




| Тип молодой семьи | Желаемое расселение | Итого | |
| в одном доме | дальше | ||
| Мать с детьми, до 30 лет | |||
| Остальные | |||
| Итого |
Для получения интересующих нас выводов достаточно вспомнить, что сравнительно малые значения упомянутого критерия говорят о том, что мы можем считать пропорциональными столбцы (строки), в том числе маргинальные, наших четырехклеточных таблиц. Таблица (Б) (см. табл. 23) говорит о том, что молодые матери-одиночки примерно в той же мере выбирают те или иные варианты расселения, что и семьи других типов. Другими словами соответствующая специфика семьи не сказывается в том, хочет ли желающая переселиться "молодая" семья (нетрудно видеть, что только такие семьи здесь рассматриваются, поскольку во втором признаке задействованы лишь две категории, относящиеся к ситуации разъезда), после переезда остаться поближе к родителям (в одном доме) или же готова уехать подальше. И среди всех желающих разъехаться чуть более половины хочет остаться в одном доме со старшими (282 из 509), и среди матерей-одиночек до 30 лет (8 из 14).
При анализе таблицы (Д) (см. таблицу 24) становится ясно, что для более старших матерей одиночек – 30-40 лет – указанной выше специфики в желании расселиться нет: семьи этой категории ровно в той же мере хотят разъезда (6 из 36 семей не хотят отделяться от старших), как и семьи других типов (не хотят разъезжаться 37 из 324).
Рекомендуем читателю связать приведенные рассуждения, касающиеся анализа подтаблиц (табл. 21) с анализом соответствующих отношений преобладаний (п.2.3.4).
В заключение параграфа упомянем еще один метод, позволяющий иным путем решать сходные задачи [Ростовцев, 1996, 1998]. Метод предназначен для быстрого обнаружения основных тенденций связи пары переменных. Исходными данными служит совокупность объектов, описанных двумя переменными. В отличие от задачи, рассмотренной выше, здесь предполагается, что используемые шкалы могут быть любыми (в том числе и номинальными). Метод состоит в поиске такой пары дихотомических разбиений совокупностей значений исходных переменных (в результате такого разбиения каждая переменная превращается в дихотомическую), чтобы получающаяся четырехклеточная таблица сопряженности была бы максимально “контрастной”, т.е. отвечала бы как можно более сильной связи между полученными дихотомическими переменными.
Преимущества подхода ясны – в случае использования метода, описанного выше, мы не имеем гарантий того, что нашли именно те четырехклеточные таблицы, которые характеризуют наиболее сильные дихотомические связи. Здесь же метод позволяет сразу найти именно ту четырехклеточную подтаблицу, которая отвечает максимальной зависимости между конструируемыми дихотомическими переменными. Однако есть здесь и свой минус - мы не можем интерпретировать значение соответствующего (“четырехклеточного”) показателя связи как вклад в величину “большого” критерия, характеризующего связь между исходными перменными. Приведем пример из названной работы, демонстрирующий возможности рассматриваемого подхода.
Рассматривается две переменных: профессиональная подготовка и доходы. Каждой переменной отвечает вопрос в анкете с определенным набором ответов (число которых существенно больше двух; мы сознательно не перечисляем конкретные варианты ответа; они носят довольно стандартный характер и их точная формулировка не является приниципиальной для целей нашего изложения). Проверяется гипотеза о том, что люди, имеющие более высокое образование, имеют шанс получать более высокие доходы. Автор решил обосновать свою гипотезу путем оценки связи для четырехклеточной таблицы со значениями признаков: высокий доход – низкий доход, высокая профессиональная подготовка – низкая профессиональная подготовка.
Подчеркнем, что стремление свести изучение связи к анализу частотной таблицы минимального возможного размера – четырехклеточной – не является случайным. Напомним читателю, что, во-первых, выявление любой закономерности связано с потерей информации и, во-вторых, сам термин “закономерность” мы применяем только к сравнительно простым, малоразмерным соотношениям.
В рассматриваемой задаче встает вопрос о том, где граница между высоким и низким доходом, между высокой и низкой профессиональной подготовкой. Чаще всего исследователь определяет эту границу интуитивно. Именно это и попытался сделать сначала автор цитируемой статьи. В качестве границы для душевого дохода он взял его среднее значение для изучаемой совокупности респондентов. Уровни профессиональной подготовки были сгруппированы неким естественным образом, при этом ответ “другое” не учитывался. Для проверки своей гипотезы автор получил следующую частотную таблицу:
Таблица 25.
Четырехклеточная таблица, получающаяся в результате “естественного” деления диапазона изменения каждого признака на две части.
| Душевой доход | Профессиональная подготовка | Итого | |
| Невысокая | Высокая | ||
| Ниже среднего (менее 5300) | 81,3% | 57,1% | |
| Выше среднего (не менее 5300) | 18,7% | 42,9% | |
| Итого |
Проценты означают доли соответствующих совокупностей лиц среди людей с данным уровнем профессиональной подготовки. Нетрудно видеть, что гипотеза подтвердилась: среди лиц с невысоким уровнем профессиональной подготовки 81,3% людей имеют доход ниже среднего, а среди лиц с высоким уровнем образования – аналогичная доля меньше, 57,1% и т.д.
В качестве критерия оценки степени зависимости душевого дохода респондента от уровня его профессиональной подготовки автор предложил использовать различие между эмпирической и теоретической частотами, отвечающими левой верхней клетке получившейся четырехклеточной таблицы сопряженности. В данном случае критерий равен
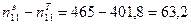
Возник вопрос – нельзя ли подобрать группировку значений переменных, еще ярче подчеркивающую найденную зависимость? И с помощью предложенного в названной статье алгоритма такую группировку удалось найти (табл. 26).
Таблица 26.
Четырехклеточная таблица, получающаяся в результате деления диапазона изменения каждого признака на две части с помощью рассматриваемого алгоритма
| Душевой доход | Профессиональная подготовка | Итого | |
| Невысокая | Высокая | ||
| Низкий (менее 4500) | 71,7% | 41,4% | |
| Высокий (не менее 4500) | 28,3% | 58,6% | |
| Итого |
Нетрудно проверить, что проверяемая гипотеза подтвердилась более ярко. Это проявилось в том, что здесь оказалось более высоким значение нашего критерия: 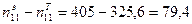 . Причина – более удачная группировка людей по доходу.
. Причина – более удачная группировка людей по доходу.
Заметим, что в ИЭиОПП СО РАН под руководством П.С. Ростовцева разработан пакет программ, реализующий обсужденный подход.
Перейдем к рассмотрению другой ситуации – когда наши группы альтернатив составляются из значений разных признаков. Как мы отмечали, эта ситуация не имеет статистической базы, подобной той, на которую опирается метод анализа фрагментов таблицы сопряженности.

