




При исследовании случайной величины Х по результатам её испытаний часто требуется найти закон её распределения. Тип распределения можно угадать по виду гистограммы или полигона. Будем называть выбранное нами распределение теоретическим. Каждое теоретическое распределение содержит один или более параметров a1, a2, …, aS, которым должны быть присвоены некоторые значения. Например, экспоненциальное распределение с плотностью вероятностей f(x) = lexp(-lx) содержит один параметр l, а нормальное распределение с плотностью
f(x) = 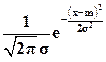
содержит два параметра m и s. Параметры теоретического распределения нужно выбирать, очевидно, так, чтобы полученное распределение как можно лучше согласовывалось с опытными данными, то есть с выборкой. Другими словами, теория должна как можно точнее описывать эксперимент. Одним из способов выбора параметров теоретического распределения является метод моментов: параметры a1, a2, …, ak выбираются так, чтобы k первых моментов теоретического распределения совпадали с их выборочными оценками.
Рассмотренные нами в начале параграфа распределения содержат один или два параметра. Первыми двумя моментами являются математическое ожидание и дисперсия. Поэтому метод моментов в нашем случае сводится к такому выбору одного или двух параметров теоретического распределения, чтобы выполнялось первое или или равенства:
mx = 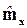 ;
; 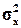 =
= 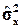
 , (1.24)
, (1.24)
где и – оценки математического ожидания и дисперсии по выборке.
Например, в случае экспоненциального распределения имеется только один параметр l, при этом mx =  и из первого равенства (1.24) получаем l =
и из первого равенства (1.24) получаем l = 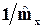 . В случае же нормального распределения параметров два, при этом mx = m и
. В случае же нормального распределения параметров два, при этом mx = m и 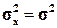 , поэтому из обоих равенств (1.24) получаем два параметра:
, поэтому из обоих равенств (1.24) получаем два параметра:  и
и 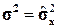 .
.
Отметим, что метод моментов является лишь одним из возможных методов определения параметров теоретического распределения. Для некоторых типов распределений он может дать плохие результаты. Рассмотрим, например, равномерное распределение с плотностью 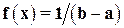 , x Î[a, b]. Его параметры a и b связаны с mx и равенствами
, x Î[a, b]. Его параметры a и b связаны с mx и равенствами 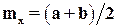 и
и 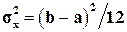 . Метод моментов приводит к системе уравнений:
. Метод моментов приводит к системе уравнений:
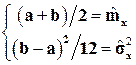
Может случиться, что найденная из этой системы нижняя граница распределения a, окажется больше некоторых значений из выборки, или же верхняя граница b окажется меньше некоторых выборочных значений. Теоретическое распределение с такими параметрами a и b следует сразу же отвергнуть как противоречащее условию, что все значения Х должны принадлежать отрезку [a, b].
В случае равномерного распределения следует выбирать значения:
 ;
; 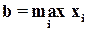 , (1.25)
, (1.25)
которые не приводят к описанным выше противоречиям. Если имеется группированная выборка, то а – левая граница первого разряда, b – правая граница последнего разряда.
Аналогичным образом можно определить некоторые из параметров других ограниченных распределений. Рассмотрим, например, смещённое экспоненциальное распределение с плотностью:
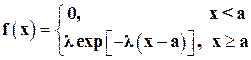 (1.26)
(1.26)
сосредоточенное на интервале (а, ¥). Параметр сдвига а определяется из первого соотношения (1.25), а для определения l используем метод моментов, приравнивая математические ожидания: 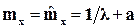 , откуда
, откуда 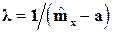 .
.
Критерии согласия.
Относительно имеющейся выборки S могут быть высказаны какие–то предположения или гипотезы. Например, мы можем выдвинуть гипотезу о том, что исследуемая случайная величина Х имеет нормальное распределение. Методы проверки гипотез в математической статистике называют критериями.
В общем случае проверка гипотезы производится следующим образом. Пусть относительно выборки S выдвинута гипотеза Н0. Критерием является некоторая функция U = U (S, H0). Вся область значений D критерия U делится на две области D0 и D1. Если вычисленное значение критерия принадлежит области D0, то гипотеза H0 принимается, в противном случае Н0 отвергается. Область D0 называется областью допустимых значений или областью принятия гипотезы, область D1 называется областью отклонения гипотезы или критической областью.
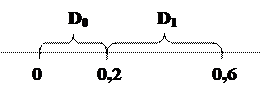 |
Поясним это следующим примером. Пусть выдвинута гипотеза Н0, что вероятность события А равна 0,6. В серии же из 100 опытов событие произошло m раз. В качестве критерия примем функцию U = | m/100–0,6|, то есть отклонение относительной частоты события А в серии из 100 испытаний от предлагаемой вероятности 0,6. Множество значений D критерия есть отрезок [0; 0,6]. Естественно принимать гипотезу Н0, если m/100 не слишком отличается от 0,6 и отвергать, если разница велика, например, превышает 0,2. Таким образом, Н0 принимается, если значение U = |m/100–0,6| £ 0,2, и отвергается, если U > 0,2. Для этого примера области D0 и D1 показаны на рис.1.8.
Рис.1.8. Допустимая и критическая области принятия решения.
Выборка S является случайной, поэтому и U(S, H0) является случайной величиной. Следовательно, принятие или отклонение гипотезы – случайные события и при проверке гипотез возможны следующие ошибки.
1. Гипотеза верна, но отвергается (ошибка первого рода).
2. Гипотеза неверна, но принимается (ошибка второго рода).
Вероятность b ошибки первого рода называют уровнем значимости критерия. Таким образом, уровень значимости есть вероятность отвергнуть истинную гипотезу.
Если 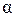 -вероятность ошибки второго рода, то
-вероятность ошибки второго рода, то 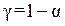 называется мощностью критерия. Это вероятность отвержения неверной гипотезы.
называется мощностью критерия. Это вероятность отвержения неверной гипотезы.
Вероятности обеих ошибок желательно минимизировать, но оказывается, что попытка уменьшить вероятность одной ошибки приводит к увеличению вероятности другой. Поэтому вероятность одной из ошибок задаётся, а вероятность второй ошибки стараются сделать минимальной.
Чаще всего для проверки гипотез о законах распределения применяется критерий согласия χ 2 (хи-квадрат), предложенный К.Пирсоном. Рассмотрим этот критерий.
Пусть имеется группированная выборка S и выдвинута гипотеза H0, что случайная величина Х имеет функцию распределения F(x). Если бы гипотеза Н0 была верна, то вероятность попадания значения Х в i –ый частичный интервал [ai; ai+1] была бы равна
Pi = F(ai+1) – F(ai), (1.27)
а математическое ожидание числа попаданий Х в этот полуинтервал, то есть ожидаемая или теоретическая частота была бы равна
ni = nРi, (1.28)
где n = m1 + m2 + … + mk. Критерий χ 2 оценивает меру расхождения теоретических nPi и статистических (или выборочных) частот m i:
χ 2 = 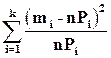 . (1.29)
. (1.29)
Чем больше отличаются mi от nPi, тем больше значение χ 2
К.Пирсон доказал, что при истинности H0 распределение случайной величины (1.29) при n®¥ неограниченно приближается к так называемому c2 – распределению, независимо от вида распределения F(x). Это приближение к c2 – распределению можно считать удовлетворительным, если все частоты m i достаточно велики. Будем поэтому предполагать, что все mi ≥ 6.
Следует отметить, что между теоретическими частотами ni = nPi и статистическими частотами mi имеются некоторые связи. Одна связь имеется всегда:
n1 + n2 + … + nk = m1 + m2 + … + mk = n. (1.30)
Другие связи появляются при оценке параметров теоретического распределения по выборке. Если, например, приравнены теоретическое и выборочное среднее, то имеется одна дополнительная связь. Если приравнены ещё и дисперсии, то дополнительных связей будет две. Эти связи приводят к зависимости слагаемых в выражении (1.29) между собой.
Наличие связей учитывается определением числа независимых слагаемых в выражении (1.29), называемом числом степеней свободы, которое определяется по формуле:
r = k – 1 – s, (1.31)
где k – число частичных интервалов группированной выборки, s – число дополнительных связей (кроме связи (1.30)) между теоретическим распределением и выборкой. Число s равно количеству параметров теоретического распределения, определённых именно по выборке. В это число не входят параметры, определённые по каким – либо соображениям независимо от выборки. Например, может быть известно заранее, что X имеет нулевое математическое ожидание. Тогда при гипотезе о нормальном распределении будет наложена только одна дополнительная связь – приравниваются теоретическая и выборочная дисперсии. Дополнительных связей может и вообще не быть (s = 0), если, к примеру, без предварительного анализа выборки (или даже до её получения) выдвинуть гипотезу о теоретическом распределении с фиксированными значениями входящих в него параметров.
Распределение вероятностей типа c2 полностью определяется числом степеней свободы r, в зависимости от которого составляются таблицы этого распределения, и Fr(x) – функция распределения случайной величины c2 с r степенями свободы.
Пусть число степеней свободы r определено. Допустим, что c2b удовлетворяет равенству: Fr(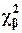 ) = 1 – b. Это означает, что:
) = 1 – b. Это означает, что:
P(c2 > ) = b, (1.32)
то есть вычисленное по формуле (1.29) значение c2 (в случае истинности гипотезы Н0) превосходит значение с вероятностью b.
Таким образом, если гипотезу Н0 принимать в случае c2 £ и отвергать при c2> , то верная гипотеза Н0 будет отвергаться с вероятностью b, то есть b является уровнем значимости сформулированного критерия. Критические значения даны в приложении 2в зависимости от уровня значимости b и числа степеней свободы r.
Итак, применение критерия c2 сводится к следующему. Выбирается (или задаётся) уровень значимости b. По группированной выборке с частотами mi не менее шести вычисляется значение c2 по формуле (1.29). По найденному числу степеней свободы r и заданному b находится критическое значение из таблицы в приложении 2. Применяется решающее правило:
c2 £ ® H0 принимается,
(1.33)
c2 > ® H0 отвергается.
Если в имеющейся группированной выборке встречаются частоты, которые меньше шести, то следует объединить некоторые соседние интервалы, чтобы все частоты mi были не менее шести.
Если некоторая гипотеза о теоретическом распределении F(x) в результате применения критерия была принята, F(x) может использоваться в дальнейшем для решения различных задач о случайной величине Х (но до тех пор, пока не будут получены экспериментальные данные, которым гипотеза Н0 противоречит). Если же Н0 оказалась отвергнутой, то следует подобрать и проверить гипотезу о другом теоретическом распределении, которая выглядит достаточно правдоподобно на фоне имеющихся экспериментальныхданных.
Замечание. Если гипотеза H0 оказалось принятой, то это еще не значит, что она верна, так как имеется некоторая вероятность ошибки второго рода. Гипотеза H0 принята не потому, что она верна (так это или не так, нам неизвестно), а потому, что она выглядит правдоподобной при имеющейся выборке S. Аналогично, если гипотеза H0 отвергнута, то не следует категорически утверждать, что она ложна, так как возможна ошибка первого рода (отвергнуть верную гипотезу). Уровень значимости β и есть вероятность такой ошибки. Мы отвергаем гипотезу потому, что она выглядит неправдоподобной при имеющихся наблюдениях, т.е. выборке S. Напомним, что ошибки в проверке гипотез проистекают из-за случайности значений выборки, что связано с тем, что эти значения – результаты испытаний случайной величины.
Следует отметить, что определяемое по данному уровню значимости критическое значение содержит некоторую погрешность, так как распределении величины (1.29) несколько отличается от распределения c2. Это отличие вызвано конечностью объёма выборки и способом выбора значений параметров теоретического распределения. Более корректным в данной ситуации является метод минимума c2, состоящий в том, что параметры теоретического распределения выбираются так, чтобы величина (1.29) приняла минимально возможное значение. Однако этот метод трудно реализуем и поэтому применяется редко.

