




Во многих задачах требуется установить и оценить зависимость изучаемой случайной величины от одной или нескольких других величин.
Статистическая зависимость – это зависимость, при которой изменение одной величины влечет изменение распределения другой.
Корреляционная зависимость – это статистическая зависимость, при которой изменение одной из величин влечет изменение среднего значения другой.
При большом числе наблюдений одно и то же значение Х может встретиться nx раз, а одно и то же значение У – ny раз, тогда одна и та же пара (Х, У) может встретиться nxy раз. В этом случае данные группируют, т.е. подсчитывают частоты nx, ny, nxy.
Все сгруппированные данные записывают в виде таблицы, которая называется корреляционной, в первой строке и первом столбце которой перечисляются наблюдаемые значения признаков Х и У. На пересечении строк и столбцов находятся nxy наблюдаемых пар значений признаков. В последней строке и последнем столбце записаны суммы частот столбцов и строк, т.е. nx и ny. В крайней нижней правой клетке помещена сумма всех частот n – общее число всех наблюдений (аналог объема выборки).
! 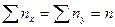
Например, рассмотрим корреляционную таблицу вида:
| У | Х | ny | |||
| - | |||||
| - | |||||
| - | - | ||||
| nx | n=60 |
Здесь, например, пара (30, 4) наблюдалась 7 раз, а само значение признака Х=30 наблюдалось всего 13 раз и т.д.
Регрессией У на Х, т. е. условным математическим ожиданием случайной величины У относительно случайной величины Х, называется функция вида М(У/Х) = f(х).
Оценкой этой функции является выборочное уравнение регрессии:  =f*(x), причем на практике чаще используются уравнения линейной регрессии.
=f*(x), причем на практике чаще используются уравнения линейной регрессии.
Выборочное уравнение прямой линии регрессии Y на Х по
| сгруппированным данным имеет вид: | 
|
где - условная средняя; 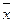 и
и  - выборочные средние признаков Х и Y; sх и sу – выборочные средние квадратические отклонения; r B – выборочный коэффициент корреляции.
- выборочные средние признаков Х и Y; sх и sу – выборочные средние квадратические отклонения; r B – выборочный коэффициент корреляции.
Если данные наблюдений над признаками Х и Y заданы в виде корреляционной таблицы с равноотстоящими вариантами, то целесообразно перейти к условным вариантам u и v: ui =  , vj =
, vj =  , где С1 и С2 – ложные нули (С1 – значение признака Х с наибольшей частотой, С2 – значение признака Y с наибольшей частотой), h1 – шаг варианты Х, h2 – шаг варианты Y. Тогда выборочный коэффициент корреляции вычисляют по формуле: rB =
, где С1 и С2 – ложные нули (С1 – значение признака Х с наибольшей частотой, С2 – значение признака Y с наибольшей частотой), h1 – шаг варианты Х, h2 – шаг варианты Y. Тогда выборочный коэффициент корреляции вычисляют по формуле: rB =  .
.
Величины 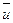 ,
,  , su, sv можно найти методом произведений, а при малом числе данных – по определению, а именно
, su, sv можно найти методом произведений, а при малом числе данных – по определению, а именно  ,
,  ,
,
su =  , sv =
, sv =  , где
, где  ,
,  . После чего можно найти величины, входящие в уравнение регрессии, по формулам:
. После чего можно найти величины, входящие в уравнение регрессии, по формулам:  ,
,  , sх = suh1, sy = svh2.
, sх = suh1, sy = svh2.
Метод нахождения 
Для этого составляют корреляционную таблицу в условных вариантах, после чего составляют специальную таблицу:
1. В каждой клетке, в которой nuv ¹ 0, в правом верхнем углу записывают произведение nuv на u.
2. Складывают все числа, помещенные в этих правых верхних углах и их суммы записывают в столбец U.
3. Умножают варианту v на U по строкам и записывают результаты в последнем столбце vU.
4. Суммируют элементы последнего столбца. Полученная сумма и равна .
5. Для контроля аналогичные вычисления производят по столбцам (в левых нижних углах клеток, в которых nuv ¹ 0).
Пример 5. Найти по данным корреляционной таблицы:
| Y | X | ny | |||||
| - | - | - | - | - | |||
| - | - | - | |||||
| - | - | - | |||||
| - | - | - | |||||
| - | - | - | - | ||||
| nx | n=100 |
Решение: составим корреляционную таблицу в условных вариантах (в качестве ложных нулей лучше взять х4=33, т.е. С1=33, и у3=175, т.е. С2=175):
| V | U | nv | |||||
| -3 | -2 | -1 | |||||
| -2 | - | - | - | - | - | ||
| -1 | - | - | - | ||||
| - | - | - | |||||
| - | - | - | |||||
| - | - | - | - | ||||
| nu | n=100 |
Теперь, по этой таблице составим еще одну – расчетную для вычисления :
 U
V U
V
| -3 | -2 | -1 | U=
| vU | |||
| -2 | -2 -2 | -2 | ||||||
| -1 | -3 -1 | -4 -2 | -5 -5 | -12 | ||||
| -6 | -12 | -18 | ||||||
| -1 | ||||||||
V=
| -1 | -4 | -4 |  48 48
| ||||
| uV | 48
| конт- роль |
Итак, в правых нижних углах получили 48, значит = 48.
Ответ: = 48.
Пример 6. Найти выборочное уравнение прямой линии регрессии Y на Х  по данной корреляционной таблице:
по данной корреляционной таблице:
| Y | X | ny | |||||
| - | - | - | - | - | |||
| - | - | - | |||||
| - | - | - | |||||
| - | - | - | |||||
| - | - | - | - | ||||
| nx | n=100 |
Решение: составим корреляционную таблицу в условных вариантах (в качестве ложных нулей лучше взять х4=33, т.е. С1=33, и у3=175, т.е. С2=175):
| V | U | nv | |||||
| -3 | -2 | -1 | |||||
| -2 | - | - | - | - | - | ||
| -1 | - | - | - | ||||
| - | - | - | |||||
| - | - | - | |||||
| - | - | - | - | ||||
| nu | n=100 |
1. Вычислим теперь , , su, sv:
=  = -0,13;
= -0,13;
=  =0,22;
=0,22;
=  =0,81;
=0,81;
= 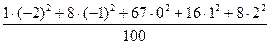 =0,6, значит,
=0,6, значит,
su = 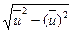 =
=  =0,89; sv =
=0,89; sv =  =
=  =0,74.
=0,74.
Найдем выборочный коэффициент корреляции rB = , где = 48 (см. пример 35); = -0,13; =0,22; su = 0,89; sv = 0,74. Тогда
rB =  =0,73.
=0,73.
2. С1=33, h1=23 – 18=5; C2=175, h2=150 – 125=25.
Значит, можно вычислить , , sх , sy:
= -0,13×5+33= 32,35; =0,22×25+175=180,5;
sх = suh1 = 0,89×5=4,45; sy = svh2 = 0,74×25=18,5.
Подставим полученные значения в уравнение прямой линии регрессии Þ  Þ =3,03х +82,48 – искомое уравнение.
Þ =3,03х +82,48 – искомое уравнение.
Ответ: =3,03х +82,48.
| Лекция 4 | Статистический анализ. Многомерный статистический анализ. Дисперсионный анализ. Однофакторный и двухфакторный дисперсионный анализ. Дискриминантный анализ; кластерный анализ; факторный анализ |

