




Выборка может строиться как одно или многоступенчатая. При многоступенчатом отборе на каждой ступени меняется единица отбора. Например, на первой ступени производится отбор промышленных предприятий, на второй — отбор бригад на предприятиях, попавших в выборку на первой ступени, на третьей — отбор рабочих из бригад, попавших в выборку на второй ступени отбора, и т. д.
Необходимость многоступенчатого отбора вызвана, как правило, отсутствием информации о всех единицах генеральной совокупности. При многоступенчатом отборе для организации первой ступени необходимо иметь информацию о распределении' того или иного признака по всей совокупности единиц отбора первой ступени. Для организации второй ступени нужна уже только информация об отобранных единицах первой ступени.
На первой ступени, как правило, используется случайный отбор, а, начиная со второй ступени случайно отбирается количество единиц, пропорциональное размеру соответствующей единицы предыдущей ступени и т. д.
Доли отбора на каждой ступени комбинируются таким образом, чтобы в целом доля отбора выборки обеспечивала всем единицам генеральной совокупности равные шансы попасть в выборку.
Пропорциональный способ организации многоступенчатой выборки имеет определенные неудобства. Социолог, с одной стороны, уменьшает объем выборки в целях экономии средств и сокращения сроков проведения исследования, а с другой,— соблюдая принцип пропорциональности, он может получить очень малочисленные группировки по отдельным факторам, которые окажутся недостаточными для статистического анализа.
Существует несколько способов формирования многоступенчатых выборок.
Для примера рассмотрим способ организации двухступенчатой выборки, отбор единиц которой на первой ступени осуществляется с вероятностью, пропорциональной размеру. Воспользуемся для примера условиями и задачами организации выборки в известном исследовании ленинградских социологов.
Единицы первой ступени отбора — предприятия города.
Составляется полный список единиц наблюдений первой ступени отбора — промышленных предприятий и численности молодых рабочих на каждом из них. Генеральная совокупность включала 50 таких предприятий.

Единицы отбора ранжируются по численности рабочих, выделенных в качестве единиц наблюдения принимается решение о включении в выборку определенного числа заводов, например пяти. По таблице случайных чисел выбирается чисел (М1, М2, М3, М4 и М5)между N1 и N (общей кумулированной численностью рабочих в генеральной совокупности). В выборку включаются те предприятия, чьи номера оказались в той же строке (j), которая соответствует кумуляте, содержащей одно из чисел Мk k=1/5 т. е. i = f, если N1+N2+…+Nj-1< Мk < N1, + N2 +…+ Nj по всем k.
Вторая ступень отбора реализуется следующим образом. На каждом предприятии, включенном в выборку; выбирается одно и то же число рабочих (единиц второй ступени отбора). Далее отбор может быть случайным или систематическим.
Ошибка многоступенчатой выборки (на примере двухступенчатой выборки). При многоступенчатом отборе (начиная с двухступенчатого) следует учитывать специфику расчета ошибки выборки. Каждая ступень отбора делает свой «вклад» в отклонение находимых оценок от истинных значений характеристик в генеральной совокупности.
Для достаточно большого объема выборки существуют упрощенные формулы расчета средней ошибки.

где s21 —дисперсия единиц первой ступени отбора и n1 —их численность; n22 —дисперсия единиц второй ступени отбора и n2 — их численность в составе единиц первой ступени отбора в выборке.
В формуле учтены оба источника ошибок репрезентативности при двухступенчатом отборе. Первый член формулы под корнем указывает на дисперсию, вызванную формированием первой - ступени отбора. Второй член указывает на внутригрупповую дисперсию, связанную с организацией второй ступени выборки.
Упрощенность этой формулы состоит в том, что внутригрупповые дисперсии рассчитываются внутри каждой единицы первой ступени после отбора из нее единиц второй ступени. Здесь указана «невзвешенная» средняя из квадратов ошибок по всей сумме единиц второй ступени (n2). Это второй источник случайных ошибок.
Многофазовый отбор.
Многофазовый отбор является особым видом многоступенчатого отбора. Он заключаемся в том, что из сформированной выборки большего объема производится новая выборка (подвыборка) меньшего объема и т. д.
Особенностью этого способа формирования выборочной совокупности, является то, что независимо от числа фаз в последующих подвыборках используется неизменно одна и та же единица отбора, что и в основной выборке.
К многофазовому отбору, прибегают тогда, когда в рамках ис-4 следования, которое проводится на большой выборке, возникает необходимость тщательного изучения более узкого круга вопросов. Для этих целей формируется вторая фаза — та же выборка в миниатюре и т. д.
Как и в многоступенчатых выборках, при многофазовом отборе каждая фаза является источником случайных ошибок.
Пример двухфазовой стратифицированной выборки 7. В ходе исследования сельского населения возникла необходимость более углубленно изучить его культурные потребности и материальные затраты на «потребление культуры».
Основная выборка (n) была сделана из стратифицированной генеральной совокупности — изучаемый регион был разделен на 5 страт по типу хозяйств: от мелких (1)до самых крупных (5). Вторая фаза выборки (n2) была организована из этой основной..

|
При исчислении выборочных показателей по выборке необходимо учитывать оба компонента случайной ошибки (как и в случае двухступенчатого отбора), связанного со структурой выборки первой фазы (n) и второй фазы (nп).
Комбинированные выборки.
Соединение в многоступенчатой выборке различных приемов отбора (простого случайного, систематического или серийного) делает выборку комбинированной.
Как уже указывалось, большинство используемых в современных социологических исследованиях выборок являются комбинированными.
Одноступенчатая стратифицированная выборка. Комбинированная одноступенчатая выборка использовалась социологами ИСИ АН СССР при формировании выборочной совокупности для изучения индивидуальной производительности труда (индивидуальных норм выработки) рабочих сдельщиков.
Пример. На основе предварительного анализа пилотажного массива из шести возможных для формирования выборки признаков (возраст, образование, стаж по профессии и на данном заводе, заработная плата и квалификация) были выбраны два заработная плата и, стаж по профессии. Эти признаки обнаружили наибольшее влияние на изучаемый показатель — норму выработки8.
Генеральная совокупность была стратифицирована на 6 страт, различающихся уровнем заработной платы.
Отбор в стратах имел случайный характер — по распределению второго по «весу» признака (стаж по профессии).
Были известны следующие данные по генеральной совокупности.

где S2=m(1 — m), m-выборочная доля. Дисперсия качественного признака (выполнение нормы сдельщиками) при отсутствии информации была принята равной s2 = 0,5 • 0,5 =0,25. Доверительная вероятность 1 — a = 0,95; предельная ошибка репрезентативности D= 0,05.
В связи с тем что построение репрезентативной районированной выборки означает сохранение в выборке пропорции для групп генеральной совокупности, для определения размера групп выборочной
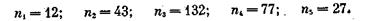
|
совокупности принимается следующий план9: ni/n=Ni/N, где N и n —
размеры соответственно генеральной совокупности и выборки; Ni и-
ni — размеры соответственно страт в генеральной и выборочной совокупностях. Рассчитывается численность каждой страты (представительство групп заработной платы) в выборке.
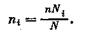
|
Пропорциональное построение выборки соответствовало следующим необходимым размерам групп:
Следующая стадия работы заключалась в расчете доли страт стажа. Для пропорционального построения выборки отбор по стажу следует согласовать с планом:

|
где Niq — численность каждой страты по стажу в отдельной страте-
по уровню зарплаты в генеральной совокупности, niq— соответственно для выборки.
Когда найдены эти доли для каждой страты по стажу, рассчитывается, сколько единиц наблюдения и с каким стажем должно
попасть из каждой такой страты в выборочную совокупность. На
пример, доля для стажа 1—2 года и заработной платы 60—80 руб.
равна 0,60, а для стажа 3—4 года в той же типической группе до
ля равна 0,40. Исходя из них, находим размер выборки для каждой
страты:
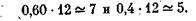
Аналогичный расчет производится по всем остальным стратам» В результате формируется план пропорциональной выборки в абсолютных числах и процентах (табл. 20).
По таблице случайных чисел выбираются случайные числа в соответствии о размером каждой группы, представленной в выборке (табл. 20). Предварительно картотека была стратифицирована по группам заработной платы и карточки пронумерованы. Из каждой группы выбирались карточки, соответствующие случайным числам. Если стаж на выбранной карточке должен был быть представлен в данной группы, карточка отбиралась в выборку. Если стаж не должен был быть представлен в данной группе, карточка возвращалась в генеральную совокупность.
Появление карточек, которые возвращались в массив, потребовало дополнительного выбора случайных чисел для каждой группы, пока не был обеспечен намеченный по плану размер. Как видно из

|
табл. 20, некоторые смещения оказались в группах с большим стажем. Но выборка репрезентативна по контролируемому признаку —
средней норме выработки: в генеральной совокупности — 109%,
в выборке — 108,9%. Рассчитаем по этой выборке оценку доли перевыполняющих план выработки в генеральной совокупности10 (табл. 21).
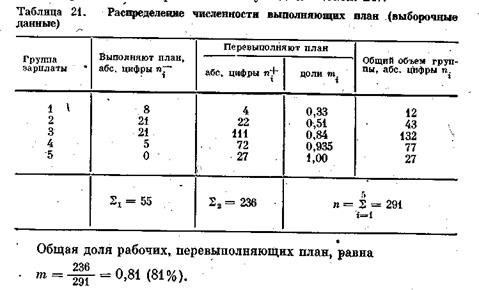
|
Чтобы использовать показатель доли по выборке как оценку соответствующего параметра в генеральной совокупности, необходимо рассчитать среднюю ошибку выборки.
Расчет дисперсии доли в стратифицированной выборке производится по формуле:

|
Расчет средней выборки производится по формуле:

|
При доверительной вероятности 0,95 предельная ошибка выборки D= ZM = 1,96 *0,0084 = 0,016, или 1,6%.
Таким образом, с вероятностью 0,95 можно утверждать, что доля перевыполняющих план будет в интервале (81 ± 1,6) %.

