фактичний коефіцієнт регресії слід визнати таким, що істотно відхиляється від нуля.
5. Вирівнювання емпіричних рядів регресії. Графічний метод. Аналіз графічного зображення регресії може дати уявлення про форму та її напрям. Якщо до завдання експерименту входить елімінація випадкових коливань емпіричної регресії і встановлення загального напряму залежності, то якнайкращим методом є графічне вирівнювання ряду. Графічний метод вирівнюванні зручніше використовувати для лінійних залежностей. Складнішим є вирівнювання криволінійних графіків. У будь-якому випадку спочатку будується графік емпіричної залежності. Далі між крайніми значеннями ламаної лінії проводиться пряма або плавна крива так, щоб сума відстаней від точок теоретичної (вирівняної) лінії регресії до точок емпіричної лінії регресії була найменшою (рис. 12).


––––– – емпірична лінія регресії; –––○––○–– – теоретична лінія регресії
а – лінійна залежність; б – криволінійна залежність
Рис. 12 – графічний метод вирівнювання емпіричних рядів регресії
Слід пам'ятати, що графічним методом можна лише приблизно вирівняти емпіричні ряди. Якщо необхідно точніше вирівнювання, використовують аналітичні методи (метод ковзаючої середньої та зваженої ковзаючої середньої).
Метод ковзаючої середньої. Отримані емпіричним шляхом значення уi розташовані за фіксованими значеннями хi, замінюють новими, отриманими усереднюванням трьох або п'яти розташованих поряд значень уi (суму перших у ряді трьох або п'яти дат ділять відповідно на 3 або 5). Для набуття наступних значень у/ беруть нові 3 або 5 значень уi, зсунутих на одиницю, що можна записати у вигляді формул (66–69):
 (66)
(66)  (67) і т.д.,
(67) і т.д.,
або 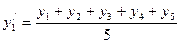 (68)
(68)  (69) і т.д.
(69) і т.д.
Недолік методу полягає в тому, що втрачаються значення крайніх варіант. Якщо об'єм вибірок великий, то така втрата не позначається істотно на подальшій роботі. Коли об'єми вибірок малі (4–10 варіант), тоді втрата хоч би однієї з них істотно впливає на подальшу роботу.
Точніші й не пов'язані з втратою крайніх значень результати можна отримати, використовуючи метод зваженої ковзаючої середньої. У цьому методі з обох кінців ряду додаються по два нових члени. Вони визначаються таким чином. Перше з початку або з кінця ряду помножається на 2, до отриманої середньої додається наступне (попереднє) у ряді значень, третє значення пропускається, а від отриманої суми віднімають четверте значення. Отриману величину ділять на 2. Це буде перше додаткове значення. Це може бути записано такими формулами:
 (70)
(70)  (71)
(71)
 (72)
(72)  (73)
(73)
Якщо емпіричні ряди короткі, то для обчислення краще використовувати формули:
 (74)
(74)  (75)
(75)
 (76)
(76)  (77)
(77)
Вирівняні значення отримують шляхом обчислення зваженої середньої з п'яти сусідніх емпіричних значень, узятих з відповідними коефіцієнтами 1; 2; 4; 2; 1. Набутого значення ділять на 10. Наприклад  , можна отримати за формулою (78):
, можна отримати за формулою (78):
 (78)
(78)
Інші значення отримують аналогічно, зсовуючи кожного разу емпіричний ряд на одиницю, тобто для обчислення  беруть значення у–1, у1, у2, у3 і у4 і т. д. Цей метод є найбільш точним методом вирівнювання і не призводить до втрати варіант.
беруть значення у–1, у1, у2, у3 і у4 і т. д. Цей метод є найбільш точним методом вирівнювання і не призводить до втрати варіант.
Приклад. Необхідно провести вирівнювання емпіричного ряду з 6 варіант:
12,3; 18,5; 18,9; 24,5; 30,6;30,7
Середнє арифметичне дорівнює 22,58. Оскільки ряд маленький і втрата хоч би однієї з дат може привісить до значної помилки, використовуємо метод зваженої ковзаючої середньої. Спочатку обчислюють додаткові дані:
 ;
;
 ;
;
 ;
;

Після розрахунку ряд буде виглядати так:
6,0; 9,3; 12,3; 18,5; 18,9; 24,5; 30,6; 30,7; 36,55; 39,65.
Далі, використовуючи додаткові дані, обчислюють вирівняні значення ряду . Для цього застосуються усереднювання п'яти сусідніх даних з відповідними коефіцієнтами: 1; 2; 4; 2; 1.




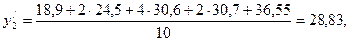
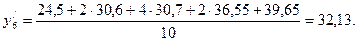
В результаті буде отриманий вирівняний ряд регресії, який складається з таких варіант:
12,97; 17,02; 20,45; 24,62; 28,83; 32,13
Середня арифметична цього ряду складає 22,67, тобто вона достатньо близька до середньої арифметичної початкового ряду.
6. Обчислення коефіцієнтів рівняння лінійної регресії. Якщо необхідно встановити закономірності зміни значень результативної ознаки від значень незалежної змінної, необхідно обчислити коефіцієнти рівняння регресії. Таке рівняння дозволяє обчислити теоретичні значення результативної ознаки. Закономірності зміни значення результативної ознаки можуть бути різними. Тому рівняння регресії можуть бути лінійними, гіперболічними, логарифмічними і т. д.
Найпростішим є рівняння прямолінійної регресії, яке виражається за формулою (79):
 (79)
(79)
де  – теоретичне (очікуване) значення результативної ознаки; b0 – вільний член рівняння регресії; b1 – коефіцієнт пропорційності; xi – не залежна змінна.
– теоретичне (очікуване) значення результативної ознаки; b0 – вільний член рівняння регресії; b1 – коефіцієнт пропорційності; xi – не залежна змінна.
Робочі формули, за якими проводиться обчислення коефіцієнтів рівняння наступні:
 (80)
(80)
 (81)
(81)
Коефіцієнт пропорційності обчислюється з певною помилкою, яку можна обчислити за формулою (82):
 (82)
(82) 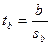 (83)
(83)
Якщо значення tb обчислене за формулою (83) дорівнює або перевищує стандартне значення критерію Ст’юдента (tтабл) для числа ступенів свободи f=k–1 і вибраного рівня значущості α, коефіцієнт пропорційності достовірно відрізняється від 0 для вибраного рівня значущості. Точки емпіричної лінії регресії практично ніколи не будуть знаходиться на прямій лінії, тому лінія регресії є такою прямою, яка проходить найближче до всіх точок емпіричного ряду.
Приклад. Вивчали залежність швидкості росту міцелію гриба від температури (18–30 ±°С) (табл. 33).
Таблиця 33 – Залежність швидкості росту міцелію гриба від температури
| № | Температура ºС (Х) | Швидкість росту (Y), мм за сутки | х2 | х·у |
| Сума |

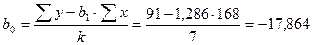


Коефіцієнт пропорційності достовірно відрізняється від 0 і повинен бути використаний у рівнянні регресії.

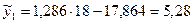 ;
;  ;
;
 ;
;  ;
;  ;
;  ;
;  .
.
7. Обчислення коефіцієнтів рівнянь регресії при нелінійних залежностях. У більшості випадках залежності змін результативної ознаки від зміни значення незалежної змінної мають нелінійний характер. Найчастіше зустрічаються гіперболічна, ступенева, параболічна і логістична залежності.
А. Гіперболічна залежність. Вона часто зустрічається в практиці біологічних досліджень. Наприклад, залежність росту проростків на забрудненому ґрунті від концентрації забруднювачів. Може бути виражена наступним рівнянням:
 або
або  (84)
(84)
Для обчислення коефіцієнтів рівняння складається система нормальних рівнянь (85):


 (85)
(85)
 (86)
(86) 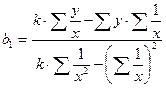 (87)
(87)
де b0 – вільний член рівняння регресії; b1 – коефіцієнт пропорційності; k – число пар даних; 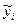 – очікуване значення результативної ознаки.
– очікуване значення результативної ознаки.
| № | х | у | у/х | 1/х | 1/х2 |
| Сума |
Далі обчислюють помилку коефіцієнта пропорційності (b1) і перевіряють його значущість (tb) за критерієм Ст’юдента.
Б. Показова (експоненціальна) функція. У випадках, якщо основна тенденція зміни значень емпіричного ряду близька до геометричної прогресії, вона описується рівнянням показової або експоненціальної функції.
 або
або  (88)
(88)
У цих рівняннях функції необхідно привести до виду лінійних. Для цього їх логарифмують.
 або
або  (89)
(89)
 (90)
(90)  (91)
(91)
В. Ступенева функція. В деяких випадках залежність між біологічними процесами описується рівнянням ступеневої функції:
 (92)
(92)
При логарифмуванні цього рівняння його одержимо
 (93)
(93)
 (94)
(94)
 (95)
(95)
Г. Параболічна залежність. Вона виражається квадратичними, кубічними і рівняннями вищого ступеня. Розглянемо метод рішення рівняння другого ступеня (або квадратичної залежності), яке виражається формулою:
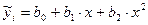 (96)
(96)
Така залежність достатньо задовільно характеризує процеси, які мають один максимум або один мінімум. Наприклад, вплив вмісту деяких речовин у ґрунті на ріст рослин. Так, сірка і мікроелементи за маленьких концентрацій обумовлюють поліпшення ростових процесів рослин. Вищі за оптимальні концентрації викликають пригнічення росту до загибелі рослин, тобто ці елементи стають токсикантами.
 (97)
(97)  (98)
(98)  (99)
(99)

