




Традиционный метод проверки однородности (критерий Стьюдента). Для дальнейшего критического разбора опишем традиционный статистический метод проверки однородности. Вычисляют средние арифметические в каждой выборке
 ,
,
затем выборочные дисперсии
 ,
, 
и статистику Стьюдента t, на основе которой принимают решение,
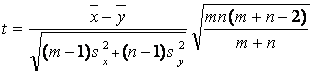 . (1)
. (1)
По заданному уровню значимости a и числу степеней свободы (m+n _ 2) из таблиц распределения Стьюдента находят критическое значение tкр. Если |t|>tкр, то гипотезу однородности (отсутствия различия) отклоняют, если же |t| < tкр, то принимают. (При односторонних альтернативных гипотезах вместо условия |t|>tкрпроверяют, что t>tкр; эту постановку рассматривать не будем, так как в ней нет принципиальных отличий от обсуждаемой здесь.)
Рассмотрим условия применимости традиционного метода проверки однородности, основанного на использовании статистики t Стьюдента, а также укажем более современные методы.
Вероятностная модель порождения данных. Для обоснованного применения эконометрических методов необходимо прежде всего построить и обосновать вероятностную модель порождения данных. При проверке однородности двух выборок общепринята модель, в которой x1, x2,...,xm рассматриваются как результаты m независимых наблюдений некоторой случайной величины Х с функцией распределения F(x), неизвестной статистику, а y1, y2,...,yn - как результаты п независимых наблюдений, вообще говоря, другой случайной величины Y с функцией распределения G(x), также неизвестной статистику. Предполагается также, что наблюдения в одной выборке не зависят от наблюдений в другой, поэтому выборки и называют независимыми. Возможность применения модели в конкретной реальной ситуации требует обоснования. Независимость и одинаковая распределенность результатов наблюдений, входящих в выборку, могут быть установлены или исходя из методики проведения конкретных наблюдений,или путем проверки статистических гипотез независимости и одинаковой распределенности с помощью соответствующих критериев. Если проведено (т+п) измерений объемов продаж в (т+п) торговых точках, то описанную выше модель, как правило, можно применять. Если же, например, xi и yi - объемы продаж одного и того же товара до и после определенного рекламного воздействия, то рассматриваемую модель применять нельзя. (В этом случае используют модель т.н. связанных выборок, в которой обычно строят новую выборку zi = xi - yi и используют статистические методы анализа одной выборки, а не двух. Проверка однородности для связанных выборок рассматривается ниже.) При дальнейшем изложении принимаем описанную выше вероятностную модель двух выборок.
Содержание этапа спецификации эконометрической модели.
Спецификация модели— один из этаповпостроения экономико - математической модели, на котором, на основании предварительного анализарассматриваемого экономического объекта или процесса, в математической форме выражаютсяобнаруженные связи и соотношения, а значит параметры и переменные, которые на данном этапепредставляются существенными для цели исследования. Иными словами, В эконометрических моделях производится также спецификация ошибки, т.е. выбор некоторого типа распределения для случайного элемента модели, подлежащего оцениванию.
Ошибкойспецификации называются: неправильный выбор типа связей и соотношений между элементамимодели, а также выбор, в качестве существенных, таких переменных и параметров, которые на самом делетаковыми не являются, и наконец, отсутствие в модели некоторых существенных переменных.
Содержание этапа идентификации модели.
Идентификация – это единственность соответствия между приведенной и структурной формами модели.
С позиции идентифицируемости структурные модели можно подразделить на три вида:
1) идентифицируемые;
2) неидентифицируемые;
3) сверхидентифицируемые.
Модель идентифицируема, если все структурные ее коэффициенты определяются однозначно, единственным образом по коэффициентам приведенной формы модели, т. е. если число параметров структурной модели равно числу параметров приведенной формы модели. В этом случае структурные коэффициенты модели оцениваются через параметры приведенной формы модели и модель идентифицируема.
Модель неидентифицируема, если число приведенных коэффициентов меньше числа структурных коэффициентов, и в результате структурные коэффициенты не могут быть оценены через коэффициенты приведенной формы модели.
Модель сверхидентифицируема, если число приведенных коэффициентов больше числа структурных коэффициентов. В этом случае на основе коэффициентов приведенной формы можно получить два или более значений одного структурного коэффициента. В этой модели число структурных коэффициентов меньше числа коэффициентов приведенной формы. Сверхидентифицируемая модель в отличие от неидентифицируемой модели практически решаема, но требует для этого специальных методов исчисления параметров.
Структурная модель всегда представляет собой систему совместных уравнений, каждое из которых требуется проверять на идентификацию. Если хотя бы одно из уравнений системы неидентифицируемо, то и вся модель считается неидентифицируемой. Модель считается идентифицируемой, если каждое уравнение системы идентифицируемо. Сверхидентифицируемая модель содержит хотя бы одно сверхидентифицируемое уравнение.
Содержание этапа верификации эконометрической модели.
Верификация модели. Проводится проверка истинности, адекватности модели. Выясняется, насколько удачно решены проблемы спецификации, идентификации и идентифицируемости модели, какова точность расчетов по данной модели, в конечном счете, насколько соответствует построенная модель моделируемому реальному экономическому объекту или процессу. Обсуждение указанных вопросов проводится в большинстве глав настоящего учебника.
Следует заметить, что если имеются статистические данные, характеризующие моделируемый экономический объект в данный и предшествующие моменты времени, то для верификации модели, построенной для прогноза, достаточно сравнить реальные значения переменных в последующие моменты времени с соответствующими их значениями, полученными на основе рассматриваемой модели по данным предшествующих моментов.
Приведенное выше разделение эконометрического моделирования на отдельные этапы носит в известной степени условный характер, так как эти этапы могут пересекаться, взаимно дополнять друг друга.
Содержание этапа идентификации ошибок спецификации эконометрической модели.
Идентификация – это единственность соответствия между приведенной и структурной формами модели.
С позиции идентифицируемости структурные модели можно подразделить на три вида:
1) идентифицируемые;
2) неидентифицируемые;
3) сверхидентифицируемые.
Модель идентифицируема, если все структурные ее коэффициенты определяются однозначно, единственным образом по коэффициентам приведенной формы модели, т. е. если число параметров структурной модели равно числу параметров приведенной формы модели. В этом случае структурные коэффициенты модели оцениваются через параметры приведенной формы модели и модель идентифицируема.
Модель неидентифицируема, если число приведенных коэффициентов меньше числа структурных коэффициентов, и в результате структурные коэффициенты не могут быть оценены через коэффициенты приведенной формы модели.
Модель сверхидентифицируема, если число приведенных коэффициентов больше числа структурных коэффициентов. В этом случае на основе коэффициентов приведенной формы можно получить два или более значений одного структурного коэффициента. В этой модели число структурных коэффициентов меньше числа коэффициентов приведенной формы. Сверхидентифицируемая модель в отличие от неидентифицируемой модели практически решаема, но требует для этого специальных методов исчисления параметров.
Структурная модель всегда представляет собой систему совместных уравнений, каждое из которых требуется проверять на идентификацию. Если хотя бы одно из уравнений системы неидентифицируемо, то и вся модель считается неидентифицируемой. Модель считается идентифицируемой, если каждое уравнение системы идентифицируемо. Сверхидентифицируемая модель содержит хотя бы одно сверхидентифицируемое уравнение.
13.Задача идентификации факторной регрессионной модели и методы её решения. Построение регрессионной модели предполагает решение двух задач. Первая заключается в выборе состава независимых переменных и класса функции f(x). Этот этап называется исходной спецификацией модели. Она подразумевает, прежде всего: -
выделение состава экзогенных переменных; -
обоснование характера возможных взаимосвязей между эндогенной и экзогенными переменными (в том числе корреляционный анализ); -
обоснование возможных трансформаций представления исходных данных; -
исходное тестирование экзогенных переменных
Данный перечень задач решается на основе формально-логического анализа взаимосвязи переменных, корреляционного анализа, анализа специальных характеристик динамических рядов (см.п.2.3.2.), с помощью соответствующих статистических тестов и т.д. Для трендовых моделей для решения этой задачи полезно применить сглаживание исходного временного ряда.
Вторая важнейшая задача на стадии построения модели, – фактическое оценивание параметров функции f(x), в частности, в случае линейной регрессии – параметров.
Методы оценивания параметров уравнения регрессии является конкретной реализацией общего принципа максимума правдоподобия. Сформулируем его следующим образом. Наилучшим описанием явления является то, которое дает наибольшую вероятность получения в результате измерений именно те значения, которые и были фактически получены. Специальные рекомендации по построению так называемой функции правдоподобия даются в зависимости от специфических характеристик распределения случайной ряда зависимой переменной.
Так, например, при нормальном или близком к нему распределении случайной ряда (т.н. распределение Гаусса), идентификация проводится непосредственно методом максимального правдоподобия либо методом наименьших квадратов (МНК). Если же, например, распределение подчинено закону Лапласа предпочтение отдается методу наименьших модулей (МНМ) и т.д.

