




Ко второму важному классу параллельных машин относятся многопроцессорные системы с распределенной областью памяти (МРА). МРА используют законченные компьютеры, включающие микропроцессор, память и подсистему ввода/вывода, как узлы для построения системы, объединенные коммуникационной средой, обеспечивающую взаимодействие процессоров посредством простых операций ввода-вывода. Структура высокого уровня для МРА практически такая же, как и для MPA-машин, т. е. машин с разделяемой памятью, показанных на рис. 9.6. Первое отличие состоит в том, что коммуникации интегрированы в уровень ввода/вывода, а не в систему доступа к памяти. Этот стиль дизайна имеет много общего с сетями из рабочих станций или кластерными системами, за исключением того, что в МРА пакетирование узлов обычно более плотное, нет монитора и клавиатуры на каждом узле, а производительность сети намного выше стандартной. Интеграция между процессором и сетью имеет склонность быть более тесной, чем традиционные структуры ввода/вывода, которые поддерживают соединения с оборудованием, которое более медленное, чем процессор. Начиная с посылки сообщения МРА, есть фундаментальное взаимодействие «Процессор — Процессор».
Системы с распределенной памятью имеют существенную дистанцию между программной моделью и действительными аппаратными примитивами. Коммуникации осуществляются через средства операционной системы, или библиотеку вызовов, которые выполняют много акций более низкого уровня, включающих операции коммуникации.

Рис. 9.8. Принцип взаимодействия процессов в системах с распределенной областью памяти
Наиболее общие операции взаимодействия на пользовательском уровне есть варианты посылки(Send) и получения(Receive) сообщения. Совместный механизм Send и Receive вызванный передачей данных из одного процесса в другой, показан на рис 9.8.
Передача данных из одного локального адресного пространства к другому произойдет, если посылка сообщения со стороны процесса-отправителя будет востребована процессом-получателем сообщения.
С этой целью в большинстве систем с распределенной памятью сообщение специфицируется операцией Send, которая добавляет к сообщению специальный признак (tag), а операция Receive в этом случае выполняет проверку сравнения данного признака.
Сочетание посылки и согласованного приема сообщения (на основе совпадения признаков) выполняет логическую связку — синхронизацию события, т. е. копирования из памяти в память. Имеется несколько возможных вариантов синхронизации этих событий в зависимости от того, завершиться ли Send к моменту, когда Receive будет выполнен или нет (т. е. будет ли снова доступен буфер посылки для использования до момента получения подтверждения приема). Похожим образом Е может, в принципе, подождать до момента согласованной посылки (Send) или использовать "почтовый ящик" для получения сообщения. Каждый из этих вариантов имеет несколько различную интерпретацию и различные требования к реализации.
Механизм посылки сообщений долго использовался как средство коммуникации и синхронизации совокупности арбитрирующих взаимодействующих последовательных процессов, даже на одном процессоре. В качестве примеров можно привести языки программирования типа CSP и Occam, наиболее общие функции операционных систем типа Sockets.
Первые машины с распределенной областью памяти обеспечивали аппаратную поддержку примитивов (команд), которые очень напоминали простую абстракцию взаимодействия Send/ Receive на пользовательском уровне с некоторыми дополнительными ограничениями. Каждый узел системы соединялся с определенным (фиксированным) числом соседей по регулярной схеме (образцу) на основе связи «точка-точка» поведение которой, в свою очередь, описывалось простым FIFO. Такой тип конструкции для минимального 3D-куба показан на рис. 9.9, где каждый узел имеет связи с соседями по трем направлениям через буфер FIFO.
В ранних системах обычно использовалась структура гиперкуба (на 2n узлов), в которой каждый узел соединялся с n другими узлами, бинарные адреса которых отличались на один бит. Другие машины имели решетчатую структуру, где узлы соединялись с соседями по двум или трем измерениям. Такая технология для более ранних машин была важна, потому что только соседние процессоры могли быть использованы в качестве адресата в операциях приема/посылки. Процесс-отправитель посылал сообщение, а процесс-получатель получал сообщение через канал-link.FIFO было маленьким, так что отправитель не успевал закончить формирование сообщения до момента, когда получатель начинал его читать, поэтому посылка блокировалась до момента начала приема (на современном языке это называется синхронной передачей сообщений, так как два события совпадают по времени).Детали передачи данных были скрыты от программиста в специальной библиотеке, формирующей слой программного обеспечения между запросами на прием и передачу и реальным аппаратным обеспечением.
Такое внимание к сетевой топологии было значительно ослаблено в связи с появлением гораздо более универсальных сетей, которые поплайнизировали передачу сообщения через каждый коммутатор, формирующий внутреннюю сеть. В наиболее современных машинах с распределенной памятью нарастающая задержка, вносимая каждым этапом передачи (скачком), достаточно мала. Это существенно упрощает программную модель. Обычно процессор рассматривается как простой формирователь линейной последовательности с одинаковыми затратами на коммуникацию. другими словами, коммуникационная абстракция отражает главным образом организационную структуру, показанную на рис. 9.6. Один из важных примеров такой машины является IBM SP-2 (рис. 9.10).
Это масштабируемый параллельный компьютер, состоящий из узлов на базе рабочих станций RS6000 масштабируемой сети и сетевым интерфейсом NI, содержащим специализированный процессор (i860). NIC соединен с MicroChannel I/O bus и содержит драйверы сетевого линка, память (DRAM) для буферирования сообщений. для реализации ОМА модуль содержит процессор i860, управляющий перемещением данных между памятью и сетью. Сеть представляет собой каскадное 8 ´ 8 коммутируемое перекрестное соединение (см. рис. 9.3, а). Скорость передачи сообщений по линкам составляет 40 Мб/с в каждом направлении.

Рис. 9.9. Типовая структура первых систем с распределенной областью памяти

Рис. 9.10. Параллельный суперкомпьютер IBM SР-2
Другим примером является параллельный компьютер Intel Paragon, показанный на рис. 9.11.
Intel Paragon иллюстрирует наиболее плотное аппаратное пакетирование в узлах. Каждая плата (узел) представляет собой SMP с двумя или более процессорами (i860) и кристалл сетевого интерфейса (NI) связанный с шиной памяти. Один из процессоров специализируется на обслуживании сети. Узел имеет механизм DMA для передачи блоков данных через сеть высокого уровня. Сеть представляет собой ЗD-куб, аналогичный структуре сети компьютера CRAY ТЗЕ. Линки имеют пропускную способностью 175 Мб/с в каждом направлении.
МРА и разделяемое адресное пространство являются двумя очевидно различными программными Моделями, каждая из которых обеспечивает ясную парадигму для разделения коммуникации и синхронизации. Тем не менее лежащие в основе данных машин базовые структуры постепенно объединяются в рамках общей организации, представляемой набором законченных компьютеров, усиленных специальным контроллером, соединяющим каждый узел с расширяемой коммуникационной сетью. Подробнее обобщенная архитектура параллельных систем будет рассмотрена в п. 9.6.

Рис. 9.11. Параллельный суперкомпьютер Intel Paragon
МАТРИЧНЫЕ СИСТЕМЫ
Третий важный класс параллельных машин — матричные системы — относятся к классу signal instruction multiple data machines(SIMD). Ключевой характеристикой ЭТОЙ модели программирования является то, что операция может быть выполнена параллельно на каждом элементе большой регулярной структуры данных, таких как массивы и матрицы.
Компьютерная таксономия, появившаяся в изданиях начала 1970-х годов, определяет структуру системы в терминах числа одновременно выполняемых различных инструкций и числа обрабатываемых элементов данных. В этом случае обычные последовательные компьютеры определяются как системы с одиночным потоком команд и одиночным потоком данных — (SISD), а параллельные машины, построенные из множества обычных процессоров как системы с множественным потоком команд и множественным потоком данных (МIМD). Альтернативой им стали системы класса одиночного потока команд и множественного потока данных — (SIMD). Исторически такой подход появился в середине 1960-х. Идея была в том, что вся последовательность инструкций могла бы быть консолидирована в управляющем процессоре. Процессор данных включал бы только АLU память и обеспечивал простое взаимодействие с ближайшими соседями.
В SIMD-машинах модель программирования была напрямую реализована в физическом аппаратном уровне. Обычно управляющий процессор (Пр) осуществлял рассылку каждой инструкции по массиву процессорных элементов, которые были соединены между собой в форме регулярной решетки, как показано на рис. 9.12.
Матричные системы ориентированы на большой класс вычислительных задач, которые требуют выполнения матричных операций или обработки массивов, т.е. когда выполняются одинаковые операции на уровне каждого элемента массива или матрицы, Вовлекающие в процесс вычисления соседние элементы. Таким образом, управляющий процессор инструктирует процессоры данных по выполнению каждой операции над локальным элементом данных или все выполняют операцию коммуникации/обмена данных (все сразу).
В дальнейшем, в середине 1970-х, векторные процессоры затмили собой развитие других многопроцессорных систем. Векторные процессоры интегрировали скалярный процессор с коллекцией функциональных единиц, которые оперировали с векторными данными на памяти с поплайновой организацией. Способность оперировать над векторами в любом месте памяти ликвидировала необходимость размещения используемых структур данных в жесткую структуру внутренних связей и значительно упростила проблему получения объединенных данных.
Набор команд первого векторного процессора CDC Star-100 включал в себя векторные операции, которые позволяли комбинировать два источника векторов из памяти и создавать в памяти вектор результата. Машина работала на полной скорости тогда, когда векторы были соседними и, следовательно, основное время тратилось на простое транспонирование матриц. Сенсационное изменение произошло в 1976 г., когда был представлен СREY-1 в котором концепция LOAD-STORE архитектуры была расширенна на обработку векторов и реализована в процессорах СDС 6600 и СDС 7600 (и продолжена в современных RISC-машинах. Векторы в памяти с любым фиксированным шагом по индексу были перенесены в или из соседних (близких) регистров посредством загрузки вектора и хранения инструкций. Арифметика выполнялась на векторных регистрах. Использование очень быстрых скалярных процессоров (80 МНz), интегрированных с векторными операциями и использующих большую полупроводниковую память, привело к мировому господству суперкомпьютеров рассматриваемого класса. Более чем 20 последующих лет CRAY Research лидировал на суперкопьютерном рынке, увеличивая пропускную способность передачи векторов в памяти, число процессоров, число векторных поплайнов и длину векторных регистров.
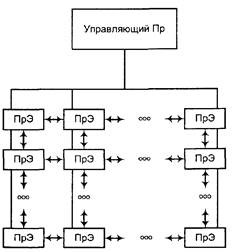
Рис. 9.12. Структура матричных систем
Второй раз SIMD-компьютеры пережили эпоху своего возрождения в середине 1980-х, когда развитие VLSI-design привело к появлению доступного 32-разрядного микропроцессора (это были так называемые одноразрядные секционные микропроцессоры, или микропроцессоры с разрядно-модульной организацией). В уникальной петлевой архитектуре в data parallel-режиме было размещено 32 простых одноразрядных элементарных процессора на одном чипе, вместе с серией соединений с соседними процессорами. Совокупность последовательных инструкций была размещена на управляющем процессоре. Главное было в том, что такие системы с несколькими серийными процессорными элементами были созданы и имели разумную цену.
В дальнейшем технологические факторы, которые с это bit-serial-проектирование привлекательным и обеспечили быстрое и недорогое проектирование на базе однокристальных процессоров с плавающей точкой, проложили путь очень быстрым микропроцессорам с интегрированными плавающими запятыми и кэш-памятью. Это устранило ценовые преимущества консолидированной последовательной логики, описанной выше, и обеспечило равенство пиковой производительности на более малом числе полных процессоров.
Таким образом, пока существует пользовательский уровень абстракции параллельных операций на больших регулярных структурах данных, продолжается и предложение интересных решений для рассматриваемого важного класса проблем. Машинная организация, поддерживая модели data parallel programming models, развивается по направлению к более общим параллельным архитектурам множественной кооперации микропроцессоров, более масштабируемой разделяемой памяти и МРА-машинам, несмотря на то, что существуют решения в области создания специализированных компьютерных сетей, поддерживающие глобальную синхронизацию процессоров. В последнем случае сетевая поддержка выступает в роли барьера, который в особых точках программы переводит каждый процесс в режим ожидания до тех пор, пока остальные процессы не достигнут заданной точки синхронизации. В действительности, SIMD-подход эволюционировал в SPMD подход, в котором все процессоры выполняют копии одних и тех же программ и имеют, таким образом, в большей мере схожесть с более структурированными формами разделяемой памяти и МР-программирования.
В середине 1980-х возрождение SIMD привело к появлению других архитектурных направлений, которые были исследованы в академических институтах и промышленности, но имели меньший коммерческий успех и поэтому не получили широкого распространения по сравнению с рассмотренными выше. Два подхода, которые развилось до законченных программных систем, — dataflow architecture и systonic architecture.

