




Алгоритм ОРО определяет стратегию подбора весов МСП с применением градиентных методов оптимизации и считается одним из наиболее эффективных алгоритмов обучения НС. Его основу составляет целевая функция вида (4.1). Уточнение весов может проводиться многократно после предъявления каждой обучающей пары  (режим «online») либо однократно после предъявления всех выборок, составляющих цикл обучения (режим «offline»). Формула для уточнения вектора весов имеет вид
(режим «online») либо однократно после предъявления всех выборок, составляющих цикл обучения (режим «offline»). Формула для уточнения вектора весов имеет вид
 (4.4)
(4.4)
где  – направление в многомерном пространстве
– направление в многомерном пространстве  . Для правильного выбора необходимо определение вектора градиента относительно весов всех слоев сети, однако эта задача имеет очевидное решение только для весов выходного слоя. Для других слоев используется алгоритм ОРО, в соответствии с которым каждый цикл обучения состоит из следующих этапов:
. Для правильного выбора необходимо определение вектора градиента относительно весов всех слоев сети, однако эта задача имеет очевидное решение только для весов выходного слоя. Для других слоев используется алгоритм ОРО, в соответствии с которым каждый цикл обучения состоит из следующих этапов:
1. По значениям компонент xj входного вектора  расчет выходных сигналов
расчет выходных сигналов  всех слоев сети, а также соответствующих производных
всех слоев сети, а также соответствующих производных 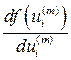 функций активации каждого слоя (m – число слоев НС).
функций активации каждого слоя (m – число слоев НС).
2. Создание сети ОРО путем замены выхода на вход, функций активации – их производными, входного сигнала – разностью  .
.
3. Уточнение весов на основе результатов пп.1, 2 для оригинальной НС и сети ОРО.
4. Повторение процесса для всех обучающих выборок вплоть до выполнения условия остановки обучения (снижения нормы градиента до заданного e, выполнения определенного количества шагов и т.п.).
Рассмотрим метод ОРО более подробно, полагая НС с одним скрытым слоем и режим обучения «online», когда  определяется только одной обучающей парой. С учетом обозначений рис. 4.2
определяется только одной обучающей парой. С учетом обозначений рис. 4.2
 (4.5)
(4.5)
откуда для компонентов градиента относительно выходного слоя получаем
 (4.6)
(4.6)
Аналогично, для нейронов скрытого слоя
 (4.7)
(4.7)
Обе полученные формулы имеют аналогичную структуру дающие описание градиента в виде произведения двух сигналов: первый соответствует начальному узлу данной взвешенной связи, второй – величине погрешности, перенесенной на тот узел, с которым эта связь установлена. В классическом алгоритме ОРО фактор задает направление отрицательного градиента, поэтому в выражении (4.4)
 (4.8)
(4.8)
4.3. Радиальные нейронные сети (RBF–НС)
Рассмотренные выше многослойные сигмоидальные НС ввиду характера своей функции активации осуществляют аппроксимацию глобального типа. Однако возможен и другой подход – путем адаптации одиночных аппроксимирующих функций к ожидаемым значениям, когда отображение всего входного множества представляет собой сумму локальных преобразований с помощью функций, принимающих ненулевые значения в ограниченной области пространства данных, т.е. локальную аппроксимацию. При этом особое семейство образуют НС, в которых скрытые нейроны описываются радиальными базисными функциями (RBF –Radial Basic Function)  , принимающие ненулевые значения только в окрестности выбранного центра
, принимающие ненулевые значения только в окрестности выбранного центра  . Эти сети представляют собой естественное дополнение сигмоидальных НС. Действительно, если сигмоидальный нейрон образует в многомерном пространстве гиперплоскость (рис. 4.3 а), то радиальный – гиперсферу (рис. 4.3 б), осуществляющую шаровое разделение пространства вокруг центральной точки, что в случае круговой симметрии входных данных позволяет значительно сократить число скрытых нейронов, необходимых для разделения различных классов.
. Эти сети представляют собой естественное дополнение сигмоидальных НС. Действительно, если сигмоидальный нейрон образует в многомерном пространстве гиперплоскость (рис. 4.3 а), то радиальный – гиперсферу (рис. 4.3 б), осуществляющую шаровое разделение пространства вокруг центральной точки, что в случае круговой симметрии входных данных позволяет значительно сократить число скрытых нейронов, необходимых для разделения различных классов.

Математическую основу функционирования RBF–НС составляет теорема Т.Ковера, согласно которой N –мерное входное пространство является j –разделяемым на два пространственных класса Х+ и Х–, если существует такой вектор весов , что
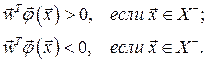 (4.9)
(4.9)
Граница между этими классами определяется уравнением  . Показано, что при достаточно большом числе скрытых нейронов К, реализующих радиальные функции
. Показано, что при достаточно большом числе скрытых нейронов К, реализующих радиальные функции 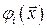 , решение задачи классификации гарантирует двухслойная НС, где скрытый слой реализует
, решение задачи классификации гарантирует двухслойная НС, где скрытый слой реализует  , а выходной слой состоит из одного или нескольких линейных нейронов, осуществляющих взвешенное суммирование сигналов, генерируемых скрытыми нейронами (рис. 4.4). Сеть функционирует по принципу многомерной интерполяции, состоящей в отображении р входных векторов
, а выходной слой состоит из одного или нескольких линейных нейронов, осуществляющих взвешенное суммирование сигналов, генерируемых скрытыми нейронами (рис. 4.4). Сеть функционирует по принципу многомерной интерполяции, состоящей в отображении р входных векторов  в множество из р рациональных чисел di (i =1,2,…, р), что возможно при р нейронах скрытого слоя и функции отображения
в множество из р рациональных чисел di (i =1,2,…, р), что возможно при р нейронах скрытого слоя и функции отображения  . Для RBF–НС с одним выходом (рис. 4.4) зависимость между входными и выходным сигналами может быть определена системой уравнений
. Для RBF–НС с одним выходом (рис. 4.4) зависимость между входными и выходным сигналами может быть определена системой уравнений
 (4.10)
(4.10)

где  определяет радиальную функцию с центром в точке с вынужденным вектором
определяет радиальную функцию с центром в точке с вынужденным вектором  . В сокращенной матричной форме система уравнений (4.10) может быть представлена как
. В сокращенной матричной форме система уравнений (4.10) может быть представлена как
 (4.11)
(4.11)
откуда для ряда радиальных функций с  может быть получено решение для вектора весов выходного слоя
может быть получено решение для вектора весов выходного слоя
 (4.12)
(4.12)
Математически точное решение (4.12) системы (4.10) при K = p совершенно неприемлемо с практической точки зрения по двум причинам:
1) наличие большого числа скрытых нейронов вызовет адаптацию НС к разного рода шумам или нерегулярностям, сопровождающим обучающие выборки, т.е. обобщающие свойства НС окажутся весьма слабыми;
2) при большой величине р вычислительная сложность обучающего алгоритма становится чрезмерной.
Поэтому чаще всего отыскивается субоптимальное решение в пространстве меньшей размерности K < p, которое с достаточной степенью точности аппроксимирует точное, т.е.
 (4.13)
(4.13)
где сi – множество центров RBF, которые необходимо определить (заметим, что при K = p можно положить  ).
).
Таким образом, задача обучения RBF–НС состоит в подборе определенного количества радиальных базисных функций, их параметров и весов wi таким образом, чтобы решение уравнения (4.13) оказалось наиболее близким к точному. Эту проблему можно свести к минимизации некоторой целевой функции, которую при использовании метрики Эвклида можно записать как
 (4.14)
(4.14)
Чаще всего в качестве RBF применяется функция Гаусса
 (4.15)
(4.15)
где 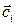 означает расположение центра
означает расположение центра  , а дисперсия si определяет ширину радиальной функции, т.е. процесс обучения при К << p сводится к:
, а дисперсия si определяет ширину радиальной функции, т.е. процесс обучения при К << p сводится к:
- подбору центров и дисперсий si радиальных функций (4.15);
- подбору весов wi нейронов выходного слоя.
Поскольку значения wi можно определить решением матрично–векторного уравнения типа (4.12), то главной проблемой обучения остается выбор и si, особенно центров RBF . Одним из простейших (хотя и не самых эффективных) методов является случайный выбор на основе равномерного распределения при  , где d – максимальное расстояние между . Очевидно, что ширина радиальных функций пропорциональна максимальному разбросу центров и уменьшается с ростом их количества.
, где d – максимальное расстояние между . Очевидно, что ширина радиальных функций пропорциональна максимальному разбросу центров и уменьшается с ростом их количества.
Среди специализированных методов выбора центров RBF прежде всего следует выделить алгоритмы самоорганизации, когда множество входных обучающих данных разделяется на кластеры, которые в дальнейшем представляются центральными точками, определяющими усредненные значения всех их элементов. Эти точки в дальнейшем выбираются в качестве центров соответствующих радиальных функций, т.е. количество RBF равно количеству кластеров. Для разделения данных на кластеры чаще всего используют алгоритм К –усреднений Линде–Бузо–Грея в прямом («online») или накопительном («offline») варианте. При этом начальные положения центров выбираются случайным образом на основе равномерного распределения, а затем производится их уточнение либо после предъявления каждого очередного (online), либо после предъявления всех элементов обучающего множества (offline). Если обучающие данные представляют непрерывную функцию, начальные значения в первую очередь размещают в точках экстремумов (максимумов и минимумов) функции, а оставшиеся центры распределяют равномерно среди незадействованных элементов обучающего множества.
В прямой версии («online») после подачи каждого обучающего вектора  выбирается ближайший к центр и подвергается уточнению в соответствии с алгоритмом WTA
выбирается ближайший к центр и подвергается уточнению в соответствии с алгоритмом WTA
 (4.16)
(4.16)
где h <<1 – коэффициент обучения, уменьшающийся с ростом t, а остальные центры не изменяются. Все обучающие предъявляются случайным образом по несколько раз, вплоть до стабилизации положения . В режиме «offline» уточнение положения всех происходит параллельно после подачи всех обучающих векторов согласно
 (4.17)
(4.17)
где Ni – количество , приписанных к в цикле t. На практике чаще применяется прямой алгоритм, имеющий несколько лучшую сходимость.
Основная трудность алгоритмов самоорганизации – выбор коэффициента обучения h. При h = const он должен быть очень малым, что, гарантируя сходимость алгоритма, непомерно увеличивает время обучения. Из адаптивных методов подбора h наиболее известен алгоритм Даркена–Муди, согласно которому
 (4.18)
(4.18)
где T – постоянная времени, индивидуальная для каждой задачи. Несмотря на то, что адаптивные методы выбора h более прогрессивны по сравнению с h = const, они также не могут считаться наилучшим решением, особенно при моделировании динамических процессов.
После фиксации положения производится подбор значений si таким образом, чтобы области охвата всех RBF накрывали все пространство входных данных, лишь незначительно перекрываясь друг с другом. Проще всего в качестве si выбрать эвклидово расстояние между и его ближайшим соседом  , т.е.
, т.е.  , но можно учитывать и более широкое соседство с помощью
, но можно учитывать и более широкое соседство с помощью
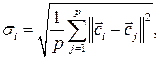 (4.19)
(4.19)
где обычно p Î[3,5]. Заметим, что существуют и другие алгоритмы обучения НС–RBF (вероятностный, гибридный, на основе ОРО), однако ни один из них не гарантирует 100% – ной оптимальности результата.
Поскольку RBF–НС используются для решения тех же задач (классификация, аппроксимация, прогнозирование), что и сигмоидальные НС, основной проблемой их корректного построения является оптимальный выбор количества скрытых нейронов. т.е. числа RBF. Как правило, величина К зависит от многих факторов, прежде всего от размерности , объема обучающих данных p и разброса  , т.е. пространственной структуры аппроксимируемой функции. Для подбора К используют:
, т.е. пространственной структуры аппроксимируемой функции. Для подбора К используют:
1) эвристические методы, использующие алгоритмы увеличения или уменьшения числа RBF по оценке динамики изменения ;
2) метод ортогонализации Грэма–Шмидта, когда при начальной фиксации К = р количество скрытых нейронов постепенно уменьшается путем выделения оптимального числа RBF, дающих наибольший вклад в энергетическую функцию , т.е. путем определения необходимой размерности , гарантирующей наилучшие результаты обучения.
Радиальные НС относятся к той же категории сетей, обучаемых с учителем, что и сигмоидальные НС (например, МСП), однако обнаруживают значительные отличия:
- RBF–НС имеют фиксированную структуру с одним скрытым слоем и линейными выходными нейронами;
- обобщающие способности радиальных НС несколько хуже ввиду глобального характера сигмоидальных функций активации;
- в отличие от сигмоид RBF могут быть весьма разнообразны, что увеличивает вероятность достижения успеха с их помощью;
- RBF–НС имеют более простой (и более быстрый) алгоритм обучения, поскольку этапы определения , si и можно разделить;
- возможность лучшего выбора начальных условий обучения радиальных НС увеличивает вероятность достижения глобального минимума ;
- радиальные НС обеспечивают лучшее решение классификационных задач.

