




Узагальнено-регресійна мережа влаштована аналогічно ймовірнісній нейронній мережі (PNN), але призначена для вирішення задач регресії, а не класифікації. Як і у випадку PNN-мережі, у точку розташування кожного навчального спостереження поміщається гауссівська ядерна функція. Ми вважаємо, що кожне спостереження свідчить про деяку нашу впевненість у тому, що поверхня відгуку у даній точці має певну висоту, і ця впевненість зникає при відході від точки.
GRNN-мережа копіює всередину себе всі навчальні приклади і використовує їх для оцінки відгуку в довільній точці. Остаточна вихідна оцінка мережі виходить як зважене середнє виходів за всіма навчальними спостереженням:
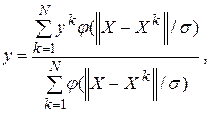 (12.1)
(12.1)
де: X 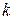 , у – точки навчальної вибірки.
, у – точки навчальної вибірки.
Перший проміжний шар мережі GRNN складається з радіальних елементів. Другий проміжний шар містить елементи, які допомагають оцінити зважене середнє. Кожний вихід має в цьому шарі свій елемент, що формує для нього зважену суму. Щоб одержати із зваженої суми зважене середнє, цю суму потрібно поділити на суму вагових коефіцієнтів. Останню суму обчислює спеціальний елемент другого шару. Після цього у вихідному шарі проводиться ділення (за допомогою спеціальних елементів «розподілу»).
Таким чином, число елементів у другому проміжному шарі на одиницю більше, ніж у вихідному шарі. Як правило, в задачах регресії вимагається оцінити одне вихідне значення, і, відповідно, другий проміжний шар містить два елементи.
Можна модифікувати GRNN-мережу так, щоб радіальні елементи відповідали не окремим навчальним випадкам, а їх кластерам. Це зменшує розміри мережі і збільшує швидкість навчання. Центри для таких елементів можна вибирати за допомогою будь-якого призначеного для цієї мети алгоритму (вибірки з вибірки, К-середніх або Кохонена).
Переваги і недоліки у мереж GRNN в основному такі ж, як і у мереж PNN – єдина відмінність в тому, що GRNN використовуються в задачах регресії, а PNN – в задачах класифікації. GRNN-мережа навчається майже миттєво, але може вийти великою і повільною (хоча тут, на відміну від PNN, не обов'язково мати по одному радіальному елементу на кожний навчальний приклад, їх число буде все одно великим). Як і мережа RBF, мережа GRNN не володіє здатністю екстраполювати дані.
Згідно загальноприйнятому в науці принципу, якщо складніша модель не дає кращих результатів, ніж більш проста, то з них слід вибрати другу. У термінах апроксимації відображень найпростішою моделлю буде лінійна, в якій апроксимуюча функція визначається гіперплощиною. У задачі класифікації гіперплощина розміщується так, щоб вона розділяла собою два класи (лінійна дискримінантна функція); в задачі регресії гіперплощина повинна проходити через задані точки. Лінійна модель звичайно задається рівнянням:
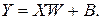 (12.2)
(12.2)
де: W – матриця вагів мережі,
B – вектор зміщень.
На мові нейронних мереж лінійна модель представляється мережею без проміжних шарів, яка у вихідному шарі містить тільки лінійні елементи (тобто елементи з лінійною функцією активації). Вага відповідає елементам матриці, а пороги – компонентам вектора зсуву. Під час роботи мережа фактично перемножує вектор входів на матрицю вагів, а потім до одержаного вектора додає вектор зсуву.
Контрольні питання
1. Поясніть принцип роботи GRNN.
2. Поясніть принцип роботи лінійної роботи НМ.
3. Переваги і недоліки GRNN і лінійної НМ.

