




3. Как было показано в пункте 1, факторы Х 1 и Х 3 являются коллинеарными и фактически дублируют друг друга. Их одновременное включение в модель приведет к неправильной интерпретации соответствующих коэффициентов уравнения регрессии. Поэтому модель с полным перечнем факторов, построенная при выполнении предыдущего пункта, не вполне корректна. Из указанных коллинеарных факторов фактор Х 3 имеет больший по абсолютной величине коэффициент корреляции с результатом Y: 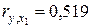 ;
;  ;
;  (см. табл. 3.3). Кроме того, в уравнении регрессии с полным перечнем факторов t ‑статистика коэффициента при факторе Х 3 (
(см. табл. 3.3). Кроме того, в уравнении регрессии с полным перечнем факторов t ‑статистика коэффициента при факторе Х 3 ( ) больше по абсолютной величине t -статистики коэффициента при факторе Х 1 (
) больше по абсолютной величине t -статистики коэффициента при факторе Х 1 ( ). Все это свидетельствует о более сильном влиянии фактора Х 3 на изменение зависимой переменной Y. Фактор Х 1, таким образом, исключается из рассмотрения и вторая модель будет содержать факторы X 2, X 3, X 4, X 5 и X 6. По аналогии с пунктом 2 строим второе уравнение регрессии (табл. 3.5):
). Все это свидетельствует о более сильном влиянии фактора Х 3 на изменение зависимой переменной Y. Фактор Х 1, таким образом, исключается из рассмотрения и вторая модель будет содержать факторы X 2, X 3, X 4, X 5 и X 6. По аналогии с пунктом 2 строим второе уравнение регрессии (табл. 3.5):
 .
.
Уравнение регрессии признается статистически значимым, так как вероятность его случайного формирования (8,80×10-6) существенно ниже принятого уровня значимости a=0,05. Вероятности случайного формирования коэффициентов при факторах Х 3, Х 4, Х 6 ниже уровня a=0,05, что свидетельствует об их статистической значимости (см. табл. 3.5). Что касается факторов Х 2 и Х 5 (выделены в табл. 3.5 заливкой), то «P‑Значение» их коэффициентов выше уровня a=0,05. Эти коэффициенты не признаются значимыми.
| Таблица | 3.5 |
| Результаты регрессионного анализа модели Y (X 2, X 3, X 4, X 5, X 6) |
| Регрессионная статистика | |||||||||
| Множественный R | 0,868 | ||||||||
| R-квадрат | 0,753 | ||||||||
| Нормированный R-квадрат | 0,694 | ||||||||
| Стандартная ошибка | 242,3 | ||||||||
| Наблюдения | |||||||||
| Дисперсионный анализ | |||||||||
| df | SS | MS | F | Значимость F | |||||
| Регрессия | 3749838,2 | 749967,6 | 12,78 | 8,80E-06 | |||||
| Остаток | 1232466,8 | 58688,9 | |||||||
| Итого | 4982305,0 | ||||||||
| Уравнение регрессии | |||||||||
| Коэффициенты | Стандартная ошибка | t-статистика | P-Значение | ||||||
| Y-пересечение | 487,5 | 641,4 | 0,760 | 0,456 | |||||
| X2 | -0,0456 | 0,0373 | -1,224 | 0,235 | |||||
| X3 | 0,1043 | 0,0194 | 5,375 | 0,00002 | |||||
| X4 | -0,0965 | 0,0263 | -3,674 | 0,001 | |||||
| X5 | 2,528 | 6,323 | 0,400 | 0,693 | |||||
| X6 | 248,2 | 113,0 | 2,197 | 0,039 | |||||
4. По результатам выполнения предыдущего пункта строим новую регрессионную модель, содержащую только информативные факторы. Такими факторами считаются те, у коэффициентов которых t ‑статистика превышает по абсолютной величине единицу, т.е. абсолютная величина коэффициента больше его стандартной ошибки — факторы X 2, Х 3, Х 4, Х 6. Фактор X 5 исключается из рассмотрения как неинформативный (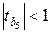 ). Результаты регрессионного анализа приведены в табл. 3.6. Само уравнение регрессии имеет вид:
). Результаты регрессионного анализа приведены в табл. 3.6. Само уравнение регрессии имеет вид:
 .
.
Статистически значимыми являются уравнение регрессии в целом и коэффициенты при факторах Х 3, Х 4, Х 6 (см. табл. 3.6). Это свидетельствует о существенном влиянии данных факторов на изменение годовой прибыли Y.
Коэффициент при факторе Х 2 не является статистически значимым (выделен в табл. 3.6 заливкой). Однако этот фактор можно считать информативным, так как t ‑статистика его коэффициента превышает по абсолютной величине единицу, хотя к дальнейшим выводам относительно Х 2 следует относиться с некоторой осторожностью.
| Таблица | 3.6 |
| Результаты регрессионного анализа модели Y (X 2, X 3, X 4, X 6) |
| Регрессионная статистика | |||||||||
| Множественный R | 0,866 | ||||||||
| R-квадрат | 0,751 | ||||||||
| Нормированный R-квадрат | 0,705 | ||||||||
| Стандартная ошибка | 237,6 | ||||||||
| Наблюдения | |||||||||
| Дисперсионный анализ | |||||||||
| df | SS | MS | F | Значимость F | |||||
| Регрессия | 3740456,2 | 935114,1 | 16,57 | 2,14E-06 | |||||
| Остаток | 1241848,7 | 56447,7 | |||||||
| Итого | 4982305,0 | ||||||||
| Уравнение регрессии | |||||||||
| Коэффициенты | Стандартная ошибка | t-статистика | P-Значение | ||||||
| Y-пересечение | 712,2 | 303,0 | 2,351 | 0,028 | |||||
| X2 | -0,0541 | 0,0300 | -1,806 | 0,085 | |||||
| X3 | 0,1032 | 0,0188 | 5,476 | 0,00002 | |||||
| X4 | -0,1017 | 0,0223 | -4,560 | 0,00015 | |||||
| X6 | 227,5 | 98,5 | 2,310 | 0,031 | |||||
5. В таблице результатов регрессионного анализа имеются и другие статистические характеристики уравнения регрессия, в частности, множественный коэффициент детерминации  , скорректированный (нормированный) коэффициент детерминации
, скорректированный (нормированный) коэффициент детерминации 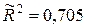 и стандартная ошибка регрессии
и стандартная ошибка регрессии  тыс. руб. (см. «Регрессионную статистику» в табл. 3.6).
тыс. руб. (см. «Регрессионную статистику» в табл. 3.6).
Значение коэффициента детерминации R 2 показывает, что регрессионная модель объясняет 75,1 % вариации годовой прибыли Y страховой компании, причем эта вариация обусловлена изменчивостью включенных в модель факторов X 2, X 3, X 4 и X 6. Скорректированный коэффициент детерминации  превышает 0,5, что свидетельствует об удовлетворительном качестве модели.
превышает 0,5, что свидетельствует об удовлетворительном качестве модели.
Оценим точность уравнения регрессии через среднюю относительную ошибку аппроксимации, определяемую по приближенной формуле
 ,
,
где  тыс. руб. — среднее значение прибыли (функция «СРЗНАЧ»).
тыс. руб. — среднее значение прибыли (функция «СРЗНАЧ»).
Значение Е отн показывает, что предсказанные уравнением регрессии значения результата Y отличаются от фактических значений в среднем на 26,7 %. Точность последней модели — удовлетворительная ( ).
).
6. Дадим экономическую интерпретацию коэффициентам уравнения регрессии. Для удобства сведем в таблицу средние значения и стандартные отклонения переменных Y, X 2, X 3, X 4, X 6 в исходных данных (табл. 3.7). Средние значения определялись с помощью встроенной функции «СРЗНАЧ», а стандартные отклонения — с помощью функции «СТАНДОТКЛОН».
| Таблица | 3.7 |
| Средние значения и стандартные отклонения переменных Y, X 2, X 3, X 4, X 6 |
| Переменная | Y | X 2 | X 3 | X 4 | X 6 |
| Среднее | 713,0 | 5980,6 | 7334,0 | 5327,6 | 0,481 |
| Стандартное отклонение | 437,8 | 1575,7 | 2671,9 | 2120,5 | 0,509 |
1) Фактор X 2 (годовой размер страховых резервов)
Значение коэффициента b 2=–0,0541 показывает, что рост годового размера страховых резервов на 1 тыс. руб. приводит к снижению годовой прибыли страховой компании в среднем на 0,0541 тыс. руб.
Средний коэффициент эластичности фактора X 2 имеет значение
 .
.
Это означает, что при увеличении годового размера страховых резервов на 1 % годовая прибыль уменьшается в среднем на 0,454 %.
2) Фактор X 3 (годовой размер страховых премий)
Коэффициент b 3=0,1032 показывает, что рост годового размера страховых премий на 1 тыс. руб. приводит к увеличению годовой прибыли в среднем на 0,1032 тыс. руб.
Средний коэффициент эластичности

показывает, что при увеличении годового размера страховых премий на 1 % годовая прибыль увеличивается в среднем на 1,062 %.
3) Фактор X 4 (годовой размер страховых выплат)
Значение коэффициента b 4=–0,1017 показывает, что рост годового размера страховых выплат на 1 тыс. руб. приводит к уменьшению годовой прибыли в среднем на 0,1017 тыс. руб.
Средний коэффициент эластичности фактора X 4 равен
 .
.
Значение E4 показывает, что при увеличении годового размера страховых выплат на 1 % годовая прибыль уменьшается в среднем на 0,760 %.
4) Фактор X 6 (форма собственности)
Коэффициент b 6=227,5 тыс. руб. при фиктивной переменной X 6 (форма собственности: 0 — государственная, 1 — частная) статистически значим на уровне значимости a=0,05. Это свидетельствует о существенной разнице в размере годовой прибыли государственных и частных компаний. В среднем годовая прибыль у частных компаний при прочих равных условиях на 227,5 тыс. руб. больше, чем у государственных. Средний коэффициент эластичности для фиктивной переменной лишен смысла, поэтому и не рассчитывается.
Сравним между собой силу влияния включенных в модель факторов на годовую прибыль, для чего определим их бета–коэффициенты:
 ;
;
 ;
;
 ;
;
 .
.
Сравнивая их по абсолютной величине, можно сделать вывод, что на изменение годовой прибыли Y сильнее всего влияет изменение годового размера страховых премий Х 3, далее по степени влияния следуют годовой размер страховых выплат Х 4, форма собственности X 6 и размер страховых резервов X 2.
Определим квадраты бета-коэффициентов:
 ;
;
 ;
;
 ;
;
 .
.
Они показывают, что чистая вариация только годового размера страховых резервов X 2 объясняет 3,8 % вариации годовой прибыли Y, чистая вариация годового размера страховых премий Х 3 — 39,7 % вариации Y, а чистая вариация годового размера страховых выплат Х 4 — 24,3 % вариации Y. Форма собственности объясняет 6,9 % вариации годовой прибыли Y.
Определим дельта–коэффициенты факторов:
 ;
;
 ;
;
 ;
;
 ,
,
где  ; ;
; ;  ;
;  — парные коэффициенты корреляции между переменными (см. табл. 3.3).
— парные коэффициенты корреляции между переменными (см. табл. 3.3).
Сумма дельта-коэффициентов факторов, включенных в модель должна быть равна единице. Небольшое неравенство вызвано погрешностями промежуточных округлений. Таким образом, в суммарном влиянии на годовую прибыль Y всех факторов, включенных в модель, доля влияния годового размера страховых резервов X 2 составляет 7,1 %, размера страховых премий Х 3 — 51,2 %, размера страховых выплат Х 4 — 37,5 %, формы собственности Х 6 — 4,1 %.
7. При проведении регрессионного анализа в EXCEL можно получить предсказанные уравнением регрессии значения результата Y, остатки и стандартизированные (стандартные) остатки (табл. 3.8).
| Таблица | 3.8 |
| Вывод остатка |
| Наблюдение | Предсказанное Y | Остатки | Стандартные остатки |
| 1442,3 | -430,3 | -1,969 | |
| 547,6 | -85,6 | -0,392 | |
| 1827,0 | 219,0 | 1,002 | |
| 505,7 | 22,3 | 0,102 | |
| 500,0 | -82,0 | -0,375 | |
| 668,1 | 145,9 | 0,667 | |
| 503,3 | 24,7 | 0,113 | |
| 723,2 | 178,8 | 0,818 | |
| 527,4 | -32,4 | -0,148 | |
| 529,3 | -23,3 | -0,107 | |
| 704,6 | 10,4 | 0,048 | |
| 439,0 | -120,0 | -0,549 | |
| 544,6 | -170,6 | -0,781 | |
| 1060,2 | -334,2 | -1,529 | |
| 929,4 | 104,6 | 0,479 | |
| 773,5 | -289,5 | -1,325 | |
| 1509,3 | 558,7 | 2,556 | |
| 446,0 | 104,0 | 0,476 | |
| 725,8 | -285,8 | -1,308 | |
| 666,5 | 169,5 | 0,776 | |
| 501,7 | 48,3 | 0,221 | |
| 758,5 | 165,5 | 0,757 | |
| 155,9 | 361,1 | 1,652 | |
| 710,3 | -182,3 | -0,834 | |
| 925,4 | -188,4 | -0,862 | |
| 184,5 | 156,5 | 0,716 | |
| 440,9 | -44,9 | -0,206 |
На рис. 3.6 показан график остатков ei от предсказанных уравнением регрессии значений результата 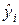 (i =1, 2, …, n), построенный с помощью надстройки «Мастер диаграмма» EXCEL (см. § 5.1).
(i =1, 2, …, n), построенный с помощью надстройки «Мастер диаграмма» EXCEL (см. § 5.1).

рис. 3.6. График остатков
Проверим выполнение предпосылок метода наименьших квадратов.
1) Случайный характер остатков. Проверим исходные данные на наличие аномальных наблюдений годовой прибыли Y (выбросов). С этой целю сравним абсолютные величиныстандартных остатковс табличным значением t -критерия Стьюдента для уровня значимости a=0,05 и числа степеней свободы остатка регрессии  , которое составляет t таб=2,074.
, которое составляет t таб=2,074.
Видно, что только стандартный остаток, соответствующий наблюдению 17 (компания «С») превышает по абсолютной величинетабличное значение t ‑критерия. Вполне возможно, что это наблюдение является выбросом, и следовало бы попробовать построить модель регрессии без этого наблюдения.
Визуальный анализ графика остатков не выявляет в них какой-либо явной закономерности.
2) Нулевая средняя величина остатков. Данная предпосылка всегда выполняется для линейных моделей со свободным коэффициентом b0, параметры которых оцениваются обычным методом наименьших квадратов.
3) Одинаковая дисперсия (гомоскедастичность) остатков. Выполнение данной предпосылки проверим методом Глейзера в предположении линейной зависимости среднего квадратического отклонения возмущений s(e i) от предсказанных уравнением регрессии значений результата (i =1, 2, …, n). Для этого рассчитаем коэффициент корреляции  между абсолютными величинами остатков
между абсолютными величинами остатков  и значениями (i =1, 2, …, n) с помощью выражения, составленного из встроенных функций:
и значениями (i =1, 2, …, n) с помощью выражения, составленного из встроенных функций:
=КОРРЕЛ(ABS(Остатки); Предсказанное_Y)
Этот коэффициент корреляции оказался равным  .
.
Критическое значение коэффициента корреляции для уровня значимости a=0,05 и числа степеней свободы  составляет r кр=0,381. Видно, что коэффициент корреляции превышает по абсолютной величине критическое значение, и статистическая гипотеза об одинаковой дисперсии остатков отклоняется на уровне значимости a=0,05. Положительное значение коэффициента корреляции указывает на то, что годовая прибыль более крупных компаний имеет существенно б о льшую вариацию.
составляет r кр=0,381. Видно, что коэффициент корреляции превышает по абсолютной величине критическое значение, и статистическая гипотеза об одинаковой дисперсии остатков отклоняется на уровне значимости a=0,05. Положительное значение коэффициента корреляции указывает на то, что годовая прибыль более крупных компаний имеет существенно б о льшую вариацию.
Невыполнение предпосылки об одинаковой дисперсии остатков свидетельствует о том, что данная модель не вполне адекватна, а оценки параметров модели обычным методом наименьших квадратов могут не быть эффективными. Вполне возможно, что если из исходных данных удалить наблюдение 17, которое, как указывалось выше, может быть выбросом, то предпосылка будет выполнена (попробуйте проверить это самостоятельно).=).
4) Отсутствие автокорреляции остатков. Выполнение данной предпосылки проверим методом Дарбина–Уотсона. Предварительно ряд остатков на рабочем листе EXCEL упорядочивается в зависимости от последовательно возрастающих значений Y, предсказанных уравнением регрессии. Для этой цели в «Выводе остатка» выделяется любая ячейка в столбце «Предсказанное Y», и на панели инструментов нажимается кнопка «Сортировка по возрастанию».
Для расчета d ‑статистики используется выражение, составленное из встроенных функций «СУММКВРАЗН» и «СУММКВ»:
= СУММКВРАЗН («Остатки 2, …, n»;«Остатки 1, …, n –1»)/СУММКВ(«Остатки 1, …, n»)
В результате получим d =2,01. Критические границы d ‑статистики для числа наблюдений n =27, числа факторов p =4 и уровня значимости a=0,05 составляют: d 1=1,08; d 2=1,76. Так как выполняется условие
 ,
,
статистическая гипотеза об отсутствии автокорреляции в остатках не отклоняется на уровне значимости a=0,05.
Проверим отсутствие автокорреляции в остатках также и по коэффициенту автокорреляции остатков первого порядка, для расчета которого в EXCEL может использоваться следующее выражение:
= СУММПРОИЗВ («Остатки 2,…, n»;«Остатки 1,…, n –1»)/СУММКВ(«Остатки 1, …, n»)
Ряд остатков упорядочен в той же самой последовательности, что и при расчете d ‑статистики. Коэффициент автокорреляции остатков первого порядка равен r (1)=–0,078. Критическое значение коэффициента автокорреляции для числа наблюдений n =27 и уровня значимости a=0,05 составляет r (1)кр=0,381. Так как r (1) не превышает по абсолютной величине критическое значение, то это еще раз указывает на отсутствие автокорреляции в остатках.
5) Нормальный закон распределения остатков. Выполнение этой предпосылки проверяем с помощью R / S -критерия
 ,
,
где e max=558,7 тыс. руб.; e min=–430,3 тыс. руб. — наибольший и наименьший остатки соответственно (определялись с помощью встроенных функций «МАКС» и «МИН»); Se =218,5 тыс. руб. — стандартное отклонение ряда остатков (определено с помощью встроенной функции «СТАНДОТКЛОН»).
Критические границы R/S -критерия для числа наблюдений n =27 и уровня значимости a=0,05 имеют значения: (R / S)1=3,34 и (R / S)2=4,71. Так как R / S ‑критерий попадает в интервал между критическими границами, то это означает, что статистическая гипотеза о нормальном законе распределения остатков не отклоняется на уровне значимости a=0,05.
Таким образом, выполняются четыре из пяти предпосылок обычного метода наименьших квадратов. Это говорит о том, что регрессионная модель не вполне адекватна исследуемому экономическому явлению, и использовать ее для целей анализа и прогнозирования годовой прибыли страховой компании следует с некоторой долей осторожности.
8. Рассчитаем прогнозное значение годовой прибыли, если прогнозные значения факторов составят 75 % от своих максимальных значений в исходных данных. Максимальные значения определяем с помощью встроенной функции EXCEL «МАКС». Прогнозные значения рассчитываем только для количественных факторов X 2, X 3, X 4:
· фактор Х 2:  тыс. руб.;
тыс. руб.;
· фактор Х 3:  тыс. руб.;
тыс. руб.;
· фактор Х 4:  тыс. руб.
тыс. руб.
Среднее прогнозируемое значение годовой прибыли государственных компаний (x 06=0) равно:

Для частных компаний (x 06=1) этот показатель равен

9. Построим доверительный интервал прогноза фактического значения годовой прибылиc надежностью 80 %.
Стандартная ошибка прогноза фактического значения годовой прибыли y 0 для определенных в предыдущем пункте прогнозных значений факторов рассчитывается по формуле
 .
.
Так как фиктивная переменная Х 6 может принимать два значения — 0 или 1, то  определим для обоих случаев:
определим для обоих случаев:
– для государственных компаний (x 06=0):

– для частных компаний (x 06=1):
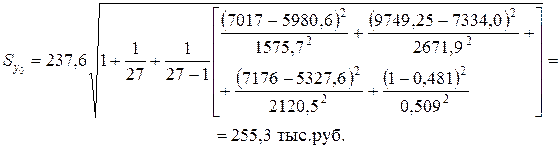
Построим доверительные интервалы прогноза фактического значения результата y 0 с доверительной вероятностью g=0,8 (уровень значимости a=0,2):
 ,
,
где t таб — табличное значение t -критерия Стьюдента при уровне значимости a=0,2 и числе степеней свободы составляет t таб=1,321.
Интервальный прогноз для государственных компаний имеет вид:
 тыс. руб.
тыс. руб.
Таким образом, с вероятностью 80 % годовая прибыль государственных компаний будет находиться в интервале от 272,4 до 945,4 тыс. руб.
Для частных компаний интервальный прогноз:
 тыс. руб.
тыс. руб.
С вероятностью 80 % годовая прибыль частных компаний будет находиться в интервале от 499,1 до 1173,7 тыс. руб.
Пример 3.2
Исследуется зависимость доходности акций компании (зависимая переменная Y, %) от доходности рынка (фактор X 1, %). Имеются данные за пятнадцать кварталов:

