




Случайной величиной называется измеряемая по ходу опыта численная характеристика, принимающая одно и только одно возможное и наперёд неизвестное значение вследствие действия различных факторов, которые не могут быть заранее учтены.
Дискретной называют случайную величину, множество возможных значений которой конечно либо счётно. Непрерывной называют случайную величину, которая может принимать все значения из некоторого конечного или бесконечного интервала.
Функцией распределения случайной величины называется функция, определяемая равенством
F(x) = P(X £ x)
где P(X £ x) - вероятность того, что случайная величина X примет любое значение, которое меньше или равно x.
Функция f(x) называется плотностью вероятности непрерывной случайной величины, если для любых чисел a и b (b > a) выполняется равенство
P(a < X < b) = 
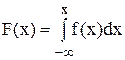

Явления, носящие случайный характер, также как и закономерные явления подчиняются определённым законам, с помощью которых можно определить, какова будет вероятность того, что случайная величина примет интересующее нас значение. Распределения вероятностей случайных величин могут быть дискретными и непрерывными. Наиболее важным непрерывным распределением вероятностей, используемых в аналитической химии, является нормальное распределение. Примерами одномерного нормального распределения являются идеальный хроматографический пик или полоса поглощения в электронном спектре.
Плотность вероятности нормально распределённой случайной величины описывается формулой:
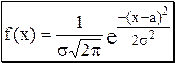
Графики плотности вероятности нормального распределения и функции нормального распределения показаны на рис. 10.3.

Рис. 10.3. Графики плотности вероятности (1) и функции (2) стандартного нормального распределения(2)
Любое нормальное распределение описывается двумя параметрами: параметр а по смыслу является математическим ожиданием случайной величины и характеризует положение графика функции f(x) относительно числовой оси, параметр s (s > 0), характеризующий растяжение (сжатие) графика, будучи возведённым в квадрат, равен дисперсии случайной величины. Нормальное распределение с а = 0 и s = 1 называется стандартным нормальным распределением.
Вероятность попадания значений нормально распределённой случайной величины в интервал a ± 3s составляет 99,73%, т.е. практически все значения нормально распределённой случайной величины находятся в этом интервале. Это свойство нормального распределения называется “ правилом 3s “.
Для характеристики случайной величины на практике пользуются выборкой. Выборкой называется последовательность независимых одинаково распределённых случайных величин. Выборка, пронумерованная в порядке возрастания, т.е. x1, x2... xn, называется вариационным рядом. Сами значения x называются вариантами, а n - объёмом выборки. В табл. 10.1 приведены основные характеристики, используемые для описания выборки.
Табл. 10.1.
Основные характеристики, используемые для описания выборки
| Характеристика | Определение понятия | Расчётная формула |
| выборочное среднее | сумма всех значений серии наблюдений, делённая на число наблюдений | 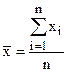
|
| выборочная дисперсия (исправленная) | сумма квадратов отклонений, делённая на число степеней свободы. Число степеней свободы f = n-1 - число переменных, которые могут быть присвоены произвольно при характеристике данной выборки | 
|
| выборочное стандартное отклонение | положительный квадратный корень из выборочной дисперсии | 
|
| стандартное отклонение выборочного среднего | отношение выборочного стандартного отклонения к положительному квадратному корню из числа наблюдений | 
|
| относительное стандартное отклонение | отношение выборочного стандартного отклонения к выборочному среднему | 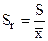
|
Чем меньше число степеней свободы (n-1), тем в большей степени выборочные характеристики отличаются от характеристик случайной величины. Для характеристики выборок малых объёмов (n < 30), взятых из нормально распределённых генеральных совокупностей, используют распределение Стьюдента (t-распределение), представляющее собой распределение случайной величины t
 (или
(или 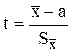 )
)
Данное распределение зависит только от объёма выборки и не зависит от неизвестных параметров a и s. При  распределение Стьюдента переходит в стандартное нормальное распределение.
распределение Стьюдента переходит в стандартное нормальное распределение.
Распределение Стьюдента можно использовать для расчёта доверительного интервала выборочного среднего (в том случае, если выборка имеет нормальное распределение). Доверительным интервалом называется интервал, вероятность попадания значений случайной величины в который равна принятой нами доверительной вероятности 1-a, где a - уровень значимости (в аналитической практике a = 0,05). Неизвестное математическое ожидание с вероятностью 1-a попадёт в интервал:

Например, если a = 0,05 и f = 5, то доверительный интервал для выборочного среднего равен ±2,57  .
.
10.6. Пример статистической обработки результатов измерений. Исключение промахов
Процесс анализа многостадиен. Каждая стадия вносит определённый вклад в неопределённость окончательного результата. Рассмотрим простейший вариант статистической обработки последней стадии анализа - измерения аналитического сигнала.
Пример 10.4. При измерении рН раствора с помощью рН-метра получены следующие результаты 4,32; 4,35; 4,36; 4,98; 4,38; 4,34. Провести статистическую обработку полученных результатов.
Перед началом статистической обработки необходимо проверить, не содержат ли полученные результаты грубых погрешностей. Измерения, в которых обнаружены такие погрешности, должны быть исключены. Их нельзя использовать при дальнейшей статистической обработке результатов. Существует несколько способов исключения грубых погрешностей. Для исключения промахов при работе с выборками малого объёма (n = 4 - 10) можно воспользоваться величиной Q-критерия. Для выборок больших объёмов можно использовать, например, «правило 3s» - если значение отличается от среднего более, чем на 3 стандартных отклонения, то его можно считать промахом.
Экспериментальное значение Q-критерия рассчитывают по следующим формулам:

Полученное значение сравнивают с критической (табличной) величиной для Q-критерия. Если оно превышает последнюю, то проверяемый результат является промахом и его необходимо исключить из дальнейших расчётов.
Преобразуем выборку, приведенную в примере 10.4, в вариационный ряд:

Последнее значение является явно подозрительным. Рассчитаем для него величину Q

Для n= 6 и P = 0,90 Qкрит = 0,48. Следовательно, результат рН = 4,98 является промахом и его необходимо исключить.
При обработке оставшихся данных с помощью формул, представленных в табл. 10.1, получены следующие результаты: 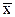 = 4,35;
= 4,35;  = 5,00×10-4;
= 5,00×10-4;  = 2,24×10-2;
= 2,24×10-2;  = 1,00×10-2;
= 1,00×10-2;  = 5,15×10-3;
= 5,15×10-3;  (a=0,05) = ±0,03. Таким образом, рН = 4,35±0,03.
(a=0,05) = ±0,03. Таким образом, рН = 4,35±0,03.
Обратите внимание, что окончательный результат среднего значения рН содержит столько же значащих цифр (3), сколько их присутствует в исходных данных. Величина, характеризующая доверительный интервал среднего, имеет столько же десятичных знаков (2), сколько и само среднее. Если бы мы привели в качестве результата, что-нибудь вроде 4,3500±0,028, то это было бы неверно.

