




Этап 0: Кодирование(Coding)
ГА оперирует с закодированными параметрами проблемы (оптимизации). Таким образом, в первую очередь, параметры проблемы должны быть представлены в виде строк конечной длины (хромосом).
Хромосома может быть рассмотрена как вектор  , состоящий из
, состоящий из 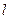 генов
генов
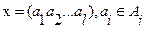 ,
,
где - длина хромосомы, 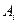 - алфавит.
- алфавит.
Обычно, все - одинаковые, т.е.  .
.
Если А = {0,1}, то хромосома представлена бинарными генами. Если А = R {действительные числа}, то хромосома представлена real-valued генами.
Этап 1: Построение начальной популяции (Initial population construction)
Начальная популяция может быть сгенерирована используя какие-либо первоначальные знания о проблеме, или, в отсутствии таковых, может быть сформирована случайным образом (a random sample of search space). Итак, сгенерируем случайным образом начальную популяцию индивидуумов (решений)  .
.
Этап 2: Оценка пригодности (Fitness evaluation)
На данном этапе вычисляется значение функции пригодности  для каждого индивидуума
для каждого индивидуума  в текущей популяции
в текущей популяции  . Следовательно, каждый член популяции оценивается и снабжается его мерой пригодности (fitness) как решения. Пригодность может быть представлена некоторой функцией пригодности (fitness function) (также называемой как функцией цели, или оценивающей функцией).
. Следовательно, каждый член популяции оценивается и снабжается его мерой пригодности (fitness) как решения. Пригодность может быть представлена некоторой функцией пригодности (fitness function) (также называемой как функцией цели, или оценивающей функцией).
После того, как каждый член популяции оценен, переходим к следующему шагам (3 и 4).
Этап3: Селекция (Selection)
Сформируем промежуточную популяцию (an intermediate population) 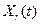 (называемую также как «пул для спаривания» (mating pool), или множество возможных «родителей») с помощью оператора репродукции или селекции (reproduction, или selection operator).
(называемую также как «пул для спаривания» (mating pool), или множество возможных «родителей») с помощью оператора репродукции или селекции (reproduction, или selection operator).
На этом шаге индивидуумы в текущей популяции выбираются для репликации (или reproduction, copy) на основе их функции пригодности. Индивидуумы с высокой пригодностью («хорошие» индивидуумы) могут быть выбраны несколько раз для репродукции, в то время как «плохие» индивидуумы могут быть вообще не выбраны ни разу.
Вероятность 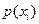 того, что индивидуум будет копирован в следующую генерацию, зависит от отношения величины его пригодности к общей суммарной величине функции пригодности всех индивидуумов популяции F. Это отношение называется ( / F) относительной пригодностью (a relative fitness).
того, что индивидуум будет копирован в следующую генерацию, зависит от отношения величины его пригодности к общей суммарной величине функции пригодности всех индивидуумов популяции F. Это отношение называется ( / F) относительной пригодностью (a relative fitness).
Репродукция производится посредством серии случайных попыток (random trials), в которых каждая хромосома копируется в промежуточную популяцию такое число раз, которое пропорционально ее относительной пригодности. Эта случайная процедура, например, может быть подобна известной случайной процедуре Монте-Карло, называемой также «колесом фортуны» (или рулеткой) (Monte Carlo random procedure, или “wheel of fortune” (Roulette wheel)).
На рис.2.22 показана процедура метода Монте-Карло.
Каждая хромосома в процедуре «рулетки» занимает площадь пропорциональную ее относительной пригодности. Ожидаемое число раз (= 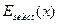 ) того, что хромосома будет отобрана (selected) в серии попыток (обычно равных размеру популяции) определяется следующим образом:
) того, что хромосома будет отобрана (selected) в серии попыток (обычно равных размеру популяции) определяется следующим образом:
 , (2.10)
, (2.10)
где N – размер популяции и
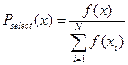 . (2.11)
. (2.11)
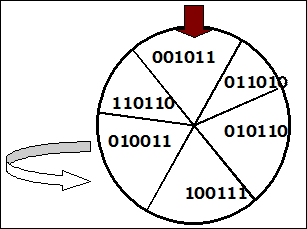
Рис. 2.22. Иллюстрация процедуры Монте-Карло
Примечание 1. Мы аппроксимируем число в формуле (2.10) до ближайшего целого.
Примечание 2. Помимо процедуры «рулетки» могут использоваться другие методы селекции. Например, такие, как:
· uniform selection: каждая хромосома имеет равный шанс быть выбранной независимо от ее пригодности;
· tournament selection: небольшое число хромосом выбираются некоторым способом, после чего они соревнуются друг с другом на основе пригодности;
· Selection with elitism: лучшие хромосомы переводятся в следующее поколение без изменения. Остальные хромосомы участвуют в селекции.
В отсутствие любого другого механизма, процедура селекции со временем «заставит» «лучших» индивидуумов занимать все большую долю в популяции.
Этап 4: Кроссинговер (скрещивание) и мутация (Crossover and Mutation) На этом этапе происходит генерация следующей популяции  с помощью применения к промежуточной популяции генетических операторов. При этом выбранные хромосомы обмениваются генами, образуя новое множество индивидуумов – новую популяцию. Рассмотрим два основных генетических оператора поиска: кроссинговер и мутация.
с помощью применения к промежуточной популяции генетических операторов. При этом выбранные хромосомы обмениваются генами, образуя новое множество индивидуумов – новую популяцию. Рассмотрим два основных генетических оператора поиска: кроссинговер и мутация.
Кроссинговер оператор
Кроссинговер является первичным. Он осуществляет следующие функции:
1. выбирает двух «родителей»,
2. комбинирует гены (черты) родителей,
3. формирует двух «похожих детей», т.е. потомков (offspring).
Существует много типов кроссинговера. Простейший из них описывается следующим образом. Пара родителей выбирается случайным образом. Для каждой пары также случайным образом выбирается так называемая «точка кроссовера» (a point of crossover) (одна, или две, или несколько). Эта точка указывает, какое число бит с правого конца каждой хромосомы (строки битов) должно обменяться друг с другом. Например, если пара родителей представляется в виде следующих строк-хромосом:  и
и 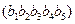 . Пусть точка кроссовера = 3 и пусть эта точка показывается символом “
. Пусть точка кроссовера = 3 и пусть эта точка показывается символом “ 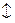 “. Тогда имеем следующую схему обмена:
“. Тогда имеем следующую схему обмена:
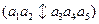 и
и 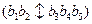 .
.
Кроссовер оператор сгенерирует следующих «потомков»:
 и
и  .
.
Можно видеть, что непрерывные группы бит с правого конца хромосом обмениваются своими значениями.
Примечание. Существуют другие типы оператора скрещивания, например, такие как:
a) Uniform crossover:
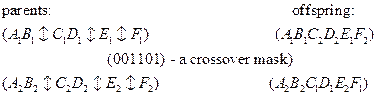
Чтобы обобщить процесс кроссовера, в этом случае используется специальная строка, называемая a crossover mask. 1 в строке-маскеозначает, что соответствующие биты в хромосомах должны обменяться своими значениями. 0 означает, что обмена не происходит.
b) Linear interpolation 2-point crossover:
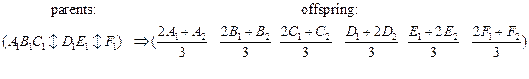
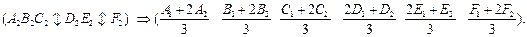
Как следует из определения, при производстве новых индивидуумов (для дальнейшего тестирования) оператор кроссовер базируется только на той информации, которая присутствует в родителях.
Оператор мутации
Оператор мутации, который меняет одну или несколько бит в выбранной хромосоме, обеспечивает способ, с помощью которого вносится новая информация в новое поколение. В литературе предлагается большой диапазон операторов мутации, начиная от случайных до более эвристических операторов поиска. Оператор мутации является вторым оператором поиска, который позволяет ГА исследовать все точки пространства поиска. В результате, сгенерированные потомки оцениваются и возвращаются в популяцию, замещая «родителей».
Примечание. Сколько членов популяции замещаются в течение каждой итерации и как выбираются члены популяции для замещения – определяют тот или иной тип ГА.
Этап 5: Критерий останова (Checking of the End_Test)
t = t+ 1; IF NOT (End_Test) THEN go to Step2; else stop.
Критерий останова (“End_Test”) описывает условия окончания ГА. Обычно это либо заданное общее число генераций поколений (например, 200), либо общее время работы (например, 3 часа) и т.д. По окончанию работы ГА, индивидуумы последней популяции представляют решение заданной задачи оптимизации. Рассмотрим простой пример оптимизации с помощью ГА.
Пример: Оптимизация на основе ГА.
Поставим следующую задачу: найти максимум функции  на интервале целых чисел [0-31] с помощью механизма поиска ГА. Итак, имеем следующую проблему для ГА:
на интервале целых чисел [0-31] с помощью механизма поиска ГА. Итак, имеем следующую проблему для ГА:
найти величину , которая дает максимум функции пригодности 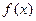 .
.
Прежде всего, ГА работает с хромосомами (закодированными параметрами проблемы, которую оптимизируем). Следовательно, параметры нашей задачи, а именно числа интервала [0-31] должны быть закодированы. Будем использовать бинарное кодирование. Рассмотрим строки, состоящие из пяти бит: от {00000} до {11111}.
Примечание. Бинарная строка длины  может представлять
может представлять 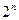 индивидуумов. Следовательно, строки длиной
индивидуумов. Следовательно, строки длиной 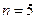 могут представлять числа 1,2,3,...,32 (25 = 32). Пусть начальная популяция сформирована случайным образом, например, так, как показано в Таблице 2.2.
могут представлять числа 1,2,3,...,32 (25 = 32). Пусть начальная популяция сформирована случайным образом, например, так, как показано в Таблице 2.2.
Таблица 2.2
Начальная популяция


Примечание. В таблице 2.2 представлены числа в двух формах: бинарной и десятичной. Напомним правило перевода бинарного числа в десятичное:
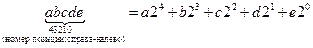 .
.
Например,
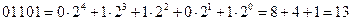 .
.
Следующий шаг – репродукция. Оператор репродукции оценивает и выбирает пары для формирования промежуточной популяции (mating pool) следующим образом: одна копия строки 01101, две копии строки 11000 и одна копия 10011 выбраны с использованием процедуры «рулетки».
Теперь применим кроссинговер оператор так, как показано в Таблице 2.3. Точка кроссовера получена с помощью генератора случайных чисел.
Таблица 2.3
Строки Mating pool и crossover
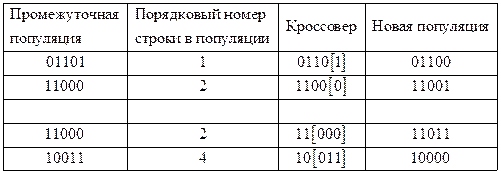
После «кроссинговера» применяется оператор мутации, который случайным образом модифицирует хромосому (строку). Для определения вероятности мутации используются специальные вероятностные функции. В Таблице 2.4 показана новая популяция строк после применения мутации (как видно, в данном случае вероятность мутации равна нулю).
Таблица 2.4
Новая популяция строк

На следующем шаге проверяется критерий останова. Легко увидеть, что ГА довольно быстро (в нашем примере только двумя генерациями популяций решений) находит решение, близкое к искомому, финальному, оптимуму.
Итак, последняя (после останова ГА) популяция представляет собой решение проблемы оптимизации. В этом случае мы говорим, что ГА сходится к оптимальному решению. Сходимость ГА означает, что все хромосомы в конечной популяции имеют одни и те же гены. Таким образом, даже простой ГА представляет собой сложный процесс обработки информации.
В заключение, приведем также определение ГА:
Генети́ческий алгори́тм — это эвристический алгоритм поиска, используемый для решения задач оптимизации и моделирования путём случайного подбора, комбинирования и вариации искомых параметров с использованием механизмов, напоминающих биологическую эволюцию. Является разновидностью эволюционных вычислений. Отличительной особенностью генетического алгоритма является акцент на использование оператора «скрещивания», который производит операцию рекомбинации решений-кандидатов, роль которой аналогична роли скрещивания в живой природе.
На рис. 2.23 (a,b,c,d) приведена блок-схема вычислений ГА.

(a) Кодирование и оценка (Coding and Evaluation)
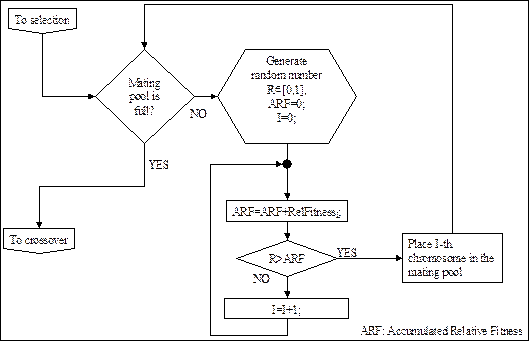
(b) Селекция (Selection)
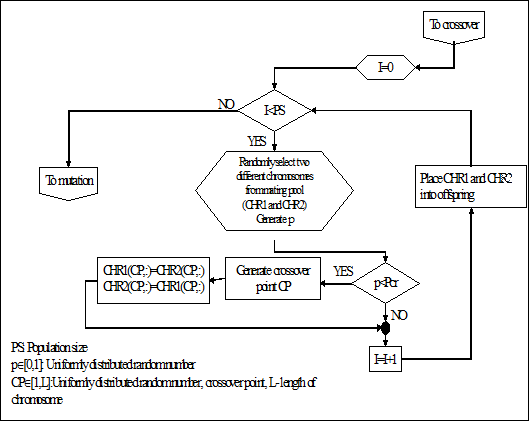
(c) Кроссинговер (Crossover)
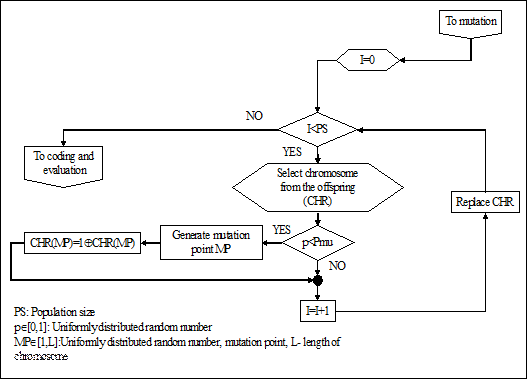
(d) Мутация (Mutation)
Рис. 2.23. Блок-диаграмма ГА
Теоретические основы ГА
Математическая модель ГА может быть представлена следующим упорядоченным набором:
 ,
,
где
 – система кодирования (Coding system);
– система кодирования (Coding system);
 – функция пригодности (Fitness function);
– функция пригодности (Fitness function);
 – начальная популяция (Initial population);
– начальная популяция (Initial population);
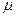 – размер начальной популяции (Population size);
– размер начальной популяции (Population size);
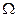 – операция селекции (Selection operation);
– операция селекции (Selection operation);
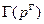 – операция скрещивания (Crossover operation),
– операция скрещивания (Crossover operation),
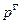 – вероятность скрещивания (Probability of crossover);
– вероятность скрещивания (Probability of crossover);
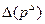 – операция мутации (Mutation operation),
– операция мутации (Mutation operation),
 – вероятность мутации (Probability of mutation);
– вероятность мутации (Probability of mutation);
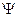 – условие остановки (Termination condition).
– условие остановки (Termination condition).
Система кодирования является унитарной операцией, определяющей отображение пространства решений в некоторое пространство, на котором определены генетические операции. Простым примером кодирования является двоичное кодирование, отображающее пространство вещественных чисел в пространство бинарных строк заданной длины:
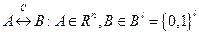 ,
,
где
 - пространство вещественных векторов размерности ;
- пространство вещественных векторов размерности ;
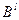 - пространство двоичных строк длины .
- пространство двоичных строк длины .
В большинстве программных реализаций ГА, предпочтение отдается двоичному кодированию. Во многом это связано с простотой реализации генетических операций над двоичными строками. Такая кодировка гарантирует также максимальную энтропию внутри популяции.
Начальная популяция есть набор равномерно распределенных в пространстве кодирования элементов. В случае двоичного кодирования - набор различных двоичных строк длины .
Размер популяции есть число индивидуумов (хромосом), входящих в популяцию. Функция пригодности является критерием, определяющим качество данного индивидуума. Обычно функция пригодности оценивает отклик некоторой внешней функции или динамической системы на параметры, закодированные в данной хромосоме. В случае сложных нелинейных задач оптимизации, вычисление значения функции является наиболее трудоемкой процедурой, требующей большего машинного времени, по сравнению с остальными генетическими операциями.
Как правило, ГА не использует непосредственные значения функции пригодности. Обычно осуществляется нормализация значений и вычисляется так называемый относительный критерий качества, распределяющий вес каждой из хромосом в текущей популяции.
На рис.2.24 представлена блок-схема операций кодирования и вычисления значения функции пригодности.
Оператор селекции (Selection) является вероятностной операцией, определенной для воспроизведения большего числа хромосом с большим значением функции пригодности в следующем поколении. В частности, в некоторых реализациях генетических алгоритмов, оператор селекции выбирает набор хромосом в промежуточную популяцию, к которой в дальнейшем могут быть применены операции скрещивания и мутации. Оператор селекции работает по принципу рулетки. При этом индивидуумам с большим значением функции пригодности выделяется больший сектор рулетки. Таким образом, после вращения рулетки, вероятность выбора индивидуумов с большим значением функции пригодности увеличивается.
Блок-схема реализации оператора селекции представлена на рис.2.25.
Операция скрещивания 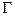 является вероятностной операцией, предназначенной для обмена генетической информацией между индивидуумами, входящими в данную популяцию. Вероятность данной операции обычно задается пользователем и меняется в зависимости от типа решаемой задачи.
является вероятностной операцией, предназначенной для обмена генетической информацией между индивидуумами, входящими в данную популяцию. Вероятность данной операции обычно задается пользователем и меняется в зависимости от типа решаемой задачи.
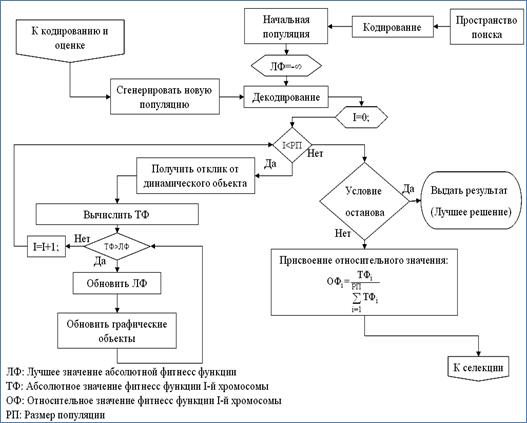
Рис. 2.24. Операции кодирования и вычисления объектных функций ГА
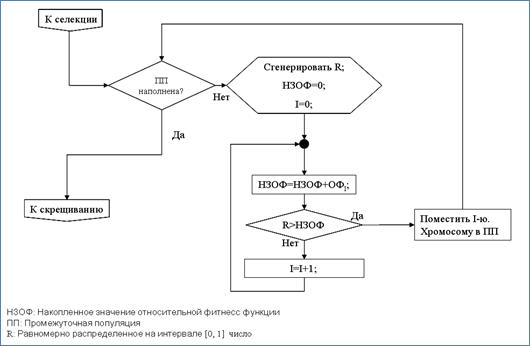
Рис. 2.25. Блок-схема реализации операции селекции методом рулетки.
Входом операции скрещивания является промежуточная популяция, получаемая после операции селекции .
Операция скрещивания (на примере бинарного кодирования ) реализуется следующими шагами:
1. Выбрать два индивидуума из промежуточной популяции;
2. Сгенерировать случайное число, равномерно распределенное на интервале [0, 1] и если полученное число меньше , выполнить операцию скрещивания, если нет, перейти к шагу 5;
3. Сгенерировать точку скрещивания, равномерно распределенное случайное число на интервале [0, l];
4. Поменять местами части выбранных индивидуумов, правее точки скрещивания;
5. Поместить выбранные хромосомы в новую популяцию;
6. Повторить шаги 1-5 до заполнения новой популяции.
Блок схема операции скрещивания представлена на рис. 2.26.
В некоторых реализациях ГА, операция скрещивания применяется несколько раз для одних и тех же хромосом. В таком случае говорят о двухточечном скрещивании (two-point crossover). Выбор числа применений операции скрещивания зависит от конкретной задачи, а также связан со значениями основных параметров ГА.
Рис. 2.26. Блок-схема реализации операции скрещивания
Теоретически операции селекции и скрещивания позволяют находить экстремумы выпуклых функций, или достигать локальных экстремумов при многоэкстремальной оптимизации. По своей структуре данные операции «стерильны». ГА, построенный только на операциях селекции и скрещивания, как правило, не справляется с решением задачи нахождения глобального оптимума многоэкстремальной целевой функции. Для его достижения алгоритму необходима операция мутации.
Операция мутации является унитарной вероятностной операцией, предназначенной для внесения новой информации в данную популяцию. Операция мутации позволяет ГА избегать локальных экстремумов, т.к. генерирует хромосомы, находящиеся на достаточном удалении от оригинала.
Алгоритм мутации реализуется следующими шагами:
1. Выбрать случайным образом индивидуум из промежуточной популяции;
2. Сгенерировать случайное число равномерно распределенное на интервале [0 1]. Если полученное число меньше , выполнить операцию мутации. В противном случае перейти к шагу 5;
3. Сгенерировать точку мутации (mutation point) - случайное число равномерно распределенное на интервале [0 l];
4. Инвертировать бит, находящийся в точке мутации;
5. Поместить выбранную хромосому в новую популяцию;
6. Повторить шаги 1-5 до заполнения популяции.
Блок – схема реализации операции мутации представлена на рис. 2.27.
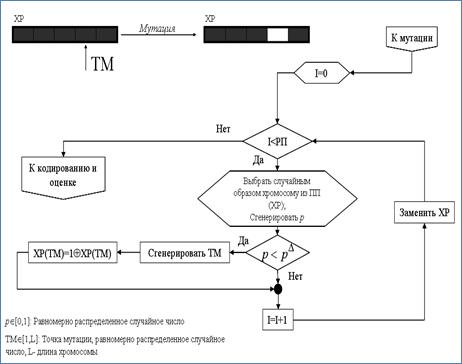
Рис. 2.27. Блок-схема реализации операции мутации
Как и в случае с операцией скрещивания, операцию мутации можно применять несколько раз к одной и той же хромосоме. В таком случае говорят о многоточечной мутации.
Фундаментальная теорема Холланда
Оптимизация с помощью ГА основывается на фундаментальной теореме Холланда (Fundamental Theorem of GA).
Прежде, чем привести данную теорему, дадим необходимые определения.
Простой ГА обычно использует бинарное кодирование для хромосом (строк). Будем говорить, что такие строки генерируются в алфавите A = {0,1}. Каждый символ (бит) в строке идентифицируется своим положением (бит-позицией). Бит-позиция равная 1 означает первый левый символ в строке.
Определение: схема (a schema) S есть строка, построенная с помощью алфавита A’ = {0,1,*}, где «*» означает: «неважно какой символ» в данной позиции. Например, следующая строка является схемой:
S = * 1 * 0 * * 0 0. (2.12)
Определение: представитель схемы (a representative of a schema)
Строка, совпадающая со схемой во всех ее определенных (0 или 1) бит-позициях, называется представителем данной схемы.
Например, следующие ниже строки A, B, и C являются представителями схемы S, приведенной в (2.12).
A = 1 1 0 0 1 0 0 0
B = 0 1 1 0 0 0 0 0
C = 1 1 1 0 1 1 0 0.
Определение: порядок схемы (an order of a schema)
Порядком схемы, o (S), называется число определенных (0 или 1) бит-позиций
Например, схема S, приведенная в (2.12), имеет порядок o (S) = 4.
Определение: определяющая длина схемы (a defining length of a schema)
Определяющей длиной схемы,  (S), называется расстояние между самой левой определенной (0 или 1) бит-позицией (
(S), называется расстояние между самой левой определенной (0 или 1) бит-позицией ( ) и самой правой определенной (0 или 1) бит-позицией (
) и самой правой определенной (0 или 1) бит-позицией ( ). (S) вычисляется как:
). (S) вычисляется как: 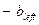 .
.
Например, схема S, приведенная в (2.12), имеет следующую определяющую длину:
(S) = = 8 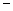 2 = 6.
2 = 6.
Скрытый параллелизм ГА
Предположим, что имеем дело со строками длины . Каждая строка представляет  схем.
схем.
Например, строка 1101 имеет длину 4, и, следовательно, представляет 24 =16 следующих схем:
1100, 110*, 11*0, 11**, 1*00, 1*0*, 1**0, 1***, *100, *10*, *1*0, *1**, **00, **0*, ***0, 0***, ****.
Популяция из строк удовлетворяет следующему неравенству:
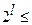

 ,
,
где - общее число схем.
Так как каждая строка может представлять много схем, то это значит, что ГА операторы, работающие с популяцией строк, тем самым работают с еще большим числом схем. Это свойство называется свойством скрытого параллелизма ГА (implicit parallelism of GA).
Рассмотрим следующую задачу. Пусть некоторая схема S имеет число ее представителей в популяции в момент времени t, равное 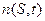 . Вычислим, сколько ее представителей появится в следующей генерации популяции, т.е.
. Вычислим, сколько ее представителей появится в следующей генерации популяции, т.е.
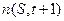 =?
=?
Это число зависит от ГА операторов репродукции, кроссовера и мутации. Ответ на этот вопрос дается в следующей фундаментальной теореме Холланда.
Теорема схем (Schema Theorem): фундаментальная теорема ГА
Схемы растут экспоненциально, если они имеют высокие значения функции пригодности, короткие определяющие длины и малый порядок, т.е.

где:
- число представителей схемы S в момент времени t;
 - среднее значение функции пригодности для схемы S;
- среднее значение функции пригодности для схемы S;
 - среднее значение функции пригодности для всей популяции;
- среднее значение функции пригодности для всей популяции;
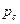 - вероятность оператора кроссовера; - длина строки (хромосомы);
- вероятность оператора кроссовера; - длина строки (хромосомы);
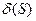 - определяющая длина схемы S;
- определяющая длина схемы S; 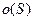 - порядок схемы S;
- порядок схемы S;
 - вероятность мутации.
- вероятность мутации.
Основное следствие из теоремы: популяция представителей с высокими значениями функции пригодности растет экспоненциально во времени. Теорема доказывает асимптотическую сходимость решений, найденных ГА, к глобальному оптимуму.
Обсудим характерные особенности ГА
1. Замечательная черта ГА состоит в том, что они выполняют множество изощренных манипуляций с решениями задачи без малейшего представления о том, что же при этом происходит. Процедура кроссинговера берет два решения и создает из них два новых решения, смешивая части первого и второго. Все, что для этого нужно, - выбор случайной позиции в битовой строке и перестановка двух подстрок. Единственное, что нужно также знать, - длину двоичной хромосомы. То же самое относится и к процедурам мутации, и даже создания начальной популяции. Благодаря этому свойству достаточно один раз программно реализовать ГА, а потом использовать его для решения множества самых разнообразных задач без сколько-нибудь серьезного изменения кода.
2. Конструирование хромосомы является самым важным этапом создания ГА.
3. Функция пригодности (ФП) - это единственная часть программы, которая должна понимать, что же на самом деле кодирует хромосома. Поэтому для каждого приложения надо писать новые ФП.
4. Объем пространства поиска - важнейший, хотя и не единственный фактор, влияющий на качество работы ГА. Большие пространства труднее "обыскать", и шансы найти оптимальное или просто хорошее решение уменьшаются.
Примечание. Если пространство поиска простое и содержит лишь один пик функции пригодности (Рис. 2.28,а), то при помощи ГА мы быстро найдем оптимальное решение. Если же оно более сложное (Рис. 2.28,б) и мы начинаем восхождение вблизи одного из небольших пиков (локальных максимумов), то глобальный оптимум может быть найден, но за достаточно большое время. При этом ГА эффективно просматривает пространство поиска, сохраняя хороших родителей, которые чаще, чем плохие, дают хорошее потомство. Поэтому такой алгоритм с большей вероятностью найдет хорошее решение задачи.

Рис. 2.28. Различные пространства поиска для ГА
В заключение этого параграфа обсудим также основные различия между классическими методами оптимизации и ГА.
Основные различия между классическими методами оптимизации и ГА
1. Классические методы оптимизации представляют собой класс методов, базирующихся на вычислении производной оптимизируемой функции (derivative based methods). В отличие от них ГА-оптимизация не требует производных значений (derivative free optimization) функции пригодности. Таким образом, ГА могут использоваться как для непрерывных, так и для дискретных оптимизационных проблем.
2. Классические методы оптимизации работают с параметрами данной задачи оптимизации. ГА оперирует с популяцией закодированных параметров. Таким образом, параметры проблемы (оптимизации) должны быть закодированы строками конечной длины. Строки могут представлять последовательности из любых символов. Обычно в ГА используются бинарные символы (0 или 1). Выбор метода кодирования параметров – очень важен.
3. ГА-оптимизация осуществляется на множестве строк с использованием вероятностного механизма и вычисления значений пригодности строк.
4. ГА может работать без привлечения каких-либо знаний о пространстве поиска и является проблемно независимым алгоритмом.
5. ГА обеспечивает средствами поиска оптимального решения в плохо структурированных областях (in poorly understood and irregular spaces).

