




В качестве простого примера построения модели методом наименьших квадратов рассмотрим задачу восстановления математического описания некоторого процесса по результатам эксперимента.
Предполагается, что процесс описывается одномерным уравнением 2-го порядка
W = a 0 + a 1 x + a 2 x 2, 0 £ x £ 6.
Считаем, что величина х измеряется точно, а W – с ошибкой e, имеющей нормальное распределение с нулевым математическим ожиданием и единичной дисперсией
М (e) = 0, s2(e) = 1.
Выборка десяти случайных пар (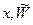 ) представлена в табл. 3.1 в графах 2 и 3.
) представлена в табл. 3.1 в графах 2 и 3.
Таблица 3.1
| № | x | 
| Wm | e |
| 4,8608 4,2396 2,7792 0,5988 3,2136 4,5156 5,9340 1,5852 4,4880 4,0932 | 9,28 9,40 7,88 1,86 7,77 8,73 8,33 5,16 7,28 9,22 | 8,848 8,821 7,460 2,039 8,056 8,874 8,118 4,994 8,872 8,767 | 0,432 0,579 0,420 -0,179 -0,286 -0,144 0,212 0,166 -1,592 0,453 |
Метод наименьших квадратов заключается в том, что неизвестные (искомые) коэффициенты а0 , а1 , а2 должны минимизировать функцию, представляющую собой сумму квадратов невязок ej:
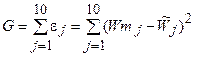 .
.
Минимум некоторой функции, как известно, находится в точке 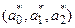 , где все частные производные этой функции по переменным а 0, а 1, а 2равны нулю.
, где все частные производные этой функции по переменным а 0, а 1, а 2равны нулю.
Для определения частных производных, распишем функцию G через ее предполагаемый вид:
 .
.
Возьмем от функции G производные по а 0, а 1, а 2:
 ;
;
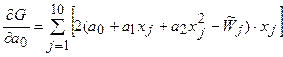 ;
;
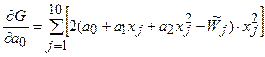 .
.
Приравняв эти выражения к нулю и произведя некоторые преобразования, получим систему линейных алгебраических уравнений третьего порядка с тремя неизвестными, коэффициенты которой вычисляются по известным данным из табл. 3.1:

Решая полученную систему, получим а 0 = –0,161; а 1 = 3,929; а 2 = –0,427.
Таким образом, математическая модель будет иметь вид
Wm = –0,161 + 3,929 x –0,427 x 2. (3.2)
Проверим адекватность модели методом Фишера. Для этого заполним четвертый и пятый столбцы таблицы 3.1, подставляя в математическую модель (3.2) и затем в формулу (3.1) значения xj из первого столбца.
Определим число степеней свободы системы по формуле
fs = n – m – 1,
где n = 10 – количество экспериментальных точек; m = 3 – количество неизвестных коэффициентов. То есть fs = 6.
Выборочная дисперсия вычисляется по формуле
 .
.
Критерий Фишера вычисляется по формуле
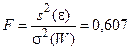 .
.
По статистическим таблицам при 5%-м уровне риска (a = 0,05) находим пороговое значение критерия Фишера
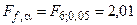 .
.
Так как полученное значение F меньше критического (порогового), гипотеза об адекватности модели реальному процессу принимается.
Контрольные вопросы к лекции 7
1. Что является исходным материалом при построении эмпирической модели?
2. Как используется физическая теория работы объекта при построении эмпирической модели?
3. Что при этом представляет собой объект идентификации?
4. Сформулируйте задачу идентификации.
5. Что такое уравнение регрессии?
6. С чего начинается процесс идентификации?
7. От чего зависит конкретная форма модели?
8. Перечислите причины проведения непланируемого эксперимента.
9. В чем заключается метод наименьших квадратов?
3.3. Статистические методы проверки адекватности
Лекция 8
математических моделей
Если имеются или могут быть получены необходимые и достоверные экспериментальные данные, для проверки адекватности моделей можно использовать методы математической статистики.
Математически задача проверки адекватности модели формулируется как задача проверки предположения о том, что значение отклика модели Wm отличается от реального отклика системы W не более чем на заданную величину e*:
 . (3.3)
. (3.3)
Однако, истинное значение отклика системы никогда неизвестно. Полученный в результате эксперимента отклик в силу неконтролируемого дрейфа системы, разброса характеристик ее элементов и, наконец, просто ошибок измерения представляет собой случайную величину, отличающуюся от W. Поэтому при сравнении результатов математического и физического экспериментов  будет получена совокупность случайных величин {e i }:
будет получена совокупность случайных величин {e i }: 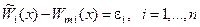 , среди которых могут оказаться как величины, удовлетворяющие условию (3.3), так и не удовлетворяющие ему.
, среди которых могут оказаться как величины, удовлетворяющие условию (3.3), так и не удовлетворяющие ему.
Можно ли считать, что полученные отклонения (e i > e*) объясняются случайными причинами или их наличие должно быть признано существенным, что приводит к отказу от проверяемой модели. Для решения этого вопроса на основе выборки случайных величин {e i } строят статистические критерии, по которым оценивают адекватность модели.
Гипотеза об адекватности модели действительности (гипотеза Н0) может быть сформулирована как предположение о том, что полученная совокупность {ei} не дает оснований отказаться от рассматриваемой модели. Иными словами, модель удовлетворяет заданной точности e*.
Альтернативная гипотеза Н 1 состоит в том, что модель не отвечает заданным требованиям (3.3) и, следовательно, должна быть отвергнута.
Так как выборка {e i } случайна, решение о выборе одной из гипотез Н 0 или Н 1 носит вероятностный характер. При этом может быть допущена ошибка первого рода, состоящая в отказе от правильной модели (принимается Н 1, когда верна Н 0), или ошибка второго рода, состоящая в принятии ошибочной модели (принимается Н 0, когда верна Н 1). Вероятность ошибки первого рода обозначают через a, второго рода – b. Принято называть a риском разработчика, b – риском потребителя. Разумеется, желательно минимизировать как a, так и b. Однако, при заданном объеме экспериментальной выборки уменьшение a влечет за собой увеличение b.
На практике a задается на определенном уровне (a = 0,05; 0,01; 0,005; 0,001), при этом в 100a% случаев правильная модель отвергается.
Величина 1– b характеризует вероятность отказа от ошибочной модели, называется мощностью критерия и является мерой его эффективности.
Выбор вероятностей ошибок a и b при проверке конкретной модели зависит от ответственности решений, принимаемых на основе моделирования.
Например, если модель предназначена для управления двигателем летательного аппарата, необходимо в первую очередь минимизировать b, так как в данном случае принятие неверной модели, а значит, возможность ошибочных решений при управлении представляет больший вред, чем отказ от правильной модели.
Для оценки гипотезы об адекватности модели существует несколько критериев:
1) Критерий согласия c2 Пирсона.
2) Критерий Смирнова-Колмогорова.
3) Критерий Фишера и др.
При использовании критерия c2 проверке подлежит гипотеза о том, что рассматриваемая модель адекватна исследуемой системе с вероятностью р (например, р = 0,95). Это значит, что при n независимых испытаниях np значений e i должно удовлетворять условию (3.3) и лишь в (1– р) п случаях это условие может быть нарушено.
В результате случайного эксперимента для этих событий будут получены частоты n1 и n2: n1» рп; n2 » (1– р) п; (n1 + n2 = п).
Частоты n1 и n2 отличаются от точных вероятностных оценок или из-за несоответствия модели действительности (заданная вероятность р не соблюдается), или из-за случайных отклонений.
Для оценки предположения о том, что отклонения n1 и n2 от соответствующих вероятностей случайны, строится функция
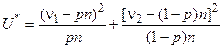 ,
,
представляющая собой сумму квадратов отклонений, нормированных на соответствующие вероятности.
Полученное значение U * сравнивается с табличным значением при заданном уровне риска a. Если U * превышает пороговое значение  , модель должна быть отвергнута, и принимается гипотеза Н 1. Если U *£ , экспериментальные данные не противоречат гипотезе об адекватности модели, и принимается гипотеза Н 0.
, модель должна быть отвергнута, и принимается гипотеза Н 1. Если U *£ , экспериментальные данные не противоречат гипотезе об адекватности модели, и принимается гипотеза Н 0.
Необходимым условием использования критерия c2 является многочисленность экспериментальных данных (не меньше 20).
Критерий Смирнова-Колмогорова основан на максимальном значении отклонений
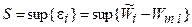 .
.
Для заданной экспериментальной выборки строится вспомогательная функция
 ,
,
которая сравнивается с пороговым значением l n ,a, определенным по таблицам распределения функции Смирнова-Колмогорова.
При  модель должна быть отвергнута, а при
модель должна быть отвергнута, а при 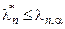 экспериментальные данные не противоречат гипотезе об адекватности модели.
экспериментальные данные не противоречат гипотезе об адекватности модели.
Критерий Смирнова-Колмогорова целесообразно использовать при относительно малых выборках, когда критерий c2 оказывается неэффективным.
Критерий Фишера осуществляется путем анализа дисперсий. Если дисперсия, характеризующая ошибку эксперимента s2(W), известна, вычисляется выборочная дисперсия S 2(e) и составляется F -отношение:
 .
.
Полученную величину F -отношения сравнивают с пороговым значением критерия Фишера Ff s ,¥, a при заданном уровне риска a.
При Ff s ,¥ £ Ff s ,¥, a полученная величина S 2(e) может быть объяснена случайным разбросом экспериментальных данных и, следовательно, нет оснований для отказа от проверяемой модели.
Если Ff s ,¥ > Ff s ,¥, a, полученное расхождение результатов моделирования и экспериментальных данных знáчимо и, следовательно, модель должна быть отвергнута как недостаточно точная.
Контрольные вопросы к лекции 8
1. Сформулируйте задачу проверки адекватности модели.
2. Что означает понятие «адекватность математической модели»?
3. В чем заключается ошибка первого рода?
4. В чем заключается ошибка второго рода?
5. Какие критерии проверки адекватности математической модели Вы знаете?
6. Охарактеризуйте каждый из этих критериев.
3.4. Идентификация параметров математической модели
Лекция 9
силы резания токарной операции
Построим математическую модель силы резания при обработке круглой детали на токарном станке (Рис. 3.6).
Сила резания Р описывается математической моделью в виде позинома
P = C S a V b t g, (3.4)
где S – продольная подача; V – скорость резания; t – глубина резания; С, a, b, g – неизвестные параметры.
Формула (3.4) является справочной. Для определения неизвестных параметров воспользуемся методом наименьших квадратов.
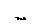
 Пусть проведено n экспериментов, результаты которых сведены в таблицу 3.2.
Пусть проведено n экспериментов, результаты которых сведены в таблицу 3.2.
Таблица 3.2
| № | S (мм/об) | V (мм/с) | t (мм) | P (Кг) |
   2
n 2
n
| S 1 S 2 Sn | V 1 V 2 Vn | t 1 t 2 tn | P 1 P 2 Pn |
Для упрощения решения поставленной задачи прологарифмируем выражение (3.4):
 .
.
Введем обозначения 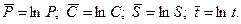
Тогда формула (3.4) преобразуется к линейному виду:
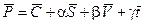 . (3.5)
. (3.5)
Метод наименьших квадратов сведется к минимизации функции
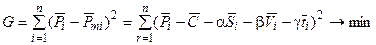 ,
,
где 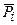 – логарифмы экспериментальных значений силы резания, взятых из табл. 3.2;
– логарифмы экспериментальных значений силы резания, взятых из табл. 3.2;
 – логарифмы силы резания, предсказанные с помощью математической модели (3.5),
– логарифмы силы резания, предсказанные с помощью математической модели (3.5), 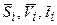 – логарифмы экспериментальных значений подачи, скорости и глубины резания, взятых из той же табл. (3.2),
– логарифмы экспериментальных значений подачи, скорости и глубины резания, взятых из той же табл. (3.2), 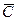 – логарифм неизвестного параметра С.
– логарифм неизвестного параметра С.
Возьмем производные от функции G по  и приравняем их к нулю:
и приравняем их к нулю:


Разделим обе части уравнений на –2; вынесем , a, b, g за знак суммы; перенесем члены, не зависящие от , a, b, g, в правую часть:
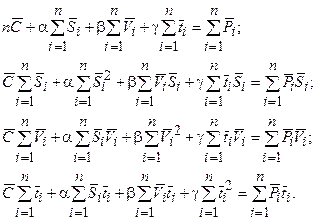 (3.6)
(3.6)
Получили систему линейных алгебраических уравнений четвертого порядка, коэффициентами которой являются суммы произведений логарифмов экспериментальных данных. Решив полученную систему, найдем искомые значения коэффициентов , a, b, g линейной модели (3.5).
Для определения параметров исходной модели (3.4) необходимо для коэффициента С (только для него) проделать операцию, обратную логарифмированию – потенцирование: С = 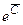 . Коэффициенты a, b, g получаются непосредственно из решения системы (3.6).
. Коэффициенты a, b, g получаются непосредственно из решения системы (3.6).
Если в распоряжении исследователя имеются экспериментальные данные, для проверки адекватности математической модели действительности можно использовать методы математической статистики. Рассматриваемый ниже метод пригоден при изучении любых математических моделей. Однако конкретный анализ проводится на примере построенной модели силы резания при точении с помощью критерия согласия c2, предложенного Пирсоном.
Гипотеза Н 0 формулируется как предположение о том, что отклонение e экспериментальных данных от значений, предсказанных моделью (3.4), с вероятностью р (доверительная вероятность) укладываются в некоторый толерантный интервал ±e*. Если это предположение правильно, то в толерантный интервал (Р ± e*) должно укладываться np отклонений e i = | Рi – Рmi |. Вне толерантного интервала должно оказаться (1– p) n отклонений. Для ограниченной случайной выборки из n наблюдений эти события будут наблюдаться с частотой n1 и n2 , лишь приближенно совпадающие с соответствующими вероятностями:
n1 » pn; n2 » (1– p)n; n1 + n2 = n.
Необходимо установить, можно ли объяснить эти отклонения случайными причинами (в этом случае можно принять гипотезу Н 0) или же они не случайны – статистически значимы (в этом случае нужно принять альтернативную гипотезу Н 1).
Для этого вычисляется некоторая величина U, называемая статистикой:
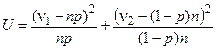 .
.
Эту величину нужно сравнить с пороговым значением c2-критерия (c21,a) при принятом уровне риска a. Если U £ c21,a, наблюдаемые отклонения частот от соответствующих вероятностей можно объяснить случайностью и нет оснований для отказа от нуль-гипотезы Н 0. Если U > c21,a, то или произошло маловероятное событие (1– р), или наблюдаемые отклонения не случайны. В этом случае принимается гипотеза Н 1.
Вывод о правильности гипотезы Н 1, вообще говоря, не требует безоговорочного отказа от проверяемой модели:
1) Можно изменить исходные предположения с тем, чтобы увеличить толерантный интервал ±e* или уменьшить доверительную вероятность р. При этом умéньшатся отклонения n1 и n2 от соответствующих вероятностей, и проверка может привести к принятию гипотезы Н 0. В этом случае моделью можно пользоваться, но нужно признать, что ее точность оказалась ниже, чем первоначально предполагалось.
2) Можно уменьшить уровень риска a (то есть вероятность отказа от правильной модели в результате неудачного эксперимента). Это приводит к увеличению порогового значения c21,a. Это, в свою очередь, может изменить оценку значения U. Однако нужно помнить, что при этом увеличивается риск признать правильной ошибочную модель.
3) Можно потребовать увеличения объема выборки, что, разумеется, приведет к увеличению точности оценки модели и уменьшению риска ошибок.
При проверке адекватности моделей действительности всегда рассматривается случай, когда за пределами толерантного интервала оказалось больше точек, чем ожидалось (n1 < pn; n2 > (1– pn) n). В противном случае опасений за точность модели не возникает, однако можно предположить, что величина толерантного интервала задана необоснованно большой. Если в результате проверки по критерию c2 в этом случае будет получена величина U > c21,a, то завышение толерантного интервала (или занижение доверительной вероятности р) статистически значимо, и необходимо уменьшить e* или увеличить р.
В обоих случаях нужно признать, что модель оказалась точнее, чем ожидалось.
Контрольные вопросы к лекции 9
1. Приведите общий вид математической модели силы резания при точении.
2. Как привести модель, заданную в виде позинома, к линейному виду?
3. Каким методом найдены параметры линейной модели?
4. В чем заключается этот метод?
5. Как перейти от линейной модели к позиному?
6. Сформулируйте нуль-гипотезу проверки построенной модели на адекватность.
7. Что такое доверительная вероятность?
8. Перечислите меры, которые можно применить в случае неадекватности построенной математической модели.
9. В каком случае можно не проверять модель на адекватность?
3.5. Выбор оптимальной эмпирической модели
Лекция 10
Принцип наименьших квадратов позволяет найти наилучшую модель идентификации для исследуемой экспериментальной выборки с заданным уравнением регрессии вида
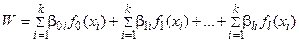 .
.
Если имеются достаточно веские основания для выбора формы этого уравнения, никаких проблем не возникает. Однако, в большинстве случаев конкретная форма модели заранее неизвестна и может, вообще говоря, быть различной.
На первый взгляд может показаться, что более сложная модель (увеличение степени полинома) всегда обеспечивает получение бóльшей точности. На самом деле это не так. При переходе к полиномам более высокой степени можно, конечно, получить лучшее согласие регрессионной кривой с экспериментальными данными. Для m = n это согласие будет абсолютным, но при этом получится худшее согласие с истинным характером процесса W (x). Дело в том, что экспериментальные данные представляют собой случайные величины и содержат лишь ограниченную информацию о характере W (x). Увеличение степени полинома целесообразно лишь до тех пор, пока из экспериментальной выборки извлекается надежная информация. Таким образом, возникает проблема выбора формы модели.
Подход к решению этой проблемы основан на статистическом исследовании уравнений регрессии.
1) Метод всех возможных регрессий основан на последовательном изучении всех возможных моделей (m < n), из которых отбирается лучшая модель.
Метод представляется мало пригодным для анализа сложных систем, так как отличается высокой трудоемкостью.
2) Метод исключения предполагает исследование наиболее полной (в пределах разумного) модели и последовательную проверку на значимость всех ее членов. При этом для каждого из членов модели вычисляется величина критерия Фишера F. На основе полученного множества { Fi } выбирается член уравнения регрессии, соответствующий минимальному значению критерия Fi. Если это минимальное значение меньше критического при выбранном уровне риска (Fi < F кр a), то соответствующий член исключается из регрессионного уравнения как несущественный, после чего все коэффициенты регрессии пересчитываются заново и вновь осуществляется проверка их значимости.
Если Fi > F кр a, то все члены модели существенны и уравнение регрессии остается в первоначальном виде. Однако, если это произошло уже на первом шаге исследования, стóит рассмотреть целесообразность усложнения первоначальной модели.
Трудоемкость этого метода меньше, чем метода всех возможных регрессий.
3) Метод включений по существу противоположен методу исключений и предусматривает последовательное включение в модель новых членов с проверкой их статистической значимости.
Трудоемкость этого метода существенно меньше трудоемкости рассмотренных выше методов.
Существуют и некоторые другие методы подбора оптимального уравнения регрессии.
Общим недостатком всех рассмотренных ранее методов является использование для оценки модели того же экспериментального материала, на основе которого эта модель построена.
4) Иной подход основан на использовании регуляризации. При этом подходе все экспериментальные данные разбиваются на две части: обучающую (n 1) и проверочную (n 2). Первая из них используется для определения коэффициентов регрессии модели, вторая – для оценки модели в целом.
Оптимальные по этому подходу модели мало чувствительны к небольшим изменениям исходных данных.
Число точек обучающей последовательности должно быть, по крайней мере, на единицу больше числа коэффициентов регрессии (n 1 > m +1). Для повышения достоверности результатов этот запас должен быть существенно увеличен (n 1 ³ (2…3) m). Проверочная последовательность должна включать в себя хотя бы одну точку.
В ряде случаев в качестве критерия регуляризации удобно использовать критерий несмещенности, обеспечивающий наименьшее изменение модели при изменении состава обучающей последовательности. При этом весь экспериментальный массив разбивается на две одинаковые по величине последовательности (n 1 = n 2), каждая из которых поочередно используется в качестве обучающей. В результате их использования определяются две независимые, одинаковые по форме модели 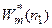 и
и 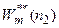 . Оптимальная модель ищется по всем точкам выборки:
. Оптимальная модель ищется по всем точкам выборки:
Критерий регуляризации всегда имеет четко выраженный минимум, что обеспечивает объективное выделение модели оптимальной сложности.

