




Оценивает отклонение теоретических оценок от реальных. Ошибка аппроксимации ε. Формула 17.
Значение этой ошибки, не превышающее 8-10% говорит о хорошем качестве уравнения регрессии.
Εср=2,62/30*100%=8,7%.
В регрессионном анализе общая колеблемость результата представляется следующим образом:
∑= 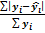 *100%
*100%
∑(y- 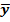 )2=∑(yi-
)2=∑(yi- 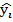 )2+∑( -yi)2
)2+∑( -yi)2
∑(y- 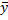 )2-общая колеблемость результата, ∑(y-
)2-общая колеблемость результата, ∑(y- 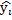 )2–от фактических данных отнимаем теоретические = остаточная колеблемость, ∑( -yi)2 –колеблемость результата, объясненная уравнением регрессии
)2–от фактических данных отнимаем теоретические = остаточная колеблемость, ∑( -yi)2 –колеблемость результата, объясненная уравнением регрессии
Это разложение вариации зависимой переменной лежит в основе качества полученного уравнения регрессии, т.е. чем бОльшая часть вариации у объясняется уравнением регрессии, тем лучше качество уравнения, т.е. правильно выбран тип функции для описания зависимости результата и фактора y=f(x) и правильно выбрана сама объясняющая переменная х. отношение объясненной вариации к общей позволяет найти индекс детерминации η2.
η2= 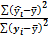
Он определяет степень детерминации регрессией вариации у. Корень квадратный из индекса детерминации называется теоретическим корреляционным отношением, оно показывает тесноту связи между результатом и фактором, как при линейной, так и при нелинейной связи. Измеряется η[0,1].
В нашем примере ∑( - )2=∑(yi- ))2+∑( 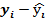 )2 = 7,5-1,094=6,064,
)2 = 7,5-1,094=6,064,
η2 =6,406/7,5=0,85 (85%)
Оценка значимости производится на основе F-критерия Фишера, которому предшествует дисперсионный анализ, применяемый как вспомогательное средство для изучения качества регрессионной модели. Схему дисперсионного анализа представим в таблице, где n-число наблюдений, а m-число параметров при х.
Таблица дисперсионного анализа
| Компоненты дисперсии | Сумма квадратов (SS) | Число степеней свободы (df) | Дисперсия на одну степень свободы (MS) |
| Общая дисперсия | 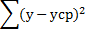
| n-1 | 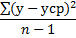
|
| Факторная | 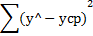
| m | 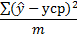
|
| Остаточная | 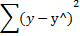
| n-m-1 | 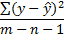
|
Дисперсия на одну степень свободы приводит дисперсии к сопоставимому виду. Поэтому, сопоставляя факторную и остаточную дисперсии, получают фактическое значение F-критерия Фишера.
F=MSФАКТ/MSОСТ
Фактическое значение F-критерия Фишера сравнивается с табличным значением F-критерия Фишера Fтабл(α,k1,k2), которое зависит от уровня значимости α и степеней свободы k1 (факторная), k2(остаточная).
Если фактическое значение F-критерия Фишера больше табличного, то уравнение регрессии является статистически значимым в целом
Для парной линейной регрессии этот пример может быть записан следующим образом:
Fфакт= 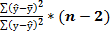 , Fфакт=
, Fфакт= 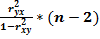
F-критерий Фишера говорит о статистической значимости уравнения. В парной линейной регрессии оценивается значимость отдельных параметров уравнения регрессии aи b. С этой целью определяется его стандартная ошибка:
mb=MSост/σx 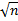
t-критерий Стьюдента. Для оценки существенности коэф-та регрессии определяется фактическое значение t-критерия Стьюдента: фактическое значение t-критерия Стьюдента для параметра b:
tb=b/mb
Далее это фактическое значение сравнивается с табличным значением t-критерия Стьюдента, которое зависит от уровня значимости α и числа степеней свободы df (n-2).
Если фактическое значение больше табличного, то параметр регрессии статистически значим. Кроме того, можно определить границы доверительного интервала коэф-та регрессии b.
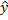 =a+bx
=a+bx
b±∆(предельная ошибка)
b-∆b≤b≤b+∆b
∆b=tтабл*m*b, где∆b–предельная ошибка коэф-та регрессии b.
Если -2≤b≤3, значит, b-статистически незначим.
Стандартной ошибкой для параметра аma = MSост 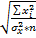 .
.
Значимость параметра а определяется аналогично параметру b.
ta=a/∆ma
ta=a/ma>ta(α, df)
Если фактическое больше табличного – параметр статистически значим.
Аналогичным образом проверяется статистическая значимость линейногокоэф-та кореляции.
mσyx= 
И это значение сравнивается с табличным значением t-критерия Стьюдента.
При прогнозировании по уравнению регрессии вычисляется прогнозное значение результата (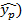 подстановкой в уравнение регрессии прогнозного или желаемого значения фактора.
подстановкой в уравнение регрессии прогнозного или желаемого значения фактора.
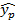 =a+bxnp
=a+bxnp
Полученное по этому уравнению значение результат называется точечным прогнозом.
Здесь также считаются доверительные интервалы прогноза. Они считаются следующим образом:
yp-∆y≤ ≤yp+∆p, где ∆p– предельная ошибка прогноза.
∆y=tтабл*my, где my- стандартная ошибка прогноза
mУp=MSост * 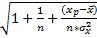 , где
, где  - фактическое значение исходных данных.
- фактическое значение исходных данных.
Выполнить корреляционно-регрессионный анализ можно, воспользовавшись пакетами прикладных программ. Самый простой – Excel.
Нужно в закладке «Данные» - «Анализ данных» - «Регрессия» - «Входной интервал у»
| х | у |
Поставить флажок «Метки», «Const 0» – флажка не должно быть, иначе параметр а = 0. Дальше «Выходной интервал» номер свободной ячейки на рабочем листе – Ок.
Вывод итогов представляет собой 3 таблички:
1. Регрессионная статистика
| МножественныйR (парный линейный коэф-т корреляции) | |
| R-квадрат (коэф-т детерминации) | |
| НормированныйR-квадрат (скорректированный коэф-т корреляции) | |
| Стандартная ошибка коэф-та корреляции | |
| Наблюдение |
2. Дисперсионный анализ
| df | SS | MS | F | F значимое | |
| Регрессия (факторная) | |||||
| Остаток | |||||
| Итого: |
3.
| Коэф-ты | Стандартная ошибка параметров | t-статистика (факт. значения t-критерия для параметров а и b) | Нижняя 95% | Верхняя 95% (границы доверительного интервала) | |
| У - пересечение | Параметр а | Число | |||
| х | b | Число |
95% -означает, что уровень значимости α = 5% (вероятность – 95%).

