




Важнейшим элементом оценки качества выбранной модели является анализ автокорреляции в остатках, т.е. в отклонениях исходных значений динамического ряда от рассчитанных по уравнению тренда. Если аппроксимация удовлетворительная, то случайные составляющие – отклонения от тренда  в своей последовательности должны быть лишены автокорреляции.
в своей последовательности должны быть лишены автокорреляции.
Рассчитаем коэффициенты автокорреляции в остатках выбранного (лучшего) уравнения тренда. Значения остатков можно получить из таблицы Predicted & Residuals Values, столбца Residual Value, созданной в главе, посвященной аналитическому сглаживанию динамических рядов (см. рис. 3.19). Для этого делаем данный лист по линейной модели (в нашем случае лучшей) активным и запускаем знакомую процедуру Statistics/Advanced Linear/Nonlinear Models/Times Series/Forecasting, а в качестве переменной выбираем Residuals (рис. 3.30). Далее нажимаем кнопку OK (transformations, autocorrelations, crosscorrelations, plots) и переходим на закладку Autocorrs (рис. 3.31).
Рис. 3.30. Выбор остатков для анализа автокорреляции

Рис. 3.31. Закладка Autocorrs процедуры Transformations of Variables
В тематической области Autocorrelations & Crosscorrelations в левой стороне диалогового окна расположены три кнопки: Autocorrelations, Partial autocorrelations, Crosscorrelations, при нажатии на которые STATISTICA выводит на экран табличные и графические результаты расчета соответственно автокорреляций, частных автокорреляций и кросс-корреляций с количеством лагов от 1 до числа, указанных в поле Number of lags.
Установим число лагов равное 3. Значение в поле p-level for highlighting, определяющее уровень значимости оставим без изменений ( ). Далее убираем метку с поля White noise standard errors. Если метка в этом поле поставлена, то STATISTICA изменяет стандартный алгоритм расчета стандартных ошибок на модифицированный вариант, основанный на предположении о том, что все автокорреляции равны нулю. Далее нажимаем кнопку Autocorrelations.
). Далее убираем метку с поля White noise standard errors. Если метка в этом поле поставлена, то STATISTICA изменяет стандартный алгоритм расчета стандартных ошибок на модифицированный вариант, основанный на предположении о том, что все автокорреляции равны нулю. Далее нажимаем кнопку Autocorrelations.
В дереве рабочей книги появятся график и таблица с одинаковым названием Autocorrelation Functions. Таблица (рис. 3.32) содержит расчетные значения коэффициентов автокорреляции (столбец Autocorrelations), стандартных ошибок (Standard Errors), так называемых Box & Ljung статистик и расчетного уровня значимости P. При этом система также дает подсказки пользователю: если строка выделена красным цветом, то коэффициент корреляции на данном лаге является статистически значимым.
График (рис. 3.33) содержит графическое изображение статистик, рассмотренных в таблице. При этом горизонтальные столбцы означают коэффициенты корреляции. Графическое представление рассчитанных коэффициентов автокорреляции наглядно демонстрирует, что они статистически незначимы, поскольку значения ни одного из них не выходят на границы доверительных интервалов, обозначенных на графике красной пунктирной линией.

Рис. 3.32. Таблица коэффициентов автокорреляции
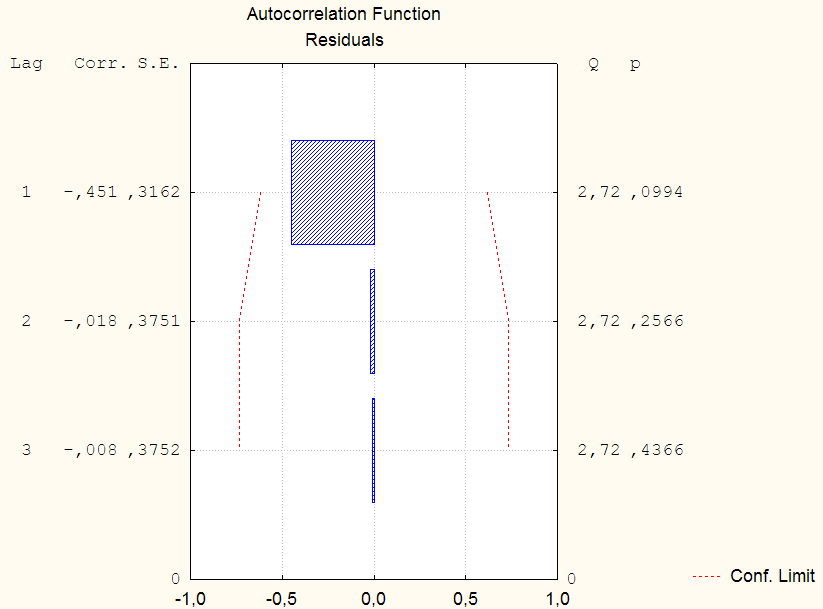
Рис. 3.33. Графическое изображение анализа автокорреляции в остатках
Автокорреляция признается значимой, если  . Для того, чтобы получить теоретические значения коэффициентов корреляции воспользуемся вероятностным калькулятором: Statistics/Probability Calculator/Correlations… (рис. 3.34). В появившемся окне (рис. 3.35) ставим метку в поле Two-tailed (двусторонний критерий), ставим метку в поле Compute r from p (посчитать коэффициент корреляции исходя из уровня значимости), в поле N заносим число уровней ряда (в нашем случае 10), в поле p заносим уровень значимости (), далее нажимаем на кнопку Compute, и в поле r появляется теоретическое значение коэффициента корреляции. Сопоставив его с расчетными значениями на трех лагах, делаем вывод о незначимости коэффициентов корреляции и отсутствии автокорреляции в остатках.
. Для того, чтобы получить теоретические значения коэффициентов корреляции воспользуемся вероятностным калькулятором: Statistics/Probability Calculator/Correlations… (рис. 3.34). В появившемся окне (рис. 3.35) ставим метку в поле Two-tailed (двусторонний критерий), ставим метку в поле Compute r from p (посчитать коэффициент корреляции исходя из уровня значимости), в поле N заносим число уровней ряда (в нашем случае 10), в поле p заносим уровень значимости (), далее нажимаем на кнопку Compute, и в поле r появляется теоретическое значение коэффициента корреляции. Сопоставив его с расчетными значениями на трех лагах, делаем вывод о незначимости коэффициентов корреляции и отсутствии автокорреляции в остатках.

Рис. 3.34. Запуск вероятностного калькулятора для оценки значимости автокорреляции
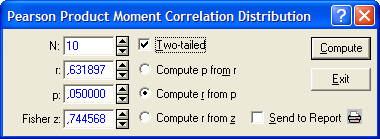
Рис. 3.35. Оценка теоретических значений коэффициентов корреляции Пирсона
Оценка также может быть осуществлена исходя из уровня значимости принятия нулевой гипотезы. Нулевая гипотеза в данном случае формулируется как утверждение о незначимости коэффициента автокорреляции:  . Гипотеза принимается при условии, что
. Гипотеза принимается при условии, что  . По результатам нашего анализа нулевая гипотеза не отклоняется, поскольку для всех коэффициентов автокорреляции
. По результатам нашего анализа нулевая гипотеза не отклоняется, поскольку для всех коэффициентов автокорреляции  . Следовательно, автокорреляция в остатках анализируемого уравнения тренда отсутствует, что свидетельствует о возможности использования его для прогнозирования.
. Следовательно, автокорреляция в остатках анализируемого уравнения тренда отсутствует, что свидетельствует о возможности использования его для прогнозирования.
Отметим, что если бы в линейной модели была бы обнаружена автокорреляция в остатках, следовало бы выбрать другую модель (со значимыми параметрами и следующим по ранжиру коэффициентом детерминации) и проанализировать автокорреляцию остатках в ней.

