




Случайная переменная Y имеет логарифмически нормальное распределение с параметрами μ и σ, если случайная переменная X = lnY имеет нормальное распределение с теми же параметрами μ и σ. Зная характер связи между переменными X и Y, можем легко построить график плотности вероятности случайной переменной с логарифмически нормальным распределением (Рисунок 4.2).
Рисунок 4.2 – Кривые плотности логарифмически нормального распределения при различных значениях параметров μ и σ
Если случайная переменная X имеет функцию плотности вероятности, определяемую формулой (4.6), и если X = lnY, то:
 , откуда имеем для у > 0:
, откуда имеем для у > 0:
 (4.14)
(4.14)
Из определения следует, что случайная переменная, подчиняющаяся логарифмически нормальному распределению, может принимать только положительные значения. Как показано на рисунке 4.2, кривые функции f(y) имеют левостороннюю асимметрию, которая тем сильнее, чем больше значения параметров μ и σ. Каждая кривая имеет один максимум и является определенной для всех положительных значений у.
Вычисление математического ожидания и дисперсии случайной переменной с логарифмически нормальным распределением не составляет особых трудностей:
 (4.15)
(4.15)
 (4.16)
(4.16)
 (4.17)
(4.17)
Путем подстановок и ввода новых переменных в интегралах 4.15 и 4.16 получим:
 (4.18)
(4.18)
 (4.19)
(4.19)
Вообще, для исчисления вероятности того, что случайная переменная Y с логарифмически нормальным распределением и плотностью f(y, μ, σ), примет значение в интервале (а, b), следует взять интеграл:
 (4.20)
(4.20)
Однако на практике удобнее воспользоваться тем, что логарифм случайной переменной Y имеет нормальное распределение. Вероятность того, что а ≤ Y ≤ b равнозначна вероятности того, что
lnа ≤ lnY ≤ lnb.
Пример
Вычислим вероятность того, что случайная переменная с логарифмически распределением μ = 1, σ = 0,5, примет значение в интервале (2, 5). Имеем:
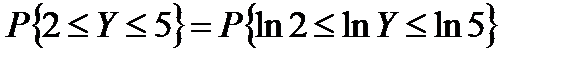
Из таблиц логарифмов находим ln2 = 0,6932 и ln5 = 1,6094.
Обозначив lnY = X, можем написать:

Причем случайная переменная X подчинена нормальному распределению со средним значением μ = 1 и стандартным отклонением σ = 0,5. Теперь искомую вероятность нетрудно вычислить по таблицам интегральной функции нормального распределения:
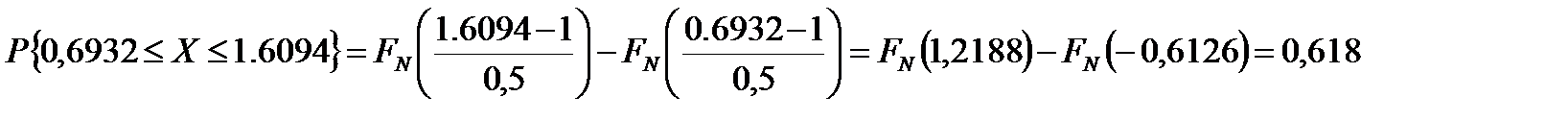
Вопросы для самоконтроля
1 Определение прямоугольного распределения.
2 График плотности вероятности случайной переменной с прямоугольным распределением
3 Основополагающее значение прямоугольного распределения.
4 Математическое ожидание и дисперсия случайной переменной в прямоугольном распределении.
5 Роль нормального распределения в математической статистике.
6 Что такое нормальное распределение и как оно связано с биномиальным?
7 График плотности вероятности случайной переменной с нормальным распределением.
8 Какими статистическими параметрами может быть задано нормальное распределение?
9 Почему нормальное распределение является непрерывным?
10 Уравнение нормальной кривой.
11 Что такое нормированное отклонение?
12 Уравнение кривой нормального распределения в нормированной форме.
13 Какими значениями μ и σ характеризуется нормальная совокупность в нормированной форме?
14 Какая доля данных выборки укладывается в пределах ±1σ, ±2σ, ±3σ?
15 Что показывает таблица нормального интеграла вероятностей?
16 Уравнение логарифмически нормальной кривой.
17 График плотности вероятности случайной переменной с логарифмически нормальным распределением.
18 Какие необходимо выполнить преобразования, чтобы из логарифмически нормального распределения получить нормальное распределение?
19 Какими статистическими параметрами задается логарифмически нормальное распределение?
ТЕМА 5 Распределения параметров выборки
5.1 t – распределение Стьюдента
5.2 F-распределение Фишера–Снедекора
5.3 χ2–распределение
5.1 t – распределение Стьюдента
Закон нормального распределения проявляется при числе признаков n > 20–30. Однако экспериментатор часто проводит ограниченное число измерений, основывает свои выводы на малых выборках. При небольшом числе наблюдений результаты обычно близки и редко появляются большие отклонения. Это легко объяснить законом нормального распределения, согласно которому вероятность появления малых отклонений больше, чем отклонений значительных. Так, вероятность отклонений, превышающих по абсолютной величине ±2σ, равна 0,05, или один случай на 20 измерений, а отклонений ± 3σ – 0,01, или один случай на 100.
Если же полевой опыт проводят, например, в 4 – 6 повторностях, то естественно ожидать, что среди показаний урожаев на параллельных делянках очень больших отклонений не будет. Поэтому стандартное отклонение s, подсчитанное по малой выборке, в большинстве случаев будет меньше, чем по всей генеральной совокупности  . Следовательно, в этих случаях полагаться на критерии нормального распределения в своих выводах нельзя.
. Следовательно, в этих случаях полагаться на критерии нормального распределения в своих выводах нельзя.
С начала XX века в математической статистике стало разрабатываться новое направление, которое можно назвать статистикой малых выборок. Наибольшее практическое значение для экспериментальной работы имело открытое в 1908 г. английским статистиком и химиком В. Госсетом t–распределение, получившее название распределения Стьюдента (англ. стьюдент – студент, псевдоним В. Госсета).
Распределение t Стьюдента для выборочных средних определяется равенством:
 (5.1)
(5.1)
Числитель формулы означает отклонение выборочной средней от средней всей совокупности  , а знаменатель:
, а знаменатель:
 – является показателем, оценивающим величину стандартной ошибки средней выборочной совокупности.
– является показателем, оценивающим величину стандартной ошибки средней выборочной совокупности.
Таким образом, величина t измеряется отклонением выборочной средней  от средней совокупности , выраженным в долях ошибки выборки
от средней совокупности , выраженным в долях ошибки выборки  , принятой за единицу.
, принятой за единицу.
Максимумы частоты нормального и t-распределения совпадают, но форма кривой t-распределения всецело зависит от числа степеней свободы. При очень малых значениях степеней свободы она принимает вид плосковершинной кривой, причем площадь, отграниченная кривой, больше, чем при нормальном распределении, а при увеличении числа наблюдений (n > 30) распределение t приближается к нормальному и переходит в него при n = ∞.
На рисунке 1.1 представлено дифференциальное и интегральное распределение t-Стьюдента при 10 степенях свободы.

Рисунок 5.1 – Дифференциальное (слева) и интегральное (справа) распределение t–Стьюдента
Распределение t–Стьюдента имеет важное значение при работе с малыми выборками: позволяет определить доверительный интервал, накрывающий среднюю совокупности , и проверить ту или иную гипотезу относительно генеральной совокупности. При этом нет необходимости знать параметры совокупности и , достаточно иметь их оценки μ и σ для определенного объема выборки n.
5.1.1 Проблема Беренса–Фишера
Проверка гипотезы о генеральных средних двух групп с нормальным распределением и неравными дисперсиями в математической статистике называется проблемой Беренса–Фишера и имеет в настоящее время только приближенные решения. Почему так важно требование равенства дисперсий в сравниваемых группах? Не вдаваясь в детали этой проблемы, отметим, что чем больше различаются между собой дисперсии и объемы выборок, тем сильнее отличается распределение "вычисляемого t-критерия" от распределения "t-критерия Стьюдента". При этом различную величину имеет как сам t-критерий, так и такой параметр этих распределений, как число степеней свободы. В свою очередь число степеней свободы сказывается на величине достигнутого (критического) уровня значимости (р <...) определяемого для вычисленного значения t-критерия.
Пренебрежение исследователями, приведенными выше условиями допустимости использования t-критерия Стьюдента, приводит к существенному искажению результатов проверки гипотез о равенстве средних. Поэтому в работах, где проверка гипотез о равенстве двух средних производилась с помощью t-критерия Стьюдента, и нет упоминания критериев проверки нормальности распределения и равенства дисперсий, имеются основания предполагать некорректное использование авторами данного критерия, а стало быть, и сомнительность декларируемых ими выводов.
Другая частая ошибка – применение t–критерия Стьюдента для проверки гипотез о равенстве трех и более групповых средних. В этом случае необходимо применять так называемую общую линейную модель, реализованную в процедуре однофакторного дисперсионного анализа с фиксированными эффектами.
Рассмотрим подробнее особенности использования t–критерия Стьюдента. Наиболее часто t–критерий используется в двух случаях. В первом случае его применяют для проверки гипотезы о равенстве генеральных средних двух независимых, несвязанных выборок (так называемый двухвыборочный t–критерий). В этом случае есть контрольная группа и опытная группа, состоящая из разных объектов, количество которых в группах может быть различно. Во втором же случае используется так называемый парный t–критерий, когда одна и та же группа объектов порождает числовой материал для проверки гипотез о средних. Поэтому эти выборки называют зависимыми, связанными. Например, измеряется содержание лейкоцитов у здоровых животных, а затем у тех же самых животных после облучения определенной дозой излучения. В обоих случаях должно выполняться требование нормальности распределения исследуемого признака в каждой из сравниваемых групп. Доминирование t–критерия Стьюдента в подавляющем большинстве работ отражает два важных аспекта.
Во-первых, это свидетельство того, что авторы, использующие данный критерий, не имеют необходимых знаний относительно ограничений присущих данному критерию.
Во-вторых, это говорит также и о том, что этим авторам неизвестны какие-либо альтернативы данному критерию, либо они не в состоянии ими самостоятельно воспользоваться. Можно без преувеличения сказать, что в настоящее время бездумное применение t–критерия Стьюдента в большинстве биологических работ приносит больше вреда, нежели пользы.
5.2 F-распределение Фишера–Снедекора
Если из нормально распределенной совокупности взять две независимые выборки объемом n1 и n2 и подсчитать дисперсии  и
и  со степенями свободы ν1 = n –1 и ν2 = n2–1, то можно определить отношение дисперсий:
со степенями свободы ν1 = n –1 и ν2 = n2–1, то можно определить отношение дисперсий:
 (5.2)
(5.2)
Отношение дисперсий берут таким, чтобы в числителе была большая дисперсия, и поэтому F ≥ 1.
Распределение F зависит только от числа степеней свободы ν1 и ν2 (закон F-распределения открыл Р.А. Фи шер). Когда две сравниваемые выборки являются случайными независимыми из общей совокупности с генеральной средней , то фактическое значение F не выйдет за определенные пределы и не превысит критическое для данных ν1 и ν2 теоретическое значение критерия F (Fфакт < Fтеор). Если генеральные параметры сравниваемых групп различны, то Fфакт > Fтеор. Теоретические значения F для 5%-ного и 1%-ного уровня значимости даны в таблице, где табулированы только правые критические точки для F ≥ 1, так как всегда принято находить отношение большей дисперсии к меньшей.
Кривые, полученные из функции распределения для всех возможных значений F, особенно при небольшом числе наблюдений, имеют асимметричную форму – длинный «хвост» больших значений и большую концентрацию малых величин F (рисунок 5.2).

Рисунок 5.2 – Дифференциальное (слева) и интегральное (справа)
F-распределение Фишера–Снедекора
Отметим, что t–распределение Стьюдента является частным случаем F–распределения при числе степеней свободы ν1 = 1 и ν2 = ν, т. е. равно числу степеней свободы для распределения t. В этом случае наблюдается следующее соотношение между F и t:
 (5.3)
(5.3)
5.3 χ2–распределение
Многие фактические распределения соответствуют моделям теоретических распределений (нормальное, биномиальное, Пуассона) Однако, на практике существуют распределения, сильно отличающиеся от нормального. Для оценки степени расхождения или степени согласия между численностями фактического и теоретического распределений вводятся статистические критерии согласия, например критерий χ2. Этот критерий применяется для решения задач статистического анализа, например для проверки гипотез: о независимости двух принципов, положенных в основу группировки результатов наблюдений из одной совокупности; об однородности групп в отношении некоторых определяемых характеристик; о согласии теоретической и экспериментальной кривых численностей. Критерий χ2 может называться как критерием согласия, так и критерием независимости, критерием однородности. Закон распределения χ2 (хи–квадрат) открыл К. Пирсон. Кривая распределения, полученная из функции хи–квадрат:
 (5.4)
(5.4)
где f – фактические и F – теоретические частоты численности объектов выборки. Ее вид в сильной степени зависит от числа степеней свободы. Для малого числа степеней свободы ν кривая асимметрична (рисунок 5.3), но с увеличением ν асимметрия уменьшается и при ν = ∞ кривая становится нормальной гауссовой.
Распределение χ2, так же как и t–распределение, частный случай
F – распределения при ν1 = ν и ν2 = ∞.

Рисунок 5.3 – Дифференциальное (слева) и интегральное (справа)
χ2–распределение
Вопросы для самоконтроля
1 В каких случаях предпочтительнее использовать t-распределение Стьюдента, а не нормальное распределение?
2 Какие величины необходимо оценивать для использования t-распределения Стьюдента?
3 В чем суть проблемы Беренса–Фишера?
4 Чем численно выражается F-распределение для двух независимых выборок из общей совокупности переменных?
5 От каких характерных величин случайных переменных зависит F-распределение?
6 На какие вопросы может ответить значение критерия χ2 при статистической обработке экспериментальных данных?
ТЕМА 6 Основы математической статистики
6.1 Средние величины
6.2 Средняя арифметическая
6.3 Средняя геометрическая
6.4 Средняя гармоническая
Средние величины
Из всех групповых свойств наибольшее теоретическое и практическое значение имеет средний уровень, измеряемый средней величиной признака.
Средняя величина признака – понятие очень глубокое, появившееся в науке и практике только на определенном этапе развития человеческого мышления. Всякая средняя величина обладает тремя основными свойствами: срединным положением, абстрактностью (отвлечение от реально существующего разнообразия) и единством суммарного действия.
Средняя величина признака определяется различными способами в зависимости от объектов наблюдения, изучаемых признаков и целей исследования. Поэтому имеется не одна, а несколько средних: средняя арифметическая, средняя геометрическая, средняя квадратическая, средняя гармоническая, мода, медиана.
Основной показатель – средняя величина – широко используется и в науке, и в практике. При изучении растений, животных, микроорганизмов и человека расчет средних показателей составляет основу обработки первичных материалов.
Средние размеры особей служат для характеристики видов, разновидностей, сортов, пород и других биологических групп; средние показатели физиологических процессов характеризуют интенсивность различных сторон обмена, силу действия биологических агентов и медицинских препаратов.
В производстве средние показатели используются для оценки работы отдельных специалистов, хозяйств, областей.
Средняя величина какого-нибудь признака определяется для того, чтобы получить характеристику этого признака для всей изучаемой группы в целом.
 (6.1)
(6.1)
В зависимости от объекта наблюдения и от поставленных целей используются в биологии не одна, а несколько средних величин: средняя арифметическая, средняя геометрическая, средняя квадратическая, средняя гармоническая. Кроме того, для характеристики биологических групп иногда употребляются мода и медиана.

