




Серед різноманітних конфігурацій ШНМ зустрічаються такі, при класифікації яких за принципом навчання не підходять ні навчання з вчителем, ні навчання без вчителя. У таких мережах вагові коефіцієнти синапсів рахуються тільки один раз перед початком функціонування мережі на основі інформації про оброблювані дані, і всі навчання мережі зводиться саме до цього розрахунку.
З одного боку, пред'явлення апріорної інформації можна розцінювати як допомога вчителя, але з іншої – мережа фактично просто запам'ятовує зразки до того, як на її вхід поступають реальні дані, і не може змінювати свою поведінку, тому говорити про ланку оберненого зв'язку з «світом» (вчителем) не доводиться. З подібною логікою роботи найбільш відомі мережа Хопфілда і мережа Хеммінга (є різновидами мереж із зворотними зв'язками), які звичайно використовуються для організації асоціативної пам'яті (рис. 9.1).
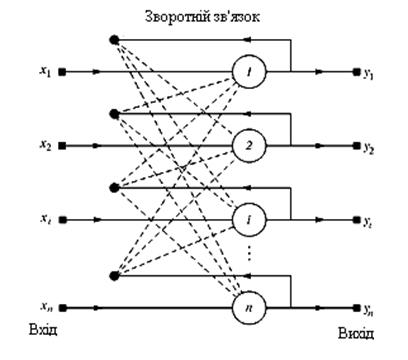 |
Рис.9.1. Структурна схема мережі Хопфілда
Мережа Хопфілда складається з єдиного шару нейронів, число яких є одночасно числом входів і виходів мережі. Кожний нейрон зв'язаний синапсами з всією рештою нейронів, а також має один вхідний синапс, через який здійснюється введення сигналу. Вихідні сигнали, як завжди, утворюються на аксонах.
Задача, яка вирішується даною мережею як асоціативною пам’ятю, як правило, формулюється таким чином. Відомий деякий набір двійкових сигналів (зображень, звукових відцифровок, інших даних, що описують якісь об'єкта або характеристики процесів), які вважаються зразковими. Мережа повинна уміти з довільного неідеального сигналу, поданого на її вхід, виділити («пригадати» за частковою інформацією) відповідний зразок (якщо такий є) або «дати заключення» про те, що вхідні дані не відповідають жодному із зразків.
У загальному випадку, будь-який сигнал може бути описаний вектором X={хi : і=1,2,..., 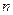 }, – число нейронів у мережі і розмірність вхідних і вихідних векторів. Кожний елемент хi рівний або +1, або -1. Позначимо вектор, що описує k -й зразок, через Xk, а його компоненти, відповідно –
}, – число нейронів у мережі і розмірність вхідних і вихідних векторів. Кожний елемент хi рівний або +1, або -1. Позначимо вектор, що описує k -й зразок, через Xk, а його компоненти, відповідно – 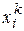 , k=1,2,...,
, k=1,2,..., 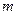 , де – у даному випадку число зразків.
, де – у даному випадку число зразків.
Коли мережа розпізнає (або «пригадає») який-небудь зразок на основі пред'явлених їй даних, її виходи міститимуть саме його, тобто Y=Xk, де Y – вектор вихідних значень мережі: Y={уi: і=1,2,..., }. Інакше, вихідний вектор не співпаде ні з одним зразковим.
Якщо, наприклад, сигнали є якимось зображенням, то, відобразивши в графічному вигляді дані з виходу мережі, можна буде побачити картинку, повністю співпадаючу з однією із зразкових (у разі успіху), або ж «довільну імпровізацію» мережі (у разі невдачі).
На стадії ініціалізації мережі вагові коефіцієнти синапсів встановлюються таким чином:
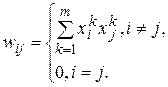 (9.1)
(9.1)
де: і і j – індекси, відповідно, передсинаптичного і післясинаптичного нейронів;
, 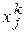 - і-й і j-й елементи вектора
- і-й і j-й елементи вектора 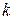 -го зразка.
-го зразка.
Алгоритм функціонування мережі наступний (t - номер ітерації).
1. На входи мережі подається невідомий сигнал. Фактично його введення здійснюється безпосереднім встановленням значень аксонів:
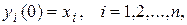 (9.2)
(9.2)
тому позначення на схемі мережі вхідних синапсів в явному вигляді носить чисто умовний характер. Нуль в дужці праворуч від уi означає нульову ітерацію в циклі роботи мережі.
2. Розраховується новий стан нейронів:
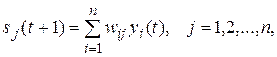 (9.3)
(9.3)
і нові значення аксонів:
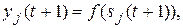 (9.4)
(9.4)
де: f – порогова активаційна функція з порогом 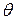 =0.
=0.
3. Перевірка, чи змінилися вихідні значення аксонів за останню ітерацію. Якщо так – перехід до пункту 2, інакше (якщо виходи застабілізувались) – кінець. При цьому вихідний вектор є зразком, що найкращим чином поєднується з вхідними даними.
Доведено, що достатньою умовою стійкої роботи такої мережі є виконання умов:
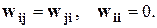 (9.5)
(9.5)
Як було зазначено вище, іноді мережа не може провести розпізнавання і видає на виході неіснуючий образ. Це пов’язано з проблемою обмеженості можливостей мережі. Для мережі Хопфілда число образів N, що запам'ятовується, не повинне перевищувати величини, зразково рівною 0,15n. Крім того, якщо два образи А і B сильно схожі, вони, можливо, викликатимуть у мережі перехресні асоціації, тобто пред'явлення на входи мережі вектора А приведе до появи на її виходах вектора B і навпаки.
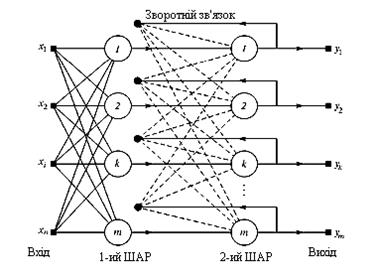 |
Коли немає необхідності, щоб мережа в явному вигляді видавала зразок, то достатньо, одержувати номер зразка, асоціативну пам'ять успішно реалізує мережа Хеммінга. Дана мережа характеризується, у порівнянні з мережею Хопфілда, меншими затратами на об'ємом обчислень, що стають очевидними з її структури (рис. 9.2.).
Рис. 9.2. Структурна схема мережі Хеммінга
Ідея роботи мережі полягає в знаходженні відстані Хеммінга від тестованого образу до всіх зразків (відстанню Хеммінга називається число відмінних бітів в двох бінарних векторах). Мережа повинна вибрати зразок з мінімальною відстанню Хеммінга до невідомого вхідного сигналу, внаслідок чого буде активізований тільки один вихід мережі, відповідний цьому зразку.
Мережа складається з двох шарів. Перший і другий шари мають по m нейронів, де m – число зразків. Нейрони першого шару мають по п синапсів, сполучених з входами мережі (створюючими фіктивний нульовий шар). Нейрони другого шару зв'язані між собою інгібіторними (негативними зворотними) синаптичними зв'язками. Єдиний синапс з позитивним зворотним зв'язком для кожного нейрона сполучений з його ж аксоном.
На стадії ініціалізації ваговим коефіцієнтам першого шару і порогу активаційної функції присвоюються наступні значення:
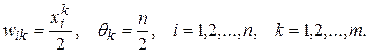 (9.6)
(9.6)
де: - і-й елемент 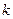 -го зразка.
-го зразка.
Вагові коефіцієнти гальмуючих синапсів у другому шарі беруть рівними деякій величині 0< 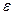 <1/ . Синапс нейрона, пов'язаний з його ж аксоном, має вагу +1.
<1/ . Синапс нейрона, пов'язаний з його ж аксоном, має вагу +1.
Алгоритм функціонування мережі Хеммінга наступний.
1. На входи мережі подається невідомий вектор X={xі : i=1,…,n}, виходячи з якого розраховуються стани нейронів першого шару (верхній індекс у дужках вказує номер шару):
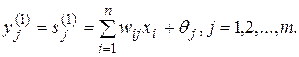 (9.7)
(9.7)
Після цього набутими значеннями ініціалізувалися значення аксонів другого шару:
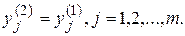 (9.8)
(9.8)
2. Обчислюються нові стани нейронів другого шару:
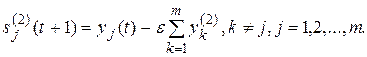 (9.9)
(9.9)
3. Перевіряється, чи змінилися виходи нейронів другого шару за останню ітерацію. Якщо так – перейди до кроку 2. Інакше – завершення.
З оцінки алгоритму видно, що роль першого шару умовна: скориставшися один раз на кроці 1 значеннями його вагових коефіцієнтів, мережа більше не звертається до нього, тому перший шар може бути взагалі виключений з мережі (замінений на матрицю вагових коефіцієнтів).
На закінчення можна зробити наступне узагальнення. Мережі Хопфілда і Хеммінга дозволяють просто і ефективно вирішити задачу відтворення образів за неповною і спотвореною інформацією. Невисока місткість мереж (число образів, що запам'ятовуються) пояснюється тим, що мережі не просто запам'ятовують образи, а дозволяють проводити їх узагальнення наприклад, за допомогою мережі Хеммінга можлива класифікація по критерію максимальної правдоподібності. Разом з тим, легкість побудови програмних і апаратних моделей роблять ці мережі привабливими для багатьох застосувань.
Контрольні питання
1. Наведіть структуру мережі Хопфілда.
2. Алгоритм роботи мережі Хопфілда?
3. Наведіть структуру мережі Хемінга.
4. Алгоритм роботи мережі Хемінга?
5. Області використання НМ Хопфілда і Хемінга?
10. Мережа з радіальними базисними елементами (RBF)
У загальному випадку під терміном Radial Basis Function Network (мережа RBF) розуміється двошарова мережа без зворотних зв'язків, яка містить прихований шар радіально симетричних прихованих нейронів (шаблонний шар). Для того, щоб шаблонний шар був радіально-симетричним, необхідне виконання слідуючих умов:
- наявність центру, представленого у вигляді вектора у вхідному просторі; звичайно цей вектор зберігається в просторі вагів від вхідного шару до шару шаблонів;
- наявність способу вимірювання відстані вхідного вектора від центру; звичайно це стандартна евклідова відстань;
- наявність спеціальної функції проходження від одного аргумента, яка визначає вихідний сигнал нейрона шляхом відбраження функції відстані; звичайно використовується функція Гауса:
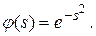 (10.1)
(10.1)
Іншими словами, вихідний сигнал шаблонного нейрона – це функція тільки від відстані між вхідним вектором X і збереженим центром С:
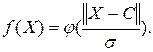 (10.2)
(10.2)
Вихідний шар мережі є лінійним, так що виходи мережі визначаються виразом:
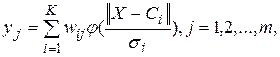 (10.3)
(10.3)
де: Cі – центри,
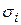 – відхилення радіальних елементів.
– відхилення радіальних елементів.
Навчання RBF-мережі відбувається у декілька етапів. Спочатку визначаються центри і відхилення для радіальних елементів; після цього оптимізуються параметри Wij лінійного вихідного шару.
Розташування центрів, повинно відповідати кластерам, які присутні в початкових даних. Розглянемо два найбільш застосовуваних методів.
Вибірка з вибірки. За центри радіальних елементів беруться декілька випадково вибраних точок які навчають множину. Через випадковість вибору вони «представляють» розподіл навчальних даних у статистичному значенні. Але, якщо число радіальних елементів невелике, таке представлення може бути незадовільним.
Алгоритм К-cеpeдніх. Цей алгоритм прагне вибрати оптимальну нескінченність точок, що є центроїдами кластерів у навчальних даних. При К радіальних елементах їх центри розташовуються так, щоб:
- кожна навчальна точка «відносилася» до одного центру кластера і лежала до нього ближче, ніж до будь-якого іншого центру;
- кожний центр кластера був центроїдом нескінченності навчаючих точок, що відносяться до цього кластера.
Після того, як визначили розміщення центрів, потрібно знайти відхилення. Величина відхилення (її також називають згладжуючим чинником) визначає наскільки «гострою» буде гауссівська функція. Якщо ці функції вибрані дуже гострими, мережа не інтерполюватиме дані між відомими точками і втратить здібність до узагальнення. Якщо ж гауссові функції узяті занадто широкими, мережа не сприйматиме дрібні деталі (насправді сказане – ще одна форма прояву дилеми пере/недонавчання). Як правило, відхилення вибираються так, щоб «вершина» кожної гауссової функцій захоплювала декілька сусідніх центрів. Для цього є декілька методів:
Явний. Відхилення задаються користувачем.
Ізотропний. Відхилення береться однаковим для всіх елементов і визначається евристично з врахуванням кількості радіальних елементів і об'єму простору, що покривається.
До найближчих сусідів. Відхилення кожного елемента встановлюється (індивідуально) рівним середній відстані до його К найближчих сусідів. Тим самим відхилення будуть менше в тих частинах простору, де точки розташовані густо – тут добре враховуватимуться деталі – а там, де точок мало, відхилення будуть великими (і проводитиметься інтерполяція).
Після того, як вибрані центри і відхилення, параметри вихідного шару оптимізуються за допомогою стандартного методу лінійної оптимізації – алгоритму псевдозворотних матриць (сингулярного розкладання).
Можуть бути побудовані різні гібридні різновиди мереж з радіальними базисними функціями. Наприклад, вихідний шар може мати нелінійні функції активації, і тоді для його навчання використовується який-небудь з алгоритмів навчання багатошарових мереж, наприклад метод зворотного розповсюдження. Можна також навчати радіальний (прихований) шар за допомогою алгоритма навчання мережі Кохонена – це ще один спосіб розмістити центри так, щоб вони відображали розташування даних.
Мережі RBF мають ряд переваг перед розглянутими багатошаровими мережами прямого розповсюдження. По-перше, вони моделюють довільну нелінійну функцію за допомогою всього одного проміжного шару, тим самим позбавляючи нас від необхідності вирішувати питання про число шарів. По-друге, параметри лінійної комбінації у вихідному шарі можна повністю оптимізувати за допомогою добре відомих методів лінійної оптимізації, які працюють швидко і не зазнають труднощів з локальними мінімумами, що так заважають при навчанні з використанням алгоритму зворотного розповсюдження помилки. Тому мережа RBF навчається дуже швидко (на порядок швидше, ніж з алгоритмом зворотного розповсюдження).
Недоліки мереж RBF: дані мережі володіють поганими екстраполятивними властивостями і виходять вельми громіздкими при великій розмірності вектора входів.
Контрольні питання
1. Які мають виконуватись умови, щоб шаблонний шар RBF був радіально-семитричними?
2. Як визначаються центри радіальних елементів RBF?
3. Переваги і недоліки RBF.
11. Ймовірнісна нейронна мережа (PNN)
Задача оцінки густини ймовірності за наявними даними має давню історію в математичній статистиці. Звичайно при цьому передбачається, що густина має деякий певний вигляд (частіше всього – що вона має нормальний розподіл). Після цього оцінюються параметри моделі. Нормальний розподіл часто використовується тому, що тоді параметри моделі (середнє і стандартне відхилення) можна оцінити аналітично.
Інший підхід до оцінки густини ймовірності оснований на так званих ядерних оцінках. Можна міркувати так: той факт, що спостереження розташоване в даній точці простору, свідчить про те, що в цій точці є деяка густина ймовірності. Кластери з близьких точок вказують на те, що в цьому місці густина ймовірності велика. Поблизу спостереження є більше довіри до рівня густини, а по мірі віддалення від нього довіра зменшується до нуля. У методі ядерних оцінок в точці, відповідно кожному спостереженню, розміщається деяка проста функція, потім всі вони складаються і в результаті виходить оцінка для загальної густини ймовірності. Частіше за все як ядерні функції беруться гауссівські функції (з формою дзвону). Якщо навчальних прикладів достатня кількість, то такий метод дає достатньо хороше наближення до істинної густини ймовірності.
Метод апроксимації густини ймовірності за допомогою ядерних функцій багато в чому схожий на метод радіальних базисних функцій, і таким чином ми природно приходимо до понять ймовірнісної нейронної мережі (PNN) і узагальнено-регресійної нейронної мережі (GRNN).
PNN-мережі призначені для задач класифікації, а GRNN – для задач регресії. Мережі цих двох типів є реалізацією методів ядерної апроксимації, оформлених у вигляді нейронної мережі.
Мережа PNN має щонайменше три шари: вхідний, радіальний і вихідний. Радіальні елементи беруться по одному на кожне навчальне спостереження. Кожний з них представляє гауссівську функцію з центром у цьому спостереженні. Кожному класу відповідає один вихідний елемент. Кожний такий елемент сполучений зі всіма радіальними елементами, що відносяться до його класу, а зі всією рештою радіальних елементів він має нульове з'єднання. Таким чином, вихідний елемент просто складає відгуки всіх елементів, що належать до його класу. Значення вихідних сигналів виходять пропорційними ядерним оцінкам ймовірності належності відповідним класам, і, пронормувавши їх на одиницю, ми одержуємо остаточні оцінки ймовірності приналежності певним класам.
Вихід такої мережі, відповідний якому-небудь класу:
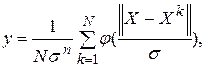 (11.1)
(11.1)
де: 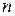 – розмірність вхідного вектора,
– розмірність вхідного вектора,
N – об'єм навчальної вибірки,
X – елемент (вектор) цієї вибірки, відповідний відзначеному класу.
Базова модель PNN-мережі може мати дві модифікації. Ймовірнісна нейронна мережа має єдиний управляючий параметр навчання, значення якого повинно вибиратися користувачем – відхилення гауссівськоої функції 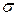 (параметр згладжування). Як і у випадку RBF-мереж, цей параметр вибирається з тих міркувань, щоб «вершини» певне число раз перекривались: вибір дуже маленьких відхилень призведе до «гострих» апроксимуючих функцій і нездатності мережі до узагальнення, а при дуже великих відхиленнях втрачатимуться деталі. Необхідне значення нескладно знайти експериментальним шляхом, підбираючи його так, щоб контрольна помилка була якомога меншою. При цьому, PNN-мережі не дуже чутливі до вибору параметра згладжування.
(параметр згладжування). Як і у випадку RBF-мереж, цей параметр вибирається з тих міркувань, щоб «вершини» певне число раз перекривались: вибір дуже маленьких відхилень призведе до «гострих» апроксимуючих функцій і нездатності мережі до узагальнення, а при дуже великих відхиленнях втрачатимуться деталі. Необхідне значення нескладно знайти експериментальним шляхом, підбираючи його так, щоб контрольна помилка була якомога меншою. При цьому, PNN-мережі не дуже чутливі до вибору параметра згладжування.
Переваги PNN-мереж полягають у тому, що вихідне значення має трактування (і тому його легше інтерпретувати) ймовірності, і в тому, що мережа швидко навчається. При навчанні такої мережі час витрачається практично тільки на те, щоб подавати їй на вхід навчальні приклади, і мережа працює настільки швидко, наскільки це взагалі можливо.
Істотним недоліком таких мереж є їх розмір. PNN-мережа фактично вміщає в себе всі навчальні дані, тому вона вимагає багато пам'яті і може повільно працювати.
PNN-мережі особливо корисні при пробних експериментах (наприклад, коли потрібно вирішити, які з вхідних змінних використовувати), оскільки завдяки короткому часу навчання можна швидко виконати велику кількість пробних тестів.
Контрольні питання
1. Як оцінюється густина ймовірності PNN?
2. Архітектура PNN?
3. Переваги і недоліки PNN.

