




Итак, представим себе типичную для социолога ситуацию: он осуществил опрос и перед ним лежит тысяча (может быть, не одна) анкет с ответами респондентов. Каждый ответивший характеризуется набором чисел – ответов, или, как обычно говорят, значений рассматриваемых признаков (признак соответствует вопросу).
Продолжая приведенные выше рассуждения, позволившие выразить интересующие социолога статистические закономерности (или, что для нас то же самое – результаты, получаемые с помощью известных методов анализа номинальных данных) в терминах исчисления высказываний, нетрудно придти к выводу, что более общие закономерности, в неменьшей мере важные для социолога, часто бывает возможно выразить в языке узкого исчисления предикатов. Эти закономерности означают истинность определённых формул в этом исчислении.
Приведем примеры упомянутых формул. Пусть, например, предикат (предикатная константа) P(x) означает “респондент x отметил 5-е значение 8-го признака”, предикат Q (y) - “респондент y отметил 3-е значение 14-го признака”, а предикат R(z) - “респондент z отметил 1-е значение 2-го признака. Тогда приведённое выше утверждение “ 5-е значение 8-го признака, как правило, встречается либо с 3-м значением 14-го, либо с 1-м значением 2-го” будет означать, что почти для всех x будет истинной формула (P(x) & (Q(x)Ú R(x))).
Теперь предположим, что P(x) означает “респонденту x отвечает 2-е значение 3-го признака”, Q(x) – “ респонденту отвечает 5-е значение 4-го признака, R(x) – предикат “значение 6-го признака для респондента x равно или 2, или 3”. Тогда выражение “из того, что 3-й признак принимает 2-е значение одновременно с тем, что 4-й принимает 5-е значение, как правило, следует, что 6-й признак принимает либо 2-е, либо 3-е”,” и т.д. означает, что почти для всех x будет истинно выражение ((P(x) & Q(x))É R(x)).
Пусть S(x) – “значение 23-го признака для респондента x равно 2”, T(x) – “значение 7-го признака для респондента x равно 4”. Тогда утверждение “из того, что 23-й признак принимает какое-либо значение, кроме 2-го, следует, что 7-й признак принимает 4-е значение” будет эквивалентно утверждению истинности формулы (Ø(S(x)) É T(x)).
Нетрудно видеть, что таким образом в виде формул узкого исчисления предикатов действительно можно выразить очень многие интересующие социолога “закономерности”, “скрывающиеся” в эмпирических данных. А если учесть, что большинство методов анализа номинальных данных, как было показано в предыдущих параграфах, позволяет выявлять “закономерности” именно такого вида, то можно сказать, что практически все интересующие социолога закономерности выражаются на языке формул исчисления предикатов первого порядка.
Итак, наиболее типичной задачей, решающейся на основе анализа такого рода данных можно считать следующую: найти логическую функцию от значений признаков (выступающих в качестве предикатов), истинную для изучаемой совокупности респондентов. Получаемые выводы (найденные закономерности) могут иметь, например, такой вид (используем обычную логическую символику, логические связки соединяют записанные в неформальном виде значения рассматриваемых предикатов-признаков): "(((Проживающий в крупном городе) & (мужчина-предприниматель) & (старше 40 лет)) Ú ((пенсионер) & (имеющий высшее экономическое образование))) É (собирается голосовать на ближайших выборах за кандидата N)".
Очевидно сходство такой постановки задачи с тем, что было обсуждено выше в п.п. 2.4.2, 2.5.3 и 2.5.4.
Теория измерений позволяет существенно повысить эффективность решения задачи поиска закономерностей описанного вида. Суть соответствующего подхода заключается в том, что упомянутые логические функции считаются аксиомами, задающими изучаемую ЭС (ей отвечает МС – фрагмент многомерного пространства). Разработаны способы внесения в определение и ЭС, и МС вероятностных характеристик. Предложены алгоритмы поиска таких аксиом. Рассмотрим соответствующий процесс более подробно.
Вид искомых аксиом
Возможность экспериментального выявления аксиом, описывающих нашу ЭС, обеспечивается тем, что необозримая совокупность всех возможных формул, подлежащих проверке, сводится к множеству, вполне поддающемуся обзору множеству (формулы этого множества служат гипотезами для проверки на ЭС). А именно, на основе положений математической логики доказываются следующие утверждения.
Совокупность формул интересующего нас характера может быть сведена к совокупности формул вида
С= (А1& А2& … & Ак É А0), (7)
где Аi – или наши предикатные константы с произвольными предметными переменными, или их отрицания. Назовем формулы вида (7) правилами.
Введем также понятие подправила правила (7) как такой формулы, которая является импликацией, содержащей в качестве посылки – часть посылки формулы вида (1) (получающуюся за счет отбрасывания некоторых Аi ), а в качестве заключения – либо то же заключение, что и в (7) (т.е. А0), либо отрицание одной из тех Аi, (i = 1, …, k), которые не вошли в посылку. Ясно, что каждое подправило правила (7) является в то же время неким правилом того же вида (7).
Из логики и методологии науки известно, что законами можно считать те из гипотез, которые при одинаковой их подтвержденности на экспериментальных данных наиболее фальсифицируемы, просты и/или содержат наименьшее число параметров (ср. наше обсуждение понятия закономерности в п. 2.5.3).
Ясно, что подправило – логически более сильное утверждение, чем само правило. Другими словами, из истинности подправила следует истинность правила. К примеру, рассмотрим правило “из конъюнкции "быть мужчиной и жить на селе" следует "быть курящим"” и два его подправила: (а) “из свойства "быть мужчиной" следует "быть курящим"“ и (б) “из свойства "быть мужчиной" следует "не жить на селе"“. То, что первое подправило логически более сильно, чем правило, представляется очевидным: если из свойства "быть мужчиной" следует свойство "быть курящим", то последнее следует также и из конъюнкции свойств "быть мужчиной и жить на селе". Относительно же второго подправила можно заметить, что если оно истинно, то, очевидно, конъюнкция "быть мужчиной и жить на селе" ложна. Значит, наше правило истинно в силу ложности его посылки (напомним, что, в соответствии с правилами формальной логики, из лжи следует что угодно).
Кроме того, любое подправило является и более фальсифицируемым, чем правило, так как содержит более слабую посылку и, следовательно, применимо к большему объему данных и тем самым в большей степени подвержено фальсификации; и более простым, так как содержит меньшее число атомарных высказываний, чем правило; и включает меньшее число "параметров", так как лишние атомарные высказывания также можно считать параметрами "подстройки" высказывания под данные.
Обычно используемое в рамках теории измерений обоснование нефальсифицируемости какого-либо положения не предполагает поиска более простого, логически более сильного и также нефальсифицируемого утверждения. Поэтому нефальсифицируемое на имеющихся данных утверждение принимается в качестве аксиомы даже в том случае, если оно содержит некоторые дополнительные условия, которые без ущерба для нефальсифицируемости можно было бы удалить из него (скажем, мы считаем аксиомой положение "мужчины – селяне курят", если оно истинно на всех объектах изучаемой выборки, и делаем это даже тогда, когда истинным является также логически более сильное положение "мужчины курят", т.е. когда свойство "быть жителем села" – явно лишнее в аксиоме). Авторы цитируемой работы предлагают осуществлять такое удаление.
Сформулированные выше положения дают основания считать, что задача обнаружения законов в данных (законов, характеризующих изучаемую ЭСО) требует нахождения среди всех правил вида (7) логически наиболее сильных. Будем называть законом ЭС любое истинное на этой системе правило вида (7), для которого каждое его подправило уже не истинно на той же системе. Наша главная задача состоит в поиске таких законов, т.е. в поиске наиболее сильной теории, вытекающей из соотношений вида (7) и описывающей эти данные.
Задача вполне решаема, что подтверждается тем, что описанный подход реализован на ЭВМ [Витяев, 1992; Витяев, Москвитин, 1985, 1993]. На этом мы закончим в основном изложение базирующихся на идеях РТИ принципов поиска логических закономерностей, характеризующих изучаемую ЭС. Сделаем лишь несколько небольших замечаний о том, чего мы пока не коснулись.
Заметим, что поиск законов может также способствовать проверке истинности на ЭС любой заранее данной системы аксиом: аксиома будет выполнена на ЭС, если найдется такое ее подправило, которое является законом. Последнее утверждение опирается на то, что, как доказано в цитируемой работе, истинность правила вида (7) возможна только в силу истинности некоторого его подправила либо первого, либо второго определенного нами вида (см. определение подправила). При этом истинность подправила второго вида имеет место в том случае, когда посылка формулы (7) ложна (напомним, что ложность посылки импликации означает истинность последней).
В рассматриваемой работе предлагается также определение вероятностного закона на изучаемой ЭС. Понятие истинности закономерности при этом заменяется на некоторую оценку ее предсказания, вероятности (что представляется целесообразным в свете описанной в первой части настоящей работы статистичности интересующих социолога законов). Рассматривается также проблема т.н. шумов – искажениями искомых законов, вызванных разными случайными причинами.
2.6. Анализ связей типа "признак - группа признаков": номинальный регрессионный анализ (НРА)
Общая постановка задачи
Вспомним некоторые рассуждения, использованные нами выше (п.2.2) в процессе осмысления предложенной классификации методов изучения связей между номинальными переменными. Мы подчеркивали, что в большинстве реальных задач исследователь не должен следовать ставшему традиционным ограничению круга используемых математических методов только известными коэффициентами парной связи. При этом описывалось две совокупности факторов, обусловливающих необходимость перехода к другим методам (см. рис. 20).
Во-первых, имеет смысл "рассыпать" все рассматриваемые признаки на отдельные альтернативы и затем, "склеивая" их разными способами, искать такие сочетания значений исходных признаков, которые определяют те или иные связи, то или иное "поведение" респондентов (анализ фрагментов таблиц сопряженности, алгоритмы последовательных разбиений типа и т.д.).
Во-вторых, имеет смысл объединять отдельные признаки друг с другом, искать такие их сочетания, которые в каком-то смысле детерминируют другие признаки и их сочетания (как мы увидим ниже, в регрессионном анализе речь пойдет о детерминации среднего уровня этих “других” признаков). К соответствующим рассмотрениям мы и перейдем в настоящем параграфе. Проанализируем ту группу методов (или задач, мы говорили о том, что задачи для нас в определенном смысле отождествляются с методами), которая при классификации задач была символически обозначена нами как методы типа "признак-(группа признаков)". Сюда относится регрессионный анализ, к рассмотрению которого мы и переходим.
 |
Рис. 20. Схематичное выражение причин, обусловливающих необходимость перехода от традиционных коэффициентов парной связи к другим методам анализа связей
Сначала для простоты изложения рассмотрим случай, когда у нас имеется только два признака – X и Y - и нас интересует зависимость между ними. Другими словами, сначала предположим, что наша "группа признаков" состоит из одного признака – X (потом перейдем к случаю, когда вместо одного X фигурируют несколько признаков). Мы знаем, что о связи между признаками говорит соответствующий коэффициент корреляции: чем ближе значение модуля этого коэффициента к 1, тем более сильна эта связь, т.е. тем с большей уверенностью мы можем полагать, что с ростом значений одного признака растут (если коэффициент корреляции положителен) или убывают (если коэффициент корреляции отрицателен) значения другого (напомним, что коэффициент корреляции измеряет линейную связь между переменными; отметим, однако, что приводимые рассуждения справедливы и для других коэффициентов связи, например, для корреляционного отношения, дающего возможность оценить криволинейную связь). Но при этом мы совершенно не можем сказать о том, в какой степени возрастет значение Y, если значение X увеличится, скажем, на 1. А ситуации здесь могут быть весьма разными.
Приведем пример, рассмотрев зависимость между производственным стажем человека и его зарплатой. Предположим, что мы имеем дело с двумя крайними ситуациями, отраженными на рисунках 21а и 21б. В обоих случаях соответствующие коэффициенты корреляции близки к 1 (обе совокупности

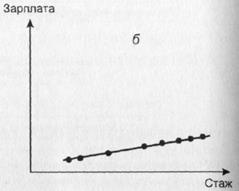
Рис. 21. Примеры сильных линейных связей, определяющих разный прогноз
точек-объектов лежат на прямых линиях, отвечающих нашей зависимости). На первом из них прямая идет резко вверх. Поэтому даже при небольшом увеличении X признак Y резко возрастет. В случае же наличия связи, изображенной на втором рисунке, прямая близка к горизонтали. Поэтому даже при значительном росте X значение Y почти не изменится. Другими словами, на основании наших двух картинок мы получим прогнозы совершенно различного характера. И совершенно ясно, что этого никак нельзя узнать лишь на основе вычисления соответствующих коэффициентов корреляции.
Итак, для того, чтобы делать прогноз о том, как изменится значение Y при том или ином изменении значения X, нам желательно знать, как говорят, форму связи между этими переменными, т.е. желательно найти функцию вида Y = f (X). Подчеркнем, что отношение между X и Y несимметрично: речь идет именно о зависимости второй переменной от первой, именно о возможности прогноза значения Y от X, а не наоборот.
В данном случае для обозначения X и Y используются те же термины, о которых шла речь в начале п. 2.5.3.1. Однако для той ситуации, когда речь идет о нахождении формы зависимости Y от X, употребляется еще несколько пар терминов: независимые переменные называют входными, экзогенными, внешними, а зависимая – выходной, эндогенной, внутренней. Представляется важным правильное понимание причин использования такой терминологии.
Поиск функции f предполагает разработку определенной модели связи между переменными, опирающуюся на априорные знания исследователя (так, ниже мы будем говорить в основном о линейной модели, о линейном регрессионном анализе). Найденная с помощью регрессионной техники зависимость – это тоже некоторая модель реальности - модель, в соответствии с которой и находятся значения Y на основе информации о значениях признака X.
Независимые признаки (X) потому и можно назвать независимыми, что они не зависят от этой модели. Эти признаки как бы поступают на ее “вход”, являются внешними по отношению к ней, берутся “со стороны”. Они определяют конкретный вид искомой зависимости, но не определяются ею. Прогнозируемые же значения зависимой переменной (Y) полностью определяются моделью (то, насколько они близки к реальности, зависит от качества модели), служат ее “выходом”, являются ее порождением. Они внутренне по отношению к ней.
Особенно осторожно надо использовать словосочетания "признак-причина" и "признак-следствие", о чем мы уже говорили в п. 2.1.3.

