




Процесс принятия управленческих решений является важнейшим элементом системы управления в любой компании. От обоснованности решений, от того, насколько полно при их выработке учитывается предыдущий опыт, текущее и прогнозируемое состояние дел на предприятии и во внешнем окружении, зависит, в конечном итоге, эффективность его функционирования и перспективы развития.
Управленческие решения могут приниматься с целью обеспечения устойчивого функционирования экономической или бизнес-системы в рамках заданных параметров либо с целью поиска новых возможностей роста и перспектив развития. Независимо от цели, управленческие решения должны приниматься только на основе глубоких, достоверных, нетривиальных знаний о предметной области. Важную роль в данном процессе играет интеллектуальный капитал организации – совокупность знаний, умений и опыта ее работников. Он является общепризнанным фактором конкурентного преимущества, особенно в условиях современной постиндустриальной экономики – экономики знаний. Поэтому современные, динамично развивающиеся компании уделяют огромное внимание развитию интеллектуального капитала и вкладывают в его формирование значительные средства, постоянно ищут формы и методы его использования для совершенствования процессов управления.
Однако процесс создания и накопления интеллектуального капитала в современных условиях ‒ весьма непростое дело. Одной из причин этого является высокая динамика экономической и бизнес-среды: стремительно развиваются технологии, появляются новые товары и услуги, формируются и распадаются рынки, разрабатываются новые формы ведения бизнеса. Поэтому текущие знания, умения и опыт, еще вчера позволяющие добиться успеха, просто устаревают и становятся бесполезными. Второй фактор – высокая сложность современных экономических и бизнес-процессов, которые описываются десятками и сотнями параметров, находящимися в очень сложной взаимосвязи. Поэтому, чтобы разобраться в текущих тенденциях, выявить важные закономерности и принять на их основе своевременное и обоснованное управленческое решение, требуется не только использование человеческого интеллектуального капитала, но и новейших достижений IT-технологий.
Важной особенностью современной бизнес-среды является смещение центров принятия управленческих решений от высших эшелонов менеджмента компаний на уровень специалистов, непосредственно интегрированных в бизнес-процессы. Это связано с наличием у последних более точной и актуальной информации о текущих проблемах, а также требованиями к оперативности принимаемых решений. В результате в процесс «добычи» знаний, необходимых для принятия управленческих решений, вовлекается огромное количество специалистов с самым разнообразным уровнем и профилем образования, знанием компьютера и программного обеспечения. Это создает для компаний, разработчиков компьютерных систем, ориентированных на поддержку принятия решений, огромный рынок клиентов в самых разнообразных областях экономики и бизнеса.
Анализ данного рынка показывает, что все программные продукты, реализующие те или иные аспекты поддержки принятия управленческих решений, можно отнести к двум направлениям:
– классические системы поддержки принятия решений, строящиеся на основе инженерии знаний, экспертные системы;
– системы Knowledge Discovery (открытие знаний), ориентированные на поиск знаний в данных, накапливающихся в БД компаний в процессе электронной регистрации ими фактов хозяйственной деятельности.
Системы 1-го типа реализуют онтологический подход – формализация области знаний с помощью некоторой концептуальной схемы. Формализованные знания организуются в базу знаний (БЗ), откуда с помощью подсистемы логического вывода и интеллектуального интерфейса предоставляются пользователю.
Системы 2-го типа реализуют аналитический подход, в основе которого лежит построение компьютерных моделей, отражающих зависимости, закономерности и структуры в данных, интерпретация и осмысление которых человеком, позволяют ему генерировать новые знания о предметной области, описываемой этими данными.
Таким образом, главным отличием онтологического подхода к поиску знаний от аналитического, заключается в самом представлении знания. Первый предполагает, что знания существуют отдельно от сознания человека и представляют собой совокупность специально организованной информации и правил вывода. В рамках аналитического подхода знание рассматривается как субъективный образ реальности, отражаемый в сознании человека в виде понятий и представлений. Тогда задача заключается в обнаружении в данных, описывающих предметную область, зависимости, закономерности и структуры, интерпретация которых специалистом позволяет сформировать понятия, выводы и суждения, необходимые для принятия решений.
В условиях высокой оснащенности компаний электронными средствами регистрации, сбора и хранения данных, отражающих их деятельность, все большую актуальность приобретает аналитический подход к организации поддержки принятия решений, т.е. стремление получить знания «от данных».
Кроме этого, внедрение систем 1-го типа на уровне пользователей, непосредственно интегрированных в бизнес-процессы, сталкивается с большими проблемами, основными из которых являются:
– высокая трудоемкость формирования базы знаний, в процессе которого эксперт и инженер по знаниям вручную описывают и вводят в нее факты предметной области, разрабатывают средства логического вывода. В условиях высокой сложности и динамики современной бизнес-среды формирование такой базы данных может продлиться неопределенно долго;
– базы знаний обычно являются предметно-ориентированными и трудно актуализируются;
– работая с экспертной системой, пользователь, фактически, применяет формализованные знания экспертов, которые уже не являются новыми, что во многом обесценивает их роль в получении конкурентных преимуществ.
Аналитический подход к проблеме поиска знаний «от данных» начал развиваться в рамках математической и прикладной статистики в части методов восстановления зависимостей из выборочных данных. Поэтому одним из главных инструментов исследования стали специализированные статистические пакеты (SAS, SPSS, Statistical, SYSTAT, Minitab, STADIA и др.). Работа с ними не вызывает проблем до тех пор, пока использующие их специалисты имеют соответствующую подготовку, решаемые задачи хорошо формализованы, а анализируемые данные содержатся в относительно небольших локальных базах данных.
Однако, начиная примерно с середины 90-х г. XX века, на предприятиях и в организациях стали накапливаться огромные массивы информации, аналитическая обработка которой потенциально позволяла получить новые практически полезные знания. Использование методов прикладной статистики и статистических пакетов столкнулось с рядом проблем, основными из которых являлись:
– очень большие объемы данных, разнообразие их представлений, форматов и происхождения, которые требовали включения в процедуру аналитической обработки мощного модуля управления данными, в котором бы осуществлялся доступ к источникам данных, их консолидация и предобработка;
– вовлечение в процессы принятия управленческих решений большого числа лиц, не имеющих достаточного уровня знаний в области математики и статистики;
– некоторые статистические подходы оказались плохо приспособлены для работы с «живыми» данными: мало реалистичные предположения о независимости и нормальности признаков, стремление навязать вероятностную сущность вполне детерминированным явлениям, оперирование фиктивными величинами типа средних, плохое отражение причинно-следственных связей,
все это ограничивало возможности использования методов прикладной статистики для извлечения знаний из реальных данных. Между тем руководителей компаний, вкладывающих значительные средства в развитие IT-служб, в большей степени интересовала не математическая корректность и достоверность результатов, а практическая значимость сделанных выводов и суждений. В тех случаях, когда возможности статистических подходов не позволяли решить поставленную задачу, исследователи стали привлекать методы из других научных областей, таких, как базы данных, теория информации, искусственный интеллект, распознавание образов и машинное обучение, комплексировать их. В результате сформировалось направление, получившее название Data Mining (раскопка, разработка данных) или интеллектуальный анализ данных (ИАД), в котором статистические методы в основном играют вспомогательную роль, и используются только на некоторых этапах процесса анализа. Ядром ИАД являются методы машинного обучения (МО) – нейронные сети, деревья решений, самоорганизующиеся карты признаков, ассоциативные правила и др., которые позволяют автоматически, с минимальным вмешательством пользователя извлекать из данных зависимости и закономерности и визуализировать в наиболее удобном для восприятия и интерпретации виде.
В настоящее время ИАД можно рассматривать как своего рода мэйнстрим в области информационных технологий поиска знаний. В различных предметных областях формируются концепции бизнес-анализа, использующие интеллектуальные модели для поддержки принятия решений. Типичными примерами таких концепций являются точное земледелие в агробизнесе и анализ рыночной корзины в розничной торговле. Концепция точного земледелия основана на том, что земельные площади, используемые под те или иные культуры, не являются однородными по своим агрохимическим и агрофизическим свойствам, степени увлажненности и т.д. Следовательно, норма внесения удобрений, средств защиты растений и орошения, должна подбираться индивидуально для каждого участка. Это делается на основе анализа данных, полученных с помощью навигационных систем (GPS, GLONASS), ведомостей агрохимического и агрофизического обследования почв, истории урожайности. Результатами являются экономия ресурсов, повышение урожайности за счет целевого применения удобрений, пестицидов и орошения; защита окружающей среды за счет ограничения применения нитратов, ядохимикатов, забора воды из водоемов и т.д. Анализ рыночной корзины, использующий ассоциативные правила, позволяет обнаруживать группы товаров, которые чаще всего покупаются совместно. Такие исследования позволяют выявлять поведенческие шаблоны клиентов, которые можно использовать для более полного удовлетворения спроса, стимулирования продаж, оптимизации ассортимента товаров. Аналогичные решения на основе методов ИАД активно разрабатываются и внедряются в следующих областях экономики и бизнеса:
– в потребительском кредитовании – для оценки кредитоспособности клиентов (кредитный скоринг), разработки новых кредитных продуктов, выявления мошеннических действий с кредитными картами и др.;
– в страховании – для анализа клиентской базы с целью разработки новых продуктов и привлечения клиентов, выявления мошенничеств со страховыми выплатами;
– в телекоммуникациях – анализ клиентской базы с целью определения лояльности клиентов, выработке мер по удержанию имеющихся и привлечению новых клиентов, разработки новых конкурентоспособных продуктов, обнаружения мошеннических действий;
– в медицине и здравоохранении – диагностика заболеваний, анализ эпидемиологической обстановки;
– в науке – определение наиболее достойных претендентов на получение грантов научных фондов;
– в поиске залежей полезных ископаемых, на основе данных геологоразведки, аэрофотосъемки и космических снимков.
Десятки IT-компаний во всем мире активно разрабатывают и продвигают собственные решения в области ИАД и бизнес-аналитики. Среди них как признанные лидеры: Microsoft, IBM, Oracle, SAS Institute, SPSS, Silicon Graphics, StatSoft, так и менее известные Angross Software, Neuro Solution, PolyAnalyst, BaseGroup Labs и др. Предлагаются как мощные платформы бизнес-аналитики, позволяющие создавать завершенные аналитические проекты (SAS Interprise Miner, IBM Intelligent Miner, MineSet, Knowledge Studio, Microsoft SQL Server Analysis Services, SPSS Predictive Analytics Software Modeler, Deductor Enterprise, PolyAnalyst), так и программы, ориентированные на конкретную предметную область (FinMetrics, Estard Data Miner). Стоимость ИАД-приложений варьируется от нескольких тысяч до нескольких десятков тысяч USD.
Существуют и бесплатные продукты, разрабатываемые и поддерживаемые крупными университетами и исследовательскими центрами, например Weka (университет Уайкато, Новая Зеландия), Orange (университет Любляны, Словения), RapidMiner (технический университет Дортмунда) и др.
Российская компания BaseGroup Labs (www.basegroup.ru), разработчик платформы Deductor, выпускает бесплатную учебную версию Deductor Academic, которая используется десятками вузов России и ближнего зару- бежья в учебном процессе.
Как современное направление информационных технологий ИАД не предписывает использования каких-либо конкретных алгоритмов и методов обработки данных при решении тех или иных задач анализа. Оно лишь определяет методологию поиска знаний в массивах структурированных данных, порядок действий аналитика, который позволит сделать поиск знаний наиболее эффективным. Поэтому, несмотря на то, что аналитические системы могут быть предметно-ориентированными и содержать различные средства обработки данных, их структура содержит примерно одни и те же элементы, представленные на рис. 6.1.
Анализируемые данные расположены в различных источниках, таких, как системы оперативной регистрации данных – кассовые терминалы супермаркетов, вокзалов и аэропортов; учетные системы (1С:Предприятие), офисные приложения, базы данных, файлы из Интернета и других внешних источников. Поэтому аналитическая система (АС) должна содержать средства импорта, конвертирования и интегрирования данных из файлов самых различных типов и форматов. Данная задача решается с помощью модуля импорта.
Наиболее продвинутые АС используют специализированные хранилища данных (ХД), которые отличаются от обычных баз данных и других источников тем, что адоптированы именно для целей и задач ИАД. Они автоматически обеспечивают интегрирование данных из различных источников, поддерживают их целостность, неизменчивость и непротиворечивость, а также хронологию и высокую скорость доступа к данным.
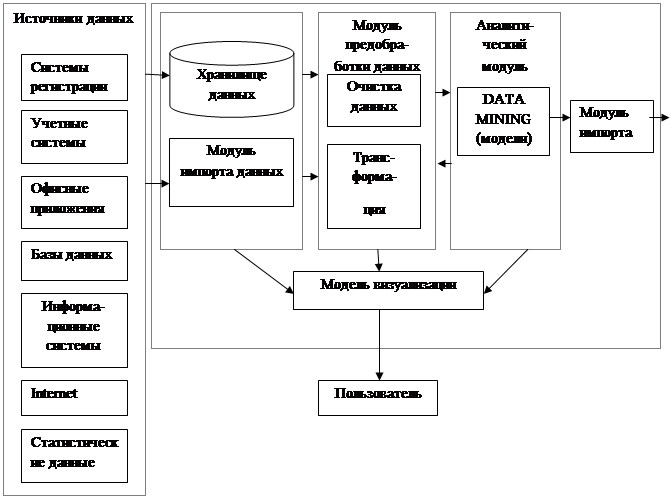
Рис. 6.1. Обобщенная структура типичного аналитического приложения
После загрузки данных в АС, к ним необходимо применить процедуру предобработки с целью подготовки к анализу. Такую предобработку можно разделить на два этапа – очистку и трансформацию. Очистка позволяет исключить из данных факторы, мешающие их корректной обработке аналитическими алгоритмами: аномальные и фиктивные значения, пропуски, противоречия, дубликаты, шумы и т.д. Поскольку качество данных очень важно с точки зрения достоверности результатов анализа, данному вопросу уделяется очень большое внимание при практической реализации проектов ИАД.
Трансформация данных выполняется для их согласования (типов, фор- матов, диапазонов и т.д.) с применяемыми аналитическими алгоритмами. Она включает такие операции, как квантование, нормирование, преобразование форматов и типов данных, кодирование, слияние, группировку и т.д. Если исходные данные полностью соответствуют заданным критериям качества, то этап предобработки может быть пропущен и данные могут анализироваться в том виде, в каком они были загружены. Однако на практике такая ситуация встречается крайне редко.
После того, как данные подготовлены, к ним применяются различные алгоритмы анализа. Часть из них относится к математической статистике (метод главных компонент, байесовская классификация, линейная и логистическая регрессия и др.), а часть – к технологиям машинного обучения (нейронные сети, деревья решений, карты Кохонена, ассоциативные правила и др.). Именно последние традиционно считаются аналитическим ядром ИАД, поскольку позволяют в автоматическом режиме извлекать из данных зависимости, закономерности и структуры, интерпретация которых и позволяет генерировать знания. Результатом работы аналитического алгоритма является модель, отражающая зависимость, закономерность или структуру, содержащуюся в исходном множестве данных. После этого модель верифицируется, сохраняется и может быть использована для обработки новых, ранее не известных наблюдений. В процессе анализа важно не только получить значимые и достоверные результаты, но и представить обнаруженные зависимости и закономерности в наиболее удобной и интерпретируемой форме. Для этого в АС предусмотрен модуль визуализации, с помощью которого пользователь формирует наиболее информативное представление для определенного вида данных (таблицы, графики, диаграммы, многомерные визуализаторы, визуализаторы связей и т.д.). Результаты, полученные в процессе анализа, могут быть не только представлены пользователю с помощью средств визуализации, но и экспортированы в файлы других приложений – электронные таблицы, базы данных, текстовые документы и другие форматы.

