




Імітаційні моделі дозволяють проводити чисельні експерименти є надзвичайно універсальними.
При експериментуванні на імітаційній моделі можливе внесення таких змін:
· в структуру моделі
· моделей поведінки, параметрів моделей
· параметрів та законів розподілу випадкових факторів
· значень та зміни в часі зовнішніх змінних.
Імітаційна модель повинна відповідати таким вимогам:
· логічна причинно-наслідковість повинна відповідати характеристикам системи, що моделюється
· характер та зміст інформації про процеси, що спостерігаються за допомогою моделі повинні зберігатися подібними до системи
· в моделі повинні спостерігатися змінні, що єсуттєвими з точки зору дослідника в реальній системі.
Реалізація імітаційного підходу набуває все більших можливостей з розвитком комп’ютерної техніки і це своєю чергою відбивається на розробці методологій імітаційного моделювання. Методології імітаційного моделювання являють собою комбінування методологій побудови складових імітаційних моделей, таких як застосовуються при аксіоматичному підході, побудові оптимізаційних моделей та моделей “чорної скриньки”.
7. СИСТЕМНІ АСПЕКТИ ЗАСТОСУВАННЯ СТОХАСТИЧНОГО ТА ТЕОРЕТИКО-МНОЖИННОГО ПІДХОДІВ ДЛЯ ПОБУДОВИ МОДЕЛЕЙ “ВХІД-ВИХІД”.
Основні задачі синтезу моделей “вхід-вихід” статичних систем на основі експериментальних даних.
Особливості стохастичного підходу.
Основні етапи регресійного аналізу.
Методологія теоретико-множинного, інтервального підходу.
Планування насичених експериментів у випадку інтервального представлення вихідних змінних моделей статичних систем.
Методологічні аспекти структурної ідентифікації моделей систем.
7.1. Основні задачі синтезу моделей “вхід-вихід” статичних систем на основі експериментальних даних
Найбільшого поширення серед моделей систем, що будуються в умовах невизначеності, набули статистичні та імовірнісні моделі типу “вхід-вихід”, які задають залежність між вихідними показниками системи та її входами. Серед них можна виділити регресійні моделі, якими описують статичні (безінерційні) системи. При цьому висувають припущення, що систему можна описати функціональною залежністю у такому вигляді:

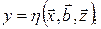
де 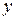 – вихідна змінна;
– вихідна змінна; 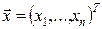 – вектор вхідних змінних, які можна змінювати в деякій області
– вектор вхідних змінних, які можна змінювати в деякій області 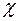 ;
;  – вектор параметрів функції
– вектор параметрів функції 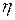 ;
;  – вектор неврахованих або невизначених факторів, шумів, похибок (як правило) випадкової природи та ін.
– вектор неврахованих або невизначених факторів, шумів, похибок (як правило) випадкової природи та ін.
Переважно кожна вихідна характеристика системи описується окремою функціональною залежністю. Тому надалі не обмежуючи загальності будемо розглядати моделі статичних систем з однією вихідною зміною.
Основою для побудови математичної моделі системи часто є результати експерименту, який можна зобразити у вигляді матриці значень вхідних та вектора значень вихідної змінної у всіх спостереженнях:

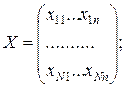
 . (7.1)
. (7.1)
Рядкам матриці  відповідають вектори
відповідають вектори 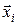 (
( ) вхідних змінних, що при експериментуванні викликають відповідні значення вихідної змінної
) вхідних змінних, що при експериментуванні викликають відповідні значення вихідної змінної  . Комбінацію ,
. Комбінацію ,  називатимемо спостереженням. Загальна кількість комбінацій N задає кількість спостережень експерименту.
називатимемо спостереженням. Загальна кількість комбінацій N задає кількість спостережень експерименту.
Надалі експериментальні дані будемо розглядати у більш розширеному тлумаченні: – не лише як результат вимірювання значень змінних на реальній системі, але й як результати розрахунків на ЕОМ із застосуванням імітаційної моделі системи, дані експертного опитування і т.д.
Розглянемо три найпоширеніших задачі, що базуються на даних експерименту у вигляді (7.1).
Представлення даних  деякою функцією
деякою функцією 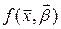 називають задачею ідентифікації статичної системи. На сьогоднішній день виділяють задачі ідентифікації об’єкта в “широкому” тлумаченні, коли потрібно знайти вид (структуру) функції та її параметри
називають задачею ідентифікації статичної системи. На сьогоднішній день виділяють задачі ідентифікації об’єкта в “широкому” тлумаченні, коли потрібно знайти вид (структуру) функції та її параметри  і найпростішу параметричну задачу ідентифікації. У випадку параметричної ідентифікації структуру функції вважають відомою. Тоді задача ідентифікації зводиться лише до оцінювання невідомих параметрів. Вона розв’язується просто, якщо функція є лінійно-параметричною, тобто записується у такому вигляді:
і найпростішу параметричну задачу ідентифікації. У випадку параметричної ідентифікації структуру функції вважають відомою. Тоді задача ідентифікації зводиться лише до оцінювання невідомих параметрів. Вона розв’язується просто, якщо функція є лінійно-параметричною, тобто записується у такому вигляді:
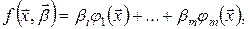 (7.2)
(7.2)
де 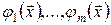 – відомі базисні функції;
– відомі базисні функції;  – невідомі параметри.
– невідомі параметри.
Очевидно, що в формулі (7.2) функцію можна задати деяким скінченим рядом, наприклад є лінійною чи квадратичною функцією, поліномом відомого степеня, рядом Фур’є та ін. Якщо функція у якийсь спосіб знайдена, то модель об’єкта вважається побудованою і для кожного спостереження можна, обчислити значення вихідної змінної

 , (7.3)
, (7.3)
тобто одержати вектор  і порівняти його з експериментальним вектором
і порівняти його з експериментальним вектором  . Модель узгоджується з даними експерименту тим краще чим менша різниця
. Модель узгоджується з даними експерименту тим краще чим менша різниця  . Унаслідок цього задачу параметричної ідентифікації формулюють так: “за даними експерименту , знаючи структуру (7.2) функції , оцінити її параметри за умовою
. Унаслідок цього задачу параметричної ідентифікації формулюють так: “за даними експерименту , знаючи структуру (7.2) функції , оцінити її параметри за умовою
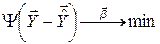 , (7.4)
, (7.4)
де  – деякий функціонал, що характеризує узгодження розрахункових та фактичних значень виходу.
– деякий функціонал, що характеризує узгодження розрахункових та фактичних значень виходу.
Задача ідентифікації тісно пов’язана із задачею планування експерименту. Для забезпечення найбільшої точності оцінок параметрів  при заданій кількості спостережень N необхідно певним чином сформувати та реалізувати в процесі експерименту матрицю значень вхідних змінних. Процедури формування цієї матриці на основі критеріїв, що забезпечують високу точність моделі або її параметрів розглядаються в рамках теорії планування оптимального експерименту. Як правило, до проведення експерименту, матрицю плану, що забезпечує певну точність оцінок параметрів, вдається знайти лише у випадку лінійно-параметричної функції виду (1.2). Таким чином задача планування оптимального експерименту формулюється так: “дано структуру лінійно-параметричної функції , область
при заданій кількості спостережень N необхідно певним чином сформувати та реалізувати в процесі експерименту матрицю значень вхідних змінних. Процедури формування цієї матриці на основі критеріїв, що забезпечують високу точність моделі або її параметрів розглядаються в рамках теорії планування оптимального експерименту. Як правило, до проведення експерименту, матрицю плану, що забезпечує певну точність оцінок параметрів, вдається знайти лише у випадку лінійно-параметричної функції виду (1.2). Таким чином задача планування оптимального експерименту формулюється так: “дано структуру лінійно-параметричної функції , область  можливої зміни вхідних змінних
можливої зміни вхідних змінних  , кількість спостережень N, необхідно знайти матрицю плану експерименту
, кількість спостережень N, необхідно знайти матрицю плану експерименту  таку, щоб забезпечити найбільшу точність прогнозування моделі або точність оцінок її параметрів ”.
таку, щоб забезпечити найбільшу точність прогнозування моделі або точність оцінок її параметрів ”.
Під прогнозуванням моделі в даному випадку розуміємо розрахунок значень виходу  згідно формул (7.2) та (7.3) за фіксованими векторами
згідно формул (7.2) та (7.3) за фіксованими векторами  поза експериментальними точками, але в межах області експерименту.
поза експериментальними точками, але в межах області експерименту.
У ряді випадків дослідник має достатньо точну, але складну для використання модель об’єкта, зображену у вигляді аналітично заданого виразу  , таблиці чи програмно. Остання ситуація виникає при імітаційному моделюванні складних об’єктів на ЕОМ, коли можна достатньо точно, але в межах похибок заокруглень обчислити відгук
, таблиці чи програмно. Остання ситуація виникає при імітаційному моделюванні складних об’єктів на ЕОМ, коли можна достатньо точно, але в межах похибок заокруглень обчислити відгук  на довільну комбінацію входів , тобто одержати таблицю . Такий спосіб моделювання об’єкта часто є єдино можливим, хоча й не завжди зручним для аналізу. За цих умов виникає задача наближення складної моделі об’єкта, заданої таблицею, більш простішою математичною моделлю у вигляді функції . Зауважимо, що дана задача є подібною до задачі ідентифікації структури моделі. При цьому якість наближення як і в задачі ідентифікації можна задати функціоналом (7.4). Спосіб задання умов наближення полягає у забезпечені функцією певного значення точності
на довільну комбінацію входів , тобто одержати таблицю . Такий спосіб моделювання об’єкта часто є єдино можливим, хоча й не завжди зручним для аналізу. За цих умов виникає задача наближення складної моделі об’єкта, заданої таблицею, більш простішою математичною моделлю у вигляді функції . Зауважимо, що дана задача є подібною до задачі ідентифікації структури моделі. При цьому якість наближення як і в задачі ідентифікації можна задати функціоналом (7.4). Спосіб задання умов наближення полягає у забезпечені функцією певного значення точності  для всіх табличних значень . В цьому випадку задача наближення розв’язується за умов:
для всіх табличних значень . В цьому випадку задача наближення розв’язується за умов: 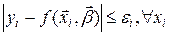 .
.
Очевидно, що така постановка задачі є реальною за умов одержання таблиці даних в результаті імітаційного моделювання на ЕОМ з відомими граничними похибками заокруглень  .
.
7.2. Особливості застосування стохастичного підходу
Для розв’язування розглянутих задач ідентифікації, планування експерименту та наближення складних моделей простішими, часто використовується метод найменших квадратів (МНК). В МНК за критерій узгодження експериментальних і розрахункових даних прийнята сума квадратів відхилень:
 .
.
За допомогою МНК при розв’язуванні задачі ідентифікації моделі у вигляді (7.2) оцінку вектора невідомих параметрів отримуємо за формулою:
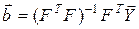 , (7.5)
, (7.5)
де
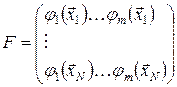 (7.6)
(7.6)
є матрицею значень базисних функцій моделі (7.2), розрахованих в точках експерименту, тобто на основі матриці .
Дослідження МНК-оцінок , або оцінок отриманих будь-яким іншим способом, проводиться на основі гіпотез про імовірнісну природу похибок в експериментальних даних, зокрема, методом регресійного аналізу. При проведенні регресійного аналізу розглядають певну модель невизначеності у вигляді похибки в даних. Найбільш вивченим є випадок адитивної випадкової похибки спостережень, такого вигляду:
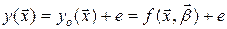 , (7.7)
, (7.7)
де  – істинне значення “виходу” об’єкта, задане лінійно-параметричною функцією (7.2);
– істинне значення “виходу” об’єкта, задане лінійно-параметричною функцією (7.2); 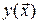 – значення виходу, що спостерігається, “змішане” з похибкою
– значення виходу, що спостерігається, “змішане” з похибкою  .
.
В класичному лінійному регресійному аналізі вважають, що похибка е в усіх дослідах експерименту має нормальний розподіл з нульовим середнім і незалежним значеннями в серіях дослідів, тобто

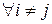 . (7.8)
. (7.8)
У формулі (7.8)  – означає математичне сподівання, а
– означає математичне сподівання, а  – дисперсію.
– дисперсію.
В літературі зустрічаються і менш жорсткі обмеження стосовно властивостей випадкової похибки e.
Якщо похибка задовольняє умови (7.7) та (7.8), то МНК-оцінка є ефективною і незміщеною оцінкою вектора і має нормальний розподіл з параметрами

 ,
,
де  – симетрична, розмірності (m x m) коваріаційна матриця оцінок , діагональні елементи якої визначають їхні дисперсії.
– симетрична, розмірності (m x m) коваріаційна матриця оцінок , діагональні елементи якої визначають їхні дисперсії.
Коваріаційна матриця залежить від матриці значень базових функцій  і, відповідно, від матриці експерименту Х. Це дозволяє вводити критерії планування оптимального експерименту за умовою мінімізації різних характеристик матриці
і, відповідно, від матриці експерименту Х. Це дозволяє вводити критерії планування оптимального експерименту за умовою мінімізації різних характеристик матриці  . Найбільш вживаними є критерії, пов’язані з визначником, слідом і максимальним числом цієї матриці, відповідно, наведеними у такому вигляді:
. Найбільш вживаними є критерії, пов’язані з визначником, слідом і максимальним числом цієї матриці, відповідно, наведеними у такому вигляді:
 (7.9)
(7.9)
Розглянуті критерії забезпечують характеристики точності оцінок параметрів моделі (7.2). Інші критерії планування експерименту безпосередньо стосуються точності прогнозування регресійної моделі і забезпечують мінімум середнього або максимального значення дисперсії прогнозування на області експерименту. Найбільш поширеними серед них є Q -та G -критерії оптимальності.
На сьогоднішній день задачі планування оптимальних регресійних експериментів є достатньо розробленими. Складено каталоги D -, А -, Е -, Q-, G- оптимальних планів для випадку, коли функція є поліном першого та другого степеня.
Найбільш значних результатів досягнуто при плануванні насичених (N=m) регресійних експериментів, як найчастіше практично застосовуваних і найменш затратних.
7.3. Основні етапи регресійного аналізу:
I.Формулювання гіпотез:
Гіпотеза 1. Залежність між вхідними і вихідними змінними статичної системи описується лінійно-параметричною функцією:
Гіпотеза 2. Відомі дані експерименту представляються у вигляді матриці входу вектора виходу, компоненти якого отримуються у відповідності з формулою  , при цьому похибка
, при цьому похибка  є випадковою, нормально розділеною величиною з нульовим математичним сподіванням
є випадковою, нормально розділеною величиною з нульовим математичним сподіванням  , з постійною дисперсією
, з постійною дисперсією  незалежними значеннями у всіх спостереженнях
незалежними значеннями у всіх спостереженнях  .
.
Основним завданням регресійного аналізу є оцінювання невідомих параметрів моделі  і дослідження прогнозних властивостей цієї моделі. Оцінки параметрів шукаються серед найкращих лінійних оцінок, тобто за такою формулою:
і дослідження прогнозних властивостей цієї моделі. Оцінки параметрів шукаються серед найкращих лінійних оцінок, тобто за такою формулою:
II. Знаходження оцінок параметрів моделі.
Цей етап може виконуватися із застосуванням методу найменших квадратів за умови виконання гіпотези 2. Отримані оцінки параметрів моделі повинні бути ефективними  , незміщеними
, незміщеними  .
.
III. Аналіз точності оцінок параметрів моделі.
Точність оцінок параметрів визначається коваріаційною матрицею  . Діагональні елементи цієї матриці визначають точність параметрів.
. Діагональні елементи цієї матриці визначають точність параметрів.
Геометричну інтерпретацію точності можна здійснити за допомогою довірчого еліпсоїда розсіювання
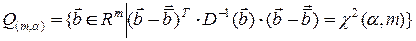 ,
,
де  – довірча імовірність.
– довірча імовірність.
Чим більші розміри еліпсоїда розсіювання, тим менша точність оцінок параметрів.
IV. Аналіз точності моделі.
Оцінка точності моделі проводиться за допомогою функції дисперсії похибки прогнозування на основі моделі:
 .
.
Якщо похибка розподілена по нормальному закону, то для оцінки точності можна використати довірчий коридор прогнозування регресійної моделі.  , де
, де 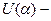 табличне значення нормованого нормального закону розподілу, яке залежить від довірчої ймовірності:
табличне значення нормованого нормального закону розподілу, яке залежить від довірчої ймовірності:  .
.
V. Перевірка прийнятих гіпотез.
Перевірка адекватності моделі: відповідність прийнятої структури моделі ступенню відображення властивостей системи. При цьому аналізується значущість параметрів моделі за критерієм Стьюдента та адекватності за критерієм Фішера.
Для перевірки гіпотез про адекватність моделі спочатку оцінюємо дисперсію адекватності
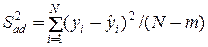 ,
,
де N – кількість спостережень;
m – кількість параметрів;
 – прогнозне значення виходу.
– прогнозне значення виходу.
Тоді оцінюємо дисперсію похибки в даних
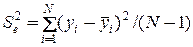 ,
,
де  – сподіване значення виходу.
– сподіване значення виходу.
Наведена формула справедлива за умови однорідності дисперсії на області експерименту.
Знаходимо відношення  і порівнюємо його з табличним значенням F (, N-m, m) F - розподілу. Якщо F (, N-m, m) > , то можемо із ймовірністю 1- стверджувати, що вибрана структура моделі є задовільною, а модель – адекватна.
і порівнюємо його з табличним значенням F (, N-m, m) F - розподілу. Якщо F (, N-m, m) > , то можемо із ймовірністю 1- стверджувати, що вибрана структура моделі є задовільною, а модель – адекватна.
При аналізі структури моделі використовують також критерій Стьюдента  , який дозволяє підтвердити із заданою імовірністю значущість параметру. При цьому, оцінки дисперсій параметрів
, який дозволяє підтвердити із заданою імовірністю значущість параметру. При цьому, оцінки дисперсій параметрів 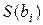 отримуємо з діагональних елементів коваріаційної матриці
отримуємо з діагональних елементів коваріаційної матриці 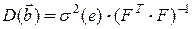 , а
, а  - знаходимо в таблиці значень розподілу Стьюдента.
- знаходимо в таблиці значень розподілу Стьюдента.
Для перевірки прийнятих стохастичних властивостей похибки в експериментальних даних (“нормальність”, “незалежність”) використовують відповідно критерій Пірсона та розраховують коваріаційну матрицю оцінок похибок 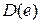 . Якщо гіпотеза про “нормальність”, або висунутий закон розподілу похибки не справджується, то неможливо розрахувати довірчий інтервал. У випадку, коли діагональні елементи коваріаційної матриці вибіркових оцінок похибок сильно відрізняються (неоднорідність дисперсії), чи поза діагональні елементи не близькі до нуля (порушення умови “незалежності” спостережень), то для оцінювання параметрів моделі необхідно використати узагальнений МНК:
. Якщо гіпотеза про “нормальність”, або висунутий закон розподілу похибки не справджується, то неможливо розрахувати довірчий інтервал. У випадку, коли діагональні елементи коваріаційної матриці вибіркових оцінок похибок сильно відрізняються (неоднорідність дисперсії), чи поза діагональні елементи не близькі до нуля (порушення умови “незалежності” спостережень), то для оцінювання параметрів моделі необхідно використати узагальнений МНК:
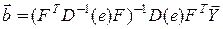 .
.
Незважаючи на практичну привабливість і наявність відповідного алгоритмічного і програмного забезпечення для реалізації стохастичних методів експериментальної ідентифікації моделей “вхід-вихід” статичних систем, побудованих на гіпотезах про імовірнісну природу похибок, достатньо часто їх застосування пов’язане з такими проблемами. По-перше для розрахунку достовірних оцінок статистичних характеристик об’єкта необхідні достатньо великі вибірки експериментальних даних, які не завжди можна отримати. По-друге існує клас об’єктів, коли припущення про імовірнісну природу, адитивність похибок в експериментальних даних не відповідає реальним властивостям об’єкта. В останньому випадку побудова працездатної математичної моделі на основі стохастичних методів взагалі не можлива.
Достатньо повний аналіз причин обмежень при застосуванні традиційної статистики наведено у працях Орлова О.І.
Про те, що природа не підлягає правилам традиційної імовірності висловлювався відомий вчений в теорії систем і управління Калман Р. У випадку імітаційного моделювання, чи отримання даних в процесі опитування експертів, наприклад, при побудові моделей нових систем, модель з випадковою похибкою не відповідає дійсності. Дані імітаційного моделювання спотворені невипадковими похибками заокруглень, а дані опитування експертів задають інтервали можливих значень показників. Під час повторних опитувань експертів отримаємо однакові, але неточні результати. Аналогічно, при повторному імітаційному моделюванні, при незмінному наборі вхідних даних результат обчислень буде таким самим, хоча й неточним за рахунок похибок заокруглень.

