




Рис. 1.10. Пример возможного распределения случайных точек на плоскости.
Линейной среднеквадратической регрессией Y на X называется уравнение y = ax + b со значением параметров, при которых
j(a, b) = M[(aX + b) –Y)2] (1.41)
минимальна. Другими словами, среди всех прямых вида y = ax + b выбирается такая, для которой ((ax + b) – y)2 в среднем имеет наименьшее значение.
Приравнивая к нулю частные производные функции
j(a, b) = M[y2] + a2M[x2] + b2 – 2×a×M[x y] – 2×b×my + 2×a×b×mx
и решая полученную систему уравнений, находим точку минимума:
 ;
;  , (1.42)
, (1.42)
где mx и my – математические ожидания X и Y; 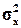 и
и  – дисперсии X и Y,
– дисперсии X и Y,
r =  ; Kxy = M[xy] – mxmy = M[(x – mx)(y – mx)]. (1.43)
; Kxy = M[xy] – mxmy = M[(x – mx)(y – mx)]. (1.43)
Таким образом, уравнением линейной среднеквадратической регрессии Y и X будет:
y = r  (x – mx) + my. (1.44)
(x – mx) + my. (1.44)
Аналогично, из условия минимума:
M[(a×Y + b – X)2] (1.45)
можно получить уравнение линейной среднеквадратической регрессии X на Y:
x = r  (y – my) + mx. (1.46)
(y – my) + mx. (1.46)
Отметим, что (1.46) не получается разрешением уравнение (1.44) относительно x. Поэтому выражения (1.44) и (1.46) определяют, вообще говоря, разные прямые. Объясняется это тем, что в выражении (1.41) расстояние между Y и aX + b измеряются вдоль оси Y, то есть по вертикали, а в выражении (1.45) расстояние между Х и aY + b измеряется вдоль оси х, то есть по горизонтали.
Число Кxy в выражении (1.43) называется ковариацией случайных величин X и Y, а число r =  – их коэффициентом корреляции. Отметим, что для любой системы случайных величин коэффициент корреляции удовлетворяет соотношению –1 £ r £ 1 и служит мерой линейной связи между Х и Y.
– их коэффициентом корреляции. Отметим, что для любой системы случайных величин коэффициент корреляции удовлетворяет соотношению –1 £ r £ 1 и служит мерой линейной связи между Х и Y.
Если r = 0, то Х и Y называются некоррелированными. В частности, некоррелированными являются независимые случайные величины. При r = 0 из выражений (1.44) и (1.46) получаем y = my и x = mx, то есть эти уравнения показывают, что линейной зависимости (даже приближенной) между X и Y нет. Напротив, если r=  1, то уравнения (1.44) и (1.46) выражают точную (не приближенную) зависимость. В этом случае мы имеем жёсткую линейную связь между Х и Y и все точки будут лежать на одной прямой. Остальные случаи являются промежуточными. Чем ближе |r| к единице, тем более выражена линейная связь между X и Y. Если r > 0, то угловой коэффициент в уравнении прямых регрессии положителен. Это означает, что с ростом одной из величин и другая в среднем увеличивается. Говорят, что между X и Y корреляция положительна. Соответственно, при отрицательной корреляции (r < 0) увеличение одной из величин ведёт в среднем к уменьшению другой. Положительная корреляция имеет место, например, между ростом и весом людей, а отрицательная между успеваемостью и продолжительностью досуга учащихся.
1, то уравнения (1.44) и (1.46) выражают точную (не приближенную) зависимость. В этом случае мы имеем жёсткую линейную связь между Х и Y и все точки будут лежать на одной прямой. Остальные случаи являются промежуточными. Чем ближе |r| к единице, тем более выражена линейная связь между X и Y. Если r > 0, то угловой коэффициент в уравнении прямых регрессии положителен. Это означает, что с ростом одной из величин и другая в среднем увеличивается. Говорят, что между X и Y корреляция положительна. Соответственно, при отрицательной корреляции (r < 0) увеличение одной из величин ведёт в среднем к уменьшению другой. Положительная корреляция имеет место, например, между ростом и весом людей, а отрицательная между успеваемостью и продолжительностью досуга учащихся.
На рис. 1.11 приведены различные возможные графики линейной регрессии при различных значениях коэффициента корреляции.
 |
Рис. 1.11. Графики линейной регрессии при r > 0, r < 0, r= 1, r = 0.
В уравнении регрессии (1.44) и (1.46) входят mx, my, sx, sy и r, которые можно найти, если известна совместная функция распределения Fxy(x, y) или плотность fxy(x, y). Если же имеется только выборка, то точные значения указанных величин приходится заменять их оценками. Оценки 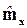 ,
,  ,
, 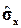 ,
,  уже рассмотрены нами в параграфе 1.4. Для оценки ковариации по выборке применяется формула [3]
уже рассмотрены нами в параграфе 1.4. Для оценки ковариации по выборке применяется формула [3]
 =
= 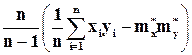 , (1.47)
, (1.47)
откуда получаем оценку:
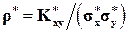 . (1.48)
. (1.48)
Отметим, что при больших n коэффициентом  в (1.47) можно пренебречь.
в (1.47) можно пренебречь.
Таким образом, окончательно получаем выборочные уравнения линейной среднеквадратической регрессии Y на X:
y = r*  (x –
(x – 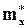 ) +
) + 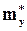 (1.49)
(1.49)
и X на Y:
x = r* (y – ) + . (1.50)
Отметим также, что прямые (1.49) и (1.50) получены по выборке, поэтому они, вообще говоря, отличаются от прямых (1.44) и (1.45). Однако сходимость оценок , , 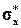 ,
,  , r* к их точным значениям при n ® ¥ обеспечивает сходимость выборочных уравнений регрессии (1.49) и (1.50) к (1.44) и (1.46).
, r* к их точным значениям при n ® ¥ обеспечивает сходимость выборочных уравнений регрессии (1.49) и (1.50) к (1.44) и (1.46).
Уравнения (1.49) и (1.50) можно получить другим способом, применяя метод наименьших квадратов, то есть из условия минимума средних квадратов отклонений точек выборки от линии регрессии:
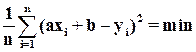 ,
,
(1.51)
 .
.
Уравнения же (1.44) и (1.46) получены из условия минимума математических ожиданий (1.41) и (1.45).
Отметим один важный момент. Применяя формулу (1.48), мы всегда получим какую-то оценку r* коэффициента корреляции r. Причём эта оценка обычно отлична от нуля, даже если r=0. Поэтому возникает вопрос о значимости выборочного коэффициента корреляции, полученного по формуле (1.48). То есть достаточно ли у нас оснований считать, что коэффициент корреляции не равен нулю, другими словами, имеется ли вообще корреляция между исследуемыми случайными величинами?
Для ответа на этот вопрос применяется следующий критерий. Пусть по выборке объёма n получено выборочное значение коэффициента корреляции r* и выдвинута гипотеза H0 = (r = 0). Для проверки этой гипотезы с уровнем значимости b вычисляется наблюдаемое значение
 (1.52)
(1.52)
и применяется решающее правило
 ® H0 принимается,
® H0 принимается,
(1.53)
 ® H0 отвергается,
® H0 отвергается,
где  – находится из таблицы критических точек распределения Стьюдента (Приложение 2). Входом в эту таблицу является уровень значимости b и число степеней свободы r = n – 2.
– находится из таблицы критических точек распределения Стьюдента (Приложение 2). Входом в эту таблицу является уровень значимости b и число степеней свободы r = n – 2.
Мы ограничились рассмотрением только линейной регрессии, то есть линейных приближённых зависимостей между X и Y. При необходимости можно рассмотреть более сложные зависимости. В общем случае выбирается некоторая функция y = g(x, a1, a2, …, ak), параметры а1, а2, …, ак которой могут бытьнайдены и методом наименьших квадратов из условия минимума среднего квадрата ошибок приближения:
 .
.
2. ЗАДАНИЕ ТИПОВОГО РАСЧЁТА.
1. Выбрать объект с двумя случайными параметрами Х и Y, собрать выборку объёма n = 100. Результат оформить в виде таблицы.
2. Составить две раздельные выборки для Х и Y.
3. Составить вариационные ряды для Х и Y.
4. Составить группированные выборки для X и Y с числом интервалов k = 8 – 10.
5. По полученным группированным выборкам построить гистограммы и полигон. Выбрать типы распределения X и Y. Использовать при этом только типы распределений из приложения 1.
6. Вычислить точечные оценки , ,  ,
,  , , ,
, , , 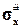 ,
,  ,.
,.
7. Найти 95% и 99% доверительные интервалы для mx и my.
8. Определить параметры теоретического закона распределения для Х и Y, используя метод моментов (кроме случая равномерного распределения).
9. Построить отдельно для Х и Y на одном графике гистограмму, полигон и теоретическую плотность распределения вероятностей. Графики построить очень аккуратно!
10. С уровнем значимости b = 0,01 проверить гипотезы о выбранных теоретических распределениях, используя критерий c2. Если все типы распределений из приложения 1 не будут приняты, то какие-либо другие распределения проверять не надо.
11. Построить выборочное уравнение линейной среднеквадратической регрессии Y на Х. Прямую регрессии y = ax + b изобразить совместно с графическим представлением выборки (каждая элемент выборки (xi, yi) изображается точкой на плоскости).
12. Проверить гипотезу о значимости выборочного значения коэффициента корреляции с уровнем значимости b = 0,01.
КОНТРОЛЬНЫЕ ВОПРОСЫ.
1. Функция распределения и плотность распределения вероятностей случайной величины.
2. Математическое ожидание, дисперсия и среднеквадратическое отклонение случайной величины.
3. Система двух случайных величин. Совместная функция распределения и совместная плотность распределения системы двух случайных величин.
4. Ковариация и коэффициент корреляции случайных величин.
5. Уравнение линейной среднеквадратической регрессии.
6. Выборка, вариационный ряд и группированная выборка.
7. Статистическая функция распределения, гистограмма и полигон.
8. Точечные оценки математического ожидания и дисперсии.
9. Интервальная оценка математического ожидания. Доверительный интервал.
10. Выбор типа теоретического закона распределения.
11. Параметры теоретического закона распределения. Метод моментов.
12. Критерии согласия. Ошибки первого и второго рода.
13. Критерий c2 для проверки гипотезы о законе распределения вероятностей.
14. Оценка ковариации и коэффициента корреляции по выборке.
15. Уравнение выборочной линейной среднеквадратической регрессии.
16. Проверка гипотезы о значимости выборочного значения коэффициента корреляции.
4. ПРИМЕР ВЫПОЛНЕНИЯ ТИПОВОГО РАСЧЁТА.
Исходными данными для примера являются измерения кровяного давления (случайная величина Y) у людей различного возраста (случайная величина Х). Всего было обследовано 100 человек. Результаты обследования приведены в таблице 4.1.
Данные, приведённые в таблице 4.1, представляют собой исходную выборку для дальнейших расчётов. На её основе составляем отдельную выборку для случайной величины Х (таблица 4.2) и для случайной величины Y (таблица 4.3).
По полученной выборке для случайной величины Х строим вариационный ряд (таблица 4.4).
После этого построим группированную выборку (первые три колонки таблицы 4.5) и для каждого из десяти интервалов вычислим представитель интервала, относительную частоту и плотность частоты (таблица 4.5).
Таблица 4.1. Результаты измерения кровяного давления у 100 человек различного возраста.
| N | X | y | N | x | y | N | x | y |
| 1. | 44.0 | 118.0 | 35. | 69.2 | 150.0 | 69. | 22.7 | 100.0 |
| 2. | 33.1 | 67.0 | 36. | 45.1 | 120.0 | 70. | 48.9 | 128.0 |
| 3. | 53.6 | 147.0 | 37. | 40.2 | 113.0 | 71. | 55.0 | 164.0 |
| 4. | 56.4 | 129.0 | 38. | 34.3 | 107.0 | 72. | 69.2 | 162.0 |
| 5. | 73.1 | 191.0 | 39. | 21.3 | 104.0 | 73. | 48.4 | 130.0 |
| 6. | 57.8 | 137.0 | 40. | 26.8 | 105.0 | 74. | 37.6 | 114.0 |
| 7. | 37.2 | 119.0 | 41. | 72.1 | 169.0 | 75. | 19.6 | 96.0 |
| 8. | 18.2 | 100.0 | 42. | 20.7 | 102.0 | 76. | 32.0 | 107.0 |
| 9. | 45.7 | 115.0 | 43. | 26.0 | 103.0 | 77. | 22.0 | 100.0 |
| 10. | 40.2 | 114.0 | 44. | 33.8 | 112.0 | 78. | 53.2 | 126.0 |
| 11. | 32.2 | 109.0 | 45. | 45.6 | 114.0 | 79. | 47.5 | 126.0 |
| 12. | 76.4 | 169.0 | 46. | 37.8 | 102.0 | 80. | 43.2 | 111.0 |
| 13. | 61.3 | 130.0 | 47. | 18.2 | 97.0 | 81. | 75.0 | 148.0 |
| 14. | 46.7 | 119.0 | 48. | 57.9 | 142.0 | 82. | 63.2 | 152.0 |
| 15. | 35.7 | 109.0 | 49. | 74.0 | 149.0 | 83. | 51.8 | 129.0 |
| 16. | 68.1 | 156.0 | 50. | 60.4 | 133.0 | 84. | 43.0 | 106.0 |
| 17. | 79.6 | 156.0 | 51. | 55.8 | 125.0 | 85. | 76.4 | 165.0 |
| 18. | 49.6 | 125.0 | 52. | 33.4 | 112.0 | 86. | 49.5 | 118.0 |
| 19. | 50.1 | 130.0 | 53. | 58.0 | 127.0 | 87. | 42.1 | 116.0 |
| 20. | 45.5 | 125.0 | 54. | 67.5 | 143.0 | 88. | 30.7 | 105.0 |
| 21. | 43.9 | 125.0 | 55. | 53.4 | 121.0 | 89. | 46.1 | 119.0 |
| 22. | 43.2 | 116.0 | 56. | 38.1 | 115.0 | 90. | 63.5 | 144.0 |
| 23. | 17.0 | 75.0 | 57. | 46.8 | 128.0 | 91. | 72.8 | 161.0 |
| 24. | 58.6 | 128.0 | 58. | 59.9 | 130.0 | 92. | 56.6 | 141.0 |
| 25. | 60.4 | 131.0 | 59. | 19.5 | 91.0 | 93. | 65.7 | 140.0 |
| 26. | 76.1 | 155.0 | 60. | 71.7 | 141.0 | 94. | 49.8 | 123.0 |
| 27. | 57.2 | 134.0 | 61. | 50.6 | 134.0 | 95. | 31.8 | 89.0 |
| 28. | 39.4 | 113.0 | 62. | 35.9 | 109.0 | 96. | 24.0 | 111.0 |
| 29. | 22.3 | 100.0 | 63. | 18.8 | 108.0 | 97. | 72.4 | 156.0 |
| 30. | 74.4 | 141.0 | 64. | 64.1 | 135.0 | 98. | 35.7 | 105.0 |
| 31. | 52.0 | 127.0 | 65. | 51.1 | 137.0 | 99. | 21.8 | 96.0 |
| 32. | 31.5 | 90.0 | 66. | 31.8 | 94.0 | 100. | 22.0 | 79.0 |
| 33. | 18.2 | 99.0 | 67. | 25.3 | 75.0 | * | * | * |
| 34. | 19.5 | 63.0 | 68. | 25.0 | 51.0 | * | * | * |
Таблица 4.2. Выборка для случайной величины Х.
| N | x | N | x | N | x | N | x | N | x |
| 1. | 44.0 | 21. | 69.2 | 41. | 25.0 | 61. | 33.1 | 81. | 45.1 |
| 2. | 33.1 | 22. | 53.6 | 42. | 40.2 | 62. | 48.9 | 82. | 56.4 |
| 3. | 53.6 | 23. | 55.0 | 43. | 73.1 | 63. | 21.3 | 83. | 69.2 |
| 4. | 57.8 | 24. | 26.8 | 44. | 48.4 | 64. | 37.2 | 84. | 72.1 |
| 5. | 37.6 | 25. | 18.2 | 45. | 20.7 | 65. | 19.6 | 85. | 45.7 |
| 6. | 26.0 | 26. | 32.0 | 46. | 40.2 | 66. | 33.8 | 86. | 22.0 |
| 7. | 32.2 | 27. | 45.6 | 47. | 53.2 | 67. | 76.4 | 87. | 37.8 |
| 8. | 47.5 | 28. | 61.3 | 48. | 18.2 | 68. | 43.2 | 88. | 46.7 |
| 9. | 57.9 | 29. | 75.0 | 49. | 35.7 | 69. | 74.0 | 89. | 63.2 |
| 10. | 68.1 | 30. | 60.4 | 50. | 51.8 | 70. | 79.6 | 90. | 55.8 |
| 11. | 43.0 | 31. | 49.6 | 51. | 33.4 | 71. | 76.4 | 91. | 50.1 |
| 12. | 58.0 | 32. | 49.5 | 52. | 45.5 | 72. | 67.5 | 92. | 42.1 |
| 13. | 43.9 | 33. | 53.4 | 53. | 30.7 | 73. | 43.2 | 93. | 38.1 |
| 14. | 46.1 | 34. | 17.0 | 54. | 46.8 | 74. | 63.5 | 94. | 58.6 |
| 15. | 59.9 | 35. | 72.8 | 55. | 60.4 | 75. | 19.5 | 95. | 56.6 |
| 16. | 76.1 | 36. | 71.7 | 56. | 65.7 | 76. | 57.2 | 96. | 50.6 |
| 17. | 49.8 | 37. | 39.4 | 57. | 35.9 | 77. | 31.8 | 97. | 22.3 |
| 18. | 18.8 | 38. | 24.0 | 58. | 74.4 | 78. | 64.1 | 98. | 72.4 |
| 19. | 52.0 | 39. | 51.1 | 59. | 35.7 | 79. | 31.5 | 99. | 31.8 |
| 20. | 21.8 | 40. | 18.2 | 60. | 25.3 | 80. | 22.0 | 100. | 19.5 |
Таблица 4.3. Выборка для случайной величины Y.
| N | Y | N | y | N | y | N | y | N | y |
| 1. | 118.0 | 21. | 123.0 | 41. | 121.0 | 61. | 109.0 | 81. | 96.0 |
| 2. | 67.0 | 22. | 100.0 | 42. | 119.0 | 62. | 133.0 | 82. | 114.0 |
| 3. | 147.0 | 23. | 135.0 | 43. | 128.0 | 63. | 106.0 | 83. | 114.0 |
| 4. | 191.0 | 24. | 105.0 | 44. | 91.0 | 64. | 130.0 | 84. | 126.0 |
| 5. | 105.0 | 25. | 99.0 | 45. | 140.0 | 65. | 143.0 | 85. | 119.0 |
| 6. | 114.0 | 26. | 150.0 | 46. | 113.0 | 66. | 105.0 | 86. | 149.0 |
| 7. | 115.0 | 27. | 100.0 | 47. | 108.0 | 67. | 75.0 | 87. | 129.0 |
| 8. | 112.0 | 28. | 129.0 | 48. | 156.0 | 68. | 130.0 | 88. | 125.0 |
| 9. | 126.0 | 29. | 104.0 | 49. | 90.0 | 69. | 141.0 | 89. | 127.0 |
| 10. | 130.0 | 30. | 130.0 | 50. | 75.0 | 70. | 134.0 | 90. | 116.0 |
| 11. | 142.0 | 31. | 100.0 | 51. | 51.0 | 71. | 109.0 | 91. | 116.0 |
| 12. | 152.0 | 32. | 103.0 | 52. | 147.0 | 72. | 111.0 | 92. | 128.0 |
| 13. | 156.0 | 33. | 100.0 | 53. | 107.0 | 73. | 127.0 | 93. | 161.0 |
| 14. | 112.0 | 34. | 169.0 | 54. | 162.0 | 74. | 94.0 | 94. | 155.0 |
| 15. | 118.0 | 35. | 97.0 | 55. | 119.0 | 75. | 79.0 | 95. | 134.0 |
| 16. | 125.0 | 36. | 148.0 | 56. | 102.0 | 76. | 67.0 | 96. | 89.0 |
| 17. | 115.0 | 37. | 156.0 | 57. | 107.0 | 77. | 113.0 | 97. | 141.0 |
| 18. | 144.0 | 38. | 125.0 | 58. | 109.0 | 78. | 164.0 | 98. | 137.0 |
| 19. | 131.0 | 39. | 165.0 | 59. | 102.0 | 79. | 137.0 | 99. | 96.0 |
| 20. | 141.0 | 40. | 125.0 | 60. | 111.0 | 80. | 169.0 | 100. | 63.0 |
Таблица 4.4. Вариационный ряд для Х
| 17.0 | 18.2 | 18.2 | 18.2 | 18.8 | 19.5 | 19.5 | 19.6 | 20.7 | 21.3 |
| 21.8 | 22.0 | 22.2 | 22.3 | 22.7 | 24.0 | 25.0 | 25.3 | 26.0 | 26.8 |
| 30.7 | 31.5 | 31.8 | 31.8 | 32.0 | 32.2 | 33.1 | 33.4 | 33.8 | 34.3 |
| 35.7 | 35.7 | 35.9 | 37.2 | 37.6 | 37.8 | 38.1 | 39.4 | 40.2 | 40.2 |
| 42.1 | 43.0 | 43.2 | 43.2 | 43.9 | 44.0 | 45.1 | 45.5 | 45.6 | 45.7 |
| 46.1 | 46.7 | 46.8 | 47.5 | 48.4 | 48.9 | 49.5 | 49.5 | 49.8 | 50.1 |
| 50.6 | 51.1 | 51.8 | 52.0 | 53.2 | 53.4 | 53.6 | 55.0 | 55.8 | 56.4 |
| 56.6 | 57.2 | 57.8 | 57.9 | 58.0 | 58.6 | 59.9 | 60.4 | 60.4 | 61.3 |
| 63.2 | 63.5 | 64.1 | 65.7 | 67.5 | 68.1 | 69.2 | 69.2 | 71.7 | 72.1 |
| 72.4 | 72.8 | 73.1 | 74.4 | 74.8 | 75.0 | 76.1 | 76.4 | 76.4 | 79.6 |
Таблица 4.5. Группированная выборка для Х.
| Номер интервала | Границы интервала (a i ; a i+1) | Частоты m i | Представитель интервала z i | Относительная частота Pi* | Плотность относительной частоты f i* |
| 1. | 17 – 20 | 18.5 | 0.08 | 0.0267 | |
| 2. | 20 – 30 | 25.0 | 0.12 | 0.0120 | |
| 3. | 30 – 35 | 32.5 | 0.10 | 0.0200 | |
| 4. | 35 – 40 | 37.5 | 0.08 | 0.0160 | |
| 5. | 40 – 45 | 42.5 | 0.08 | 0.0160 | |
| 6. | 45 – 50 | 47.5 | 0.13 | 0.0260 | |
| 7. | 50 – 55 | 52.5 | 0.08 | 0.0160 | |
| 8. | 55 – 60 | 57.5 | 0.10 | 0.0200 | |
| 9. | 60 – 70 | 65.0 | 0.11 | 0.0110 | |
| 10. | 70 – 80 | 75.5 | 0.12 | 0.0120 |
Найдём точечные оценки математического ожидания и дисперсии случайной величины Х по исходной и группированной выборкам (формулы (1.12), (1.14), и (1.15), (1.16) соответственно):
=  = 0.01 × 4650 = 46.50,
= 0.01 × 4650 = 46.50,
= 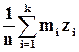 = 0.01 × 4640.5 = 46.41,
= 0.01 × 4640.5 = 46.41,
 =
=  » 260.18,
» 260.18,
= 16.13,
 =
=  = 298.29,
= 298.29,
= 17.27.
Найдём интервальные оценки математического ожидания случайной величины Х, то есть построим доверительные интервалы с доверительными вероятностями b = 0.95 и b = 0.99 (формула (1.23)):
I0.95 = (46.41 – 1.96 × 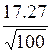 ; 46.41 + 1.96 ×
; 46.41 + 1.96 ×  » (43.03; 49.80),
» (43.03; 49.80),
I0.99 = (46.41 – 2.58 × ; 46,41 + 2.58 × » (41.95; 50.87).
 |
Используя данные, полученные для группированной выборки (таблица 4.5), построим на одном графике гистограмму и полигон (рис. 4.1, кривые 1 и 2, соответственно).
Рис.4.1. Гистограмма, полигон и теоретическая плотность для случайной величины Х.
Прямоугольники гистограммы имеют примерно равные высоты, поэтому предположим, что случайная величина Х распределена по равномерному закону с плотностью

1/(b – a) при а £ х £ b,
fx(x) =
0 при х < a и b < x.
Для равномерного распределения параметры a и b определяются по формулам (1.25):
a = min xi = 17; b = max xi = 79.6.
i i
Таким образом, теоретическое распределение имеет плотность

0.016 при 17 £ х £ 79.6,
f(x) =
0 при х <17 и х >79.6,
и функцию распределения
 |
0 при х <17,
Fx(x) = (х – 17)/62.6 при 17 £ х £ 79.6,
1 при х >79,6.
График плотности f(x) изобразим на рис.4.1. (линия 3).
Для проверки выдвинутой гипотезы о равномерном распределении величины Х применим критерий c2. Число степеней свободы r = k–s–1=10–2–1=7, так как по выборке определено s=2 параметра: a и b. Уровню значимости b = 0.01 при r = 7 соответствует критическое значение 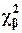 = 18.5. Для вычисления c2 составляем таблицу 4.6.
= 18.5. Для вычисления c2 составляем таблицу 4.6.
Таблица 4.6. Расчёт значения c2 для X.
| N | Границы интервала | mi | F(ai) | F(ai+1) | Pi | nPi | mi – nPi | (mi -nPi)2 | 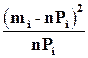
|
| 1. | 17-20 | 0.000 | 0.048 | 0.048 | 4.8 | 3.2 | 10.24 | 2.133 | |
| 2. | 20-30 | 0.048 | 0.208 | 0.160 | 16.0 | - 4.0 | 16.00 | 1.000 | |
| 3. | 30-35 | 0.208 | 0.288 | 0.080 | 8.0 | 2.0 | 4.00 | 0.500 | |
| 4. | 35-40 | 0.288 | 0.367 | 0.079 | 7.9 | 0.1 | 0.01 | 0.013 | |
| 5. | 40-45 | 0.367 | 0.447 | 0.080 | 8.0 | 0.0 | 0.00 | 0.000 | |
| 6. | 45-50 | 0.447 | 0.527 | 0.080 | 8.0 | 5.0 | 25.00 | 3.125 | |
| 7. | 50-55 | 0.527 | 0.607 | 0.080 | 8.0 | 0.0 | 0.00 | 0.000 | |
| 8. | 55-60 | 0.607 | 0.687 | 0.080 | 8.0 | 2.0 | 4.00 | 0.500 | |
| 9. | 60-70 | 0.687 | 0.847 | 0.160 | 16.0 | - 5.0 | 25.00 | 1.563 | |
| 70-80 | 0.847 | 1.000 | 0.153 | 15.3 | - 3.3 | 10.89 | 0.712 | ||
| Σ | 1.000 | 9.546 |
Итак, получили c2 = 9.546. Поскольку 9.546 < 18.5, гипотеза о выбранном равномерном теоретическом распределении принимается.
Проделаем аналогичные вычисления для случайной величины Y.
Таблица 4.7. Вариационный ряд для Y.
После этого построим группированную выборку (первые три колонки таблицы 4.8) и для каждого из 9 -ти интервалов вычислим представитель интервала, относительную частоту и плотность частоты (таблица 4.8).
Таблица 4.8. Группированная выборка для Y.
| N | Границы интервала | Частоты mi | Представитель интервала zi | Относительная частотаPi* | Плотность относительной частоты fi* |
| 1. | 50-100 | 75.0 | 0.14 | 0.0028 | |
| 2. | 100-105 | 102.0 | 0.08 | 0.0160 | |
| 3. | 105-110 | 107.0 | 0.10 | 0.0200 | |
| 4. | 110-115 | 112.0 | 0.09 | 0.0180 | |
| 5. | 115-120 | 117.0 | 0.09 | 0.0180 | |
| 6. | 120-130 | 125.0 | 0.16 | 0.0160 | |
| 7. | 130-140 | 135.0 | 0.11 | 0.0110 | |
| 8. | 140-150 | 145.0 | 0.10 | 0.0100 | |
| 9. | 150-200 | 175.0 | 0.13 | 0.0026 |
Найдём точечные оценки математического ожидания и дисперсии случайной величины Y по исходной и группированной выборкам (формулы (1.12), (1.14) и (1.15), (1.16) соответственно):
= 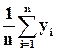 = 0.01 × 12127 = 121.27,
= 0.01 × 12127 = 121.27,
= = 0.01 × 12225 = 122.25,
 =
= 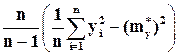 = 592.44,
= 592.44,
= 24.34,
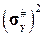 =
=  = 816.86,
= 816.86,
= 28.58.
Найдём интервальные оценки математического ожидания случайной величины Y, то есть построим доверительные интервалы с доверительными вероятностями b = 0.95 и b = 0.99 (формула (1.23)):
I0.95 = (122.25 – 1.96 × 2.858; 122.25 + 1.96 × 2.858)» (116.65; 127.85),
I0.95 = (122.25 – 2.58 × 2.858; 122.25 + 2.58 × 2.058)» (114.08; 129.62).
Используя данные, полученные для группированной выборки (таблица 4.8), построим на одном графике гистограмму и полигон (рис. 4.2).

Рис.4.2. Гистограмма, полигон и плотность для случайной величины Y.
Гистограмма имеет относительно высокие прямоугольники в середине, влево и вправо от неё высоты прямоугольников уменьшаются, имеются два «хвоста». Можно предположить, что случайная величина Y имеет нормальное распределение с плотностью (Приложение 1)
f(y) = 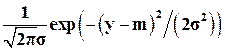 ,
,
и функцией распределения
Fy(y) = 0.5 + F0((y – m)/s)
где F0(у) – функция Лапласа [5].
Оценка математического ожидания по группированной выборке равна m# = 122.25, а оценка дисперсии - 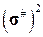 = 816.86 (
= 816.86 ( = 28.58). По методу моментов выбираем параметры m = m# и s = s#. Таким образом, выбираем теоретическое распределение
= 28.58). По методу моментов выбираем параметры m = m# и s = s#. Таким образом, выбираем теоретическое распределение
f(y) = 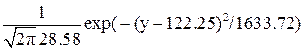 ,
,
Fy(y) = F0 ((y – 122.25)/28.58) + 0.5
График плотности f(y) изобразим на рис.4.2 (линия 3).
Чтобы использовать критерий c2, найдём число степеней свободы: r = 9 – 2 – 1 = 6. Если уровень значимости b = 0.01, то =16.8. Для вычисления c2 составляем таблицу 4.9.
Таблица 4.9. Расчёт значения c2 для Y.
| N | Границы интервала | mi | F(ai) | F(ai+1) | Pi | nPi | mi –nPi | (mi – nPi)2 | 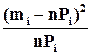
|
| 1. | -¥-100 | 0.000 | 0.218 | 0.218 | 21.8 | -7.8 | 60.84 | 2.790 | |
| 2. | 100-105 | 0.218 | 0.274 | 0.056 | 5.6 | 2.4 | 5.76 | 1.030 | |
| 3. | 105-110 | 0.274 | 0.334 | 0.060 | 6.0 | 4.1 | 16.81 | 2.850 | |
| 4. | 110-115 | 0.334 | 0.401 | 0.067 | 6.7 | 2.3 | 4.84 | 0.710 | |
| 5. | 115-120 | 0.401 | 0.468 | 0.067 | 6.7 | 2.3 | 5.29 | 0.790 | |
| 6. | 120-130 | 0.468 | 0.607 | 0.149 | 14.9 | 1.1 | 1.21 | 0.081 | |
| 7. | 130-140 | 0.607 | 0.732 | 0.125 | 12.5 | -1.5 | 2.25 | 0.180 | |
| 8. | 140-150 | 0.732 | 0.834 | 0.101 | 10.1 | -0.1 | 0.01 | 0.001 | |
| 9. | 150-¥ | 0.834 | 1.000 | 0.167 | 16.7 | -3.7 | 13.69 | 0.820 | |
| Σ | 1.000 | 9.252 |
Итак, получили c2 = 9.252. Поскольку 9.252< 16.8, гипотеза о нормальном теоретическом распределении принимается.
Рассмотрим теперь случайные величины X и Y совместно. Отметим точками на плоскости Oxy все 100пар значений системы этих величин (рис.4.3). Найдём оценку ковариации по формуле (1.47):
=  ,
,
так как = 46.50, = 121.27, = 16.13 и = 24.34. Соответственно оценка коэффициента корреляции (формула (1.48)):
r* =  .
.
Выборочное уравнение линейной среднеквадратической регрессии Y на X находим по формуле (1.49):
y =  .
.
Построим график линейной среднеквадратической регрессии Y на X (рис.4.3):
 |
Рис.4.3. График линейной среднеквадратической регрессии Y на X.
Наконец, проверим с уровнем значимости b = 0,01 гипотезу о значимости полученного значения коэффициента корреляции r* = 0,82. Вычислим по формуле (1.51) наблюдаемое значение
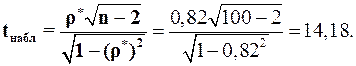
Из таблицы критических точек распределения Стьюдента (Приложение 2) по уровню значимости b = 0.01 и числу степеней свободы r = 100 – 2 = 98 находим  . Оказалось, что
. Оказалось, что  , поэтому гипотеза H0 = (r = 0) отвергается, то есть найденное r* = 0,82 считается значимым. Другими словами, есть основания считать, что имеется корреляция между изучаемыми случайными величинами Х и Y.
, поэтому гипотеза H0 = (r = 0) отвергается, то есть найденное r* = 0,82 считается значимым. Другими словами, есть основания считать, что имеется корреляция между изучаемыми случайными величинами Х и Y.
ПРИЛОЖЕНИЕ 1.
Некоторые законы распределения случайных величин.

