




Сначала для простоты и возможности геометрического изображения основных положений регрессионного анализа предположим, что у нас всего две переменные: Х и Y (соответственно, независимая и зависимая). С помощью рассматриваемого подхода осуществляется поиск зависимости вида Y = f(X). Однако это выражение для результата регрессионного анализа носит условный характер: искомая зависимость не функциональна, а статистична, является закономерностью “в среднем”, она “неточна”. Поясним, в чем именно состоят такие усредненность и “неточность”.

Рис. 22. Принципиальная схема линии регрессии.
В качестве независимой переменной фигурируют условные средние значения Y (каждое такое среднее вычисляется для конкретного значения независимой переменной Х; соответствующая точка на графике обозначена крестиком)
Прежде всего обратим внимание читателя на то, что для социологических данных типична ситуация, когда одному значению Х соответствует множество значений Y. Эта ситуация схематично изображена на рис. 22 (пока обращаем внимание только на черные кружки).
Встает вопрос: какую именно зависимость мы хотим вычислить? Как искомая кривая (а мы хотим, чтобы каждому значению независимой переменной отвечало одно значение зависимой, т.е. чтобы искомой связи отвечала какая-то одномерная линия) должна “пробиваться” через изображенное на рисунке облако точек?
Ответ представляется естественным: подсчитаем для каждого значения Х среднее арифметическое значение всех отвечающих ему значений Y и будем изучать зависимость от Х именно таких средних. Соответствующие точки на нашем рисунке обозначены крестиками. Для них вид искомой зависимости четко “просматривается”. Другими словами, интересующая нас статистическая зависимость будет иметь вид:
 (8)
(8)
Вспомним, что на рис. 22 отражена выборочная ситуация, в то время как в действительности нас интересует то, что делается в генеральной. Рассмотрение последней предполагает, что переменные непрерывны, имеют бесконечное число значений. Соотношение (8) для генеральной совокупности превращается в следующее:
 , (9)
, (9)
(где m – знак математического ожидания – меры средней тенденции для генеральной совокупности; напомним, что среднее арифметическое, является лишь "хорошей" выборочной оценкой математического ожидания). Такая функция называется функцией регрессии Y по Х (иногда говорят об уравнении регрессии, либо о регрессионной зависимости). Ее график называется линией регрессии. Подчеркнем, что соотношение (9) предполагает, что при каждом фиксированном значении Х значения Y суть значения некоторой случайной величины. Это означает следующее.
Фиксируя какое-либо значение Х, равное, например, Хi (т.е. рассматривая совокупность объектов, обладающих этим значением), мы имеем дело с некоторым условным распределением Y (которое образуют значения зависимой переменной Y, вычисленные для объектов, обладающих значением Хi признака Х). Это распределение имеет свое математическое ожидание и дисперсию. Именно это математическое ожидание фигурирует в левой части равенства (9). Это математическое ожидание лежит на линии регрессии (рис. 23).

Рис. 23. Статистические предположения, лежащие в основе регрессионного анализа. Условные распределения зависимой переменной Y нормальны. Их математические ожидания m1, m2, m3 лежат на линии регрессии; дисперсии  ,
,  ,
, 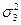 равны.
равны.
m1, m2, m3 – математические ожидания тех условных распределений переменной Y, которые получаются при фиксации, соответственно, значений Х1, Х2, Х3 переменной Х. Ясно, что с помощью линии регрессии хорошо можно осуществлять тот прогноз, который является основной целью поиска зависимости Y от X: эта линия говорит о том, насколько изменится среднее значение Y при том или ином изменении значения Х. Будем говорить в таком случае об изменении Y в среднем.
Точность, с которой линия регрессии Y по Х передает изменение Y в среднем при изменении Х, измеряется дисперсией величины Y, вычисленной для каждого значения Х:
D (Y/X) = s2 (X)
Пусть  ,
,  ,
,  – значения дисперсий, вычисленных для условных распределений переменной Y, получающихся при фиксации, соответственно, значений Х1, Х2, Х3 переменной Х.
– значения дисперсий, вычисленных для условных распределений переменной Y, получающихся при фиксации, соответственно, значений Х1, Х2, Х3 переменной Х.
Обычно предполагается, что описанные условные распределения зависимой переменной Y нормальны, а дисперсии этих распределений равны: = = =  . Именно такая ситуация отражена на рис. 23. При равенстве дисперсий говорят, что условные распределения удовлетворяют свойству гомоскедастичности. Попытаемся коротко пояснить смысл этого свойства.
. Именно такая ситуация отражена на рис. 23. При равенстве дисперсий говорят, что условные распределения удовлетворяют свойству гомоскедастичности. Попытаемся коротко пояснить смысл этого свойства.
Ясно, что чем меньше условные дисперсии Y, т.е. чем меньше разброс зависимого признака в условных распределениях, тем больше можно верить прогнозу значений этого признака, осуществляемому с помощью уравнения регрессии. Напротив, большой разброс может полностью лишить нас возможности делать прогноз: утверждение о том, что для такого-то Хi переменная Y в среднем равна соответствующему условному среднему, не будет иметь никакой практической ценности из-за того, что бессмысленным станет сам расчет средней величины (в п. 1.2 мы говорили о том, что для осмысленности средней требуется однородность изучаемой совокупности объектов, отсутствие большого разброса по рассматриваемому признаку). Можно говорить о качестве найденной регрессионной зависимости, связывая его именно с описанной возможностью прогноза. Тогда при условных дисперсиях, равных одной и той же величине s, это качество может быть строго определено: при большой s оно будет плохим, при малой – хорошим. А если разбросы при разных Х разные? Тогда для одних значений Х уравнение регрессии будет хорошим, при других – плохим. Представляется, что при практическом использовании такого уравнения могут возникнуть неприятности. Отсюда – требование гомоскедастичности.
Теперь обсудим вопрос о том, как найти конкретный вид функции регрессии f. На помощь приходит то, что линия регрессии обладает замечательным свойством: среди всех действительных функций f минимум математического ожидания m(Y–f(X))2 достигается для функции f (X) = m(Y/X). Поясним смысл этого утверждения, обратившись к выборочной ситуации, представленной на рис. 24.

Рис. 24. Отклонения ординат рассматриваемых точек от произвольной функции
Рассмотрим заданную совокупность точек – моделей изучаемых объектов и произвольную функцию f (X). Вертикальные отрезки – отклонения ординат рассматриваемых точек от этой графика этой функции. Средняя величина квадратов длин этих отрезков – это и есть выборочная оценка математического ожидания m(Y–f(X))2.
Для того, чтобы лучше понять способ вычисления величин рассмотренных отрезков, покажем, в чем он состоит, на примере одной точки, имеющей произвольные координаты (Х, Y) в нашем признаковом пространстве. Обратимся к рис. 25.
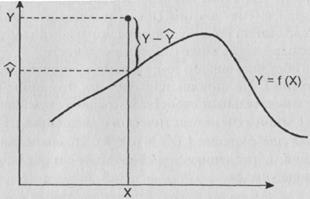
Рис.25. Способ определения отклонения точки (Х, Y) от произвольной функции Y = f (X)
Х координата рассматриваемого объекта (на рисунке он обозначен точкой) по оси Х; Y – его же координата по оси Y;Y - ордината точки, принадлежащей графику функции Y = f(X) и имеющей по оси Х ту же координату, что и наш объект.
Сумма  (суммирование осуществляется по всем рассматриваемым объектам) и есть та величина, которую надо минимизировать для того, чтобы получить выборочное представление линии регрессии. Символически процесс такой минимизации можно выразить следующим образом:
(суммирование осуществляется по всем рассматриваемым объектам) и есть та величина, которую надо минимизировать для того, чтобы получить выборочное представление линии регрессии. Символически процесс такой минимизации можно выразить следующим образом:
 (10)
(10)

 – это как бы теоретическое, модельное значение зависимой переменной. Это то значение, которое мы имели бы, если бы после всех расчетов пользовались найденной функцией Y = f (X) как основой для прогноза.
– это как бы теоретическое, модельное значение зависимой переменной. Это то значение, которое мы имели бы, если бы после всех расчетов пользовались найденной функцией Y = f (X) как основой для прогноза.
В соответствии со сформулированным выше свойством линии регрессии, можно сказать, что минимальной эта сумма будет в том случае, если рассматриваемая функция Y = f(X) является выборочным представлением искомой линии регрессии. Другими словами, указанному выборочному представлению отвечает та функция f(X), для которой указанная выше сумма минимальна.
Итак, чтобы найти выборочную линию регрессии, необходимо как бы “перебрать” все возможные функции Y = f(X), для каждой вычислить указанную сумму квадратов и остановиться на той функции, для которой эта сумма минимальна.
Рассматриваемый способ поиска f(X), носит название метода наименьших квадратов (отметим, что этот метод очень часто используется при расчете самых разных статистических закономерностей. Так, он задействован в одном из известных методов шкалирования - методе парных сравнений [Толстова, 1998]).
Чтобы смысл метода наименьших квадратов стал яснее, заметим, что чем меньше величина указанной выше суммы квадратов, тем с большим основанием рассматриваемую функцию можно считать близкой одновременно ко всем рассматриваемым точкам. Эта функция в каком-то смысле служит моделью всего "облака" точек. Это можно проиллюстрировать с помощью рисунка 26.

Рис. 26. Иллюстрация проблемы выбора прямой линии, наилучшим образом отвечающей линии регрессии
Ясно, что прямая "аа" заведомо не может минимизировать рассматриваемую сумму: она совсем не отражает наше облако точек. А вот относительно прямых "bb” и "сс" вряд ли “на глаз” можно определить, какая из них лучше. Чтобы ответить на этот вопрос, необходимо использовать метод наименьших квадратов.
Очевидно, перебрать все мыслимые функции невозможно. Встает вопрос, как определить f(Х).
Математика предоставляет нам возможность найти функцию, отражающую искомую линию регрессии с любой степенью приближения. Это можно сделать, например, используя многочлены произвольной степени m:

(b0, b1, b2, …, bm – некоторые параметры; выборочные оценки которых надо получить). Однако найденная функция, вообще говоря, будет очень сложной и вряд ли с ее помощью мы сможем практически осуществлять прогноз, т.е. достигнем основной цели построения регрессионных моделей. Причины такой непригодности сложных формул частично сходны с теми, что были обсуждены нами в п. 2.5.3.2 при рассмотрении третьей причины останова алгоритма THAID: слишком сложные формулы мы в силу своей психологической специфики не можем воспринимать как закономерность (п.1.4 части I).
Чтобы избежать чрезмерной сложности искомой закономерности, обычно выбирают какое-либо семейство кривых, выражающихся сравнительно простыми формулами, и именно среди них с помощью метода наименьших квадратов ищут ту, которая как можно более близко подходит ко всем данным точкам. Чаще всего в качестве такого семейства используют совокупность прямых линий. Как известно, все такие линии выражаются формулами вида

где b1 a говорит о величине угла наклона прямой к оси Х, а b0 - о сдвиге этой прямой вдоль оси Y. Соответствующий вариант регрессионного анализа называется линейным. Он чаще всего используется практически. Отвечающая ему техника хорошо известна. Выборочные оценки коэффициентов линейного уравнения регрессии находятся с помощью описанного выше метода наименьших квадратов.
В данном случае (10) превращается в соотношение

Далее мы, условно говоря, как бы “перебираем” все возможные прямые (точнее, все возможные пары чисел b0 и b1) и находим ту прямую, для которой наша сумма будет самой маленькой. Конечно, в действительности перебрать все прямые также невозможно (как известно, совокупность всех действительных чисел нельзя даже “пересчитать” с помощью бесконечного ряда натуральных чисел), параметры искомой прямой ищутся с помощью производных: находим производную от нашей суммы по b0 и b1 и ищем те их значения, которые обращают производную в нуль. Получаем известные аналитические выражения для этих коэффициентов (напомним, что латинскими буквами обозначаются выборочные оценки одноименных генеральных параметров):

где r – коэффициент корреляции между Х и Y; SY и SX – выборочные оценки средних квадратических отклонений соответствующих признаков; суммирование, как и выше, осуществляется по всем объектам.
В идеале точка с координатами (Х, b0 + b1X) должна лежать на линии регрессии. В соответствии с упомянутыми выше традиционными предположениями, это означает справедливость картины, отраженной на рис. 27.

Рис. 27. Статистические предположения, лежащие в основе линейного регрессионного анализа.
Условные распределения Y нормальны. Их математические ожидания лежат на прямой линии, дисперсии равны.
Другими словами, мы предполагаем, что каждому значению независимой переменной Х отвечают нормальные гомоскедастичные условные распределения Y, математические ожидания которых принадлежат рассматриваемой прямой. Это предположение эквивалентно следующему соотношению:
Yi = b0 + b1Xi + еi,
означающему, что каждое наблюдаемое значение Yi есть сумма некой фиксированной величины b0 + b1X, обусловленной линией регрессии, и случайной величины еi, обусловленной естественной вариацией значений Y вокруг линии регрессии. При каждом значении независимой переменной Х вариация Y имеет тот же характер, что и вариация еi. Отсюда ясно, что все еi имеют нормальные распределения с нулевыми математическими ожиданиями и равными дисперсиями s2. Важность случайных величин еi заключается в том, что она представляет собой главный источник ошибок при попытке предсказать Y по значению Х. В рамках регрессионного анализа разработаны способы оценки величин еi.
На практике чаще всего пользуются именно линейными регрессионными моделями. Однако при их использовании необходимо учитывать, что идеальная картина, изображенная на рис. 27 – это лишь наше пожелание. Наилучшая прямая среди всех возможных прямых может быть весьма плохим приближением к реальности. Скажем, если наши крестики расположены так, как это отражено на рис. 28, то любая прямая (например, "аа") здесь даст очень плохое приближение.
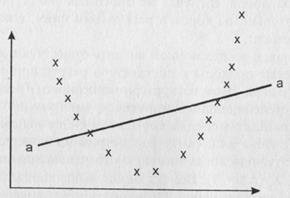
Рис. 28. Пример криволинейной линии регрессии между двумя переменными. Несоответствие ей прямой "аа"
В данном случае надо бы вместо прямых линий использовать для поиска подходящих кривых семейство квадратных трехчленов вида
Y = b0 + b1X + b2X2.
Используя же технику линейного регрессионного анализа, и тем самым направляя свою энергию на поиск лучшей прямой, приближающей нашу совокупность точек, мы рискуем никогда не узнать, что в действительности имели дело с линией регрессии, являющейся параболой. Правда, тут необходимо отметить два момента.
Во-первых, для двумерного случая, который мы пока рассматриваем, такое вряд ли случится, поскольку перед нами – наглядная плоскостная картина, глядя на которую всегда можно определить, прямая ли линия соответствует изучаемому множеству точек, или парабола. В случае же многомерного регрессионного анализа, который мы коротко рассмотрим ниже, такой просчет вполне возможен.
Во-вторых, в регрессионном анализе существуют достаточно разработанные подходы к построению регрессионных кривых нелинейного вида. Имеются критерии линейности и рекомендации по выбору степени аппроксимирующего многочлена.
О нелинейных моделях коротко мы еще вспомним ниже (см. п. 2.6.5). Пока же коротко рассмотрим многомерный случай, т.е. такую ситуацию, когда имеется много независимых переменных Х1, Х2,..., Хn (n > 1). Все сказанное выше справедливо и для рассматриваемой ситуации. Отличие состоит только в том, что здесь линейная регрессионная модель имеет вид не прямой линии, а так называемой гиперплоскости:
Y = а0 + а1´Х1+ а2´Х2 +... + аn´Хn
Здесь необходимо два слова сказать об интерпретации только что выписанного уравнения (в соответствии с общепринятой терминологией, слева пишется просто Y, а не условное среднее  и найденное с помощью техники регрессионного анализа соотношение называется уравнением, хотя этот термин и употребляется не в том смысле, в каком его используют в школе; а0 называется свободным членом уравнения). Однако прежде сделаем некоторые замечания о единицах измерения рассматриваемых признаков. Интуитивно ясно, что уравнение регрессии будет более ясным с точки зрения его содержательной интерпретации, если все эти единицы будут одинаковыми. Для этого обычно осуществляют так называемую стандартизацию всех значений каждого признака: вычитают из каждого такого значения среднее арифметическое признака (точнее, здесь речь должна идти о математическом ожидании, за неимением которого мы используем его выборочную оценку – среднее арифметическое) и делят полученную разность на его же дисперсию (и снова вместо генеральной дисперсии мы вынуждены пользоваться ее выборочной оценкой). Рассмотрим для примера признак Х2.. Если
и найденное с помощью техники регрессионного анализа соотношение называется уравнением, хотя этот термин и употребляется не в том смысле, в каком его используют в школе; а0 называется свободным членом уравнения). Однако прежде сделаем некоторые замечания о единицах измерения рассматриваемых признаков. Интуитивно ясно, что уравнение регрессии будет более ясным с точки зрения его содержательной интерпретации, если все эти единицы будут одинаковыми. Для этого обычно осуществляют так называемую стандартизацию всех значений каждого признака: вычитают из каждого такого значения среднее арифметическое признака (точнее, здесь речь должна идти о математическом ожидании, за неимением которого мы используем его выборочную оценку – среднее арифметическое) и делят полученную разность на его же дисперсию (и снова вместо генеральной дисперсии мы вынуждены пользоваться ее выборочной оценкой). Рассмотрим для примера признак Х2.. Если  – некоторое (i-е) его значение,
– некоторое (i-е) его значение,  и sХ – соответственно, отвечающие ему среднее арифметическое и дисперсия, то указанная нормировка будет означать следующее преобразование значения :
и sХ – соответственно, отвечающие ему среднее арифметическое и дисперсия, то указанная нормировка будет означать следующее преобразование значения :

Нетрудно видеть, что среднее значение нормированного признака будут равно нулю, а дисперсия – единице. Далее будем считать, что описанная нормировка для всех рассматриваемых признаков произведена и что тем самым снята проблема несравнимости их значений из-за “разномасштабности”. Обозначения признаков оставим прежними.
Интерпретация коэффициентов очевидна. Если, скажем, значение признака Х2 изменится на единицу, то значение Y изменится на а2. Поэтому а2 можно интерпретировать как величину приращения Y, получаемого за счет увеличения признака Х2 на единицу.
В заключение обсуждения вопроса о классическом регрессионном анализе заметим, что указанная “прозрачная” интерпретация может “затуманиться” в том случае, если наши предикторы связаны друг с другом. Причина тоже довольно очевидна. Поясним это.
Предположим, что Х2 связан с Х5 и мы хотим узнать, на сколько изменится Y при увеличении Х2 на единицу. Рассуждать так же, как выше, мы не можем: увеличение Х2 неумолимо приведет к увеличению (или уменьшению) Х5, и поэтому изменение Y будет обусловлено изменением не только Х2, но и Х5. На сколько изменится Х5, вообще говоря, неизвестно. Чтобы ответить на этот вопрос, нужно подробнее изучить форму зависимости между Х2 и Х5. А это - самостоятельная и, возможно, сложная задача. Без ее решения вопрос о величине изменения Y остается открытым. И в любом случае это изменение, вообще говоря, не будет равно а2.
В силу сказанного, будем стремиться к тому, чтобы избегать включения в уравнение регрессии заведомо связанных друг с другом предикторов.
Описание идей регрессионного анализа можно найти в [Мостеллер, Тьюки, 1982; Паниотто, Максименко, 1982; Статистические методы …, 1979].
Теперь перейдем к рассмотрению вопроса о возможности использования техники линейного регрессионного анализа к номинальным данным.

