




Наведені вище результати мають місце, якщо модель (2.3) є адекватною, тобто якщо спостережувана величина y насправді задовольняє рівності (2.3). Вичерпним чином перевірити виконання цього у більшості випадків неможливо. Проте цілком можливо перевірити, відповідають чи ні, висновки, що зроблені на основі припущення про виконання (2.3), поведінці реальних даних. Можуть досліджуватися різні аспекти такої відповідності. Кожне таке дослідження можна називати перевіркою моделі на адекватність. У зазначеному напрямку часто перевіряється достатня близькість оцінок дисперсії випадкової складової спостережень, що одержано, з одного боку, з застосуванням моделі (2.3), а з іншого — незалежним від постульованої моделі способом.
Розглянемо вказаний метод перевірки адекватності більш детально. Одразу зауважимо, що для його реалізації хоча б одній з точок {xj} потрібно мати більш ніж одне спостереження.
Нехай x 1, x 2,…, xn — точки спостережень, n > 1. Всі ці точки вважаються різними. Припустимо, що при x = xi спостерігалися значення yi 1, yi 2,…, yi  . Розглянемо середні арифметичні залежної змінної в кожній точці спостережень, тобто величини
. Розглянемо середні арифметичні залежної змінної в кожній точці спостережень, тобто величини
 , i = 1,2,…, n. (4.20)
, i = 1,2,…, n. (4.20)
Визначимо також величини
si 2 =  , i = 1,2,…, n. (4.21)
, i = 1,2,…, n. (4.21)
Якщо дисперсії спостережень однакові у всіх точках (дорівнюють σ 2), то як відомо з попереднього (теорема про 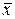 , s 2 при теоретичному нормальному розподілі), має місце співвідношення
, s 2 при теоретичному нормальному розподілі), має місце співвідношення
 si 2 Îc2(mi – 1), (4.22)
si 2 Îc2(mi – 1), (4.22)
(тобто ліва частина (4.22) розподілена за законом c2-квадрат з mi – 1 степенями волі.) Звідси випливає, що
 / σ 2 Îc2(N – n), (4.23)
/ σ 2 Îc2(N – n), (4.23)
де N = m 1 + … + m n. Таким чином (врахувати зауваження 4.2.2), величина
S 22 =  (4.24)
(4.24)
є незсуненою оцінкою величини σ 2, причому цей факт не залежить від справедливості чи несправедливості гіпотези про адекватність моделі (2.3).
Покладемо
S 21 =  , (4.25)
, (4.25)
4.3.1. Твердження. В разі виконання рівності (2.3) величини S 21 та S 22 є незалежними одна від одної, причому обидві вони є незсуненими оцінками величини σ 2.
Дійсно, у будь-якому разі має місце рівність (див. вправу 4.3.2)
 =
= 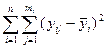 +
+  . (4.26)
. (4.26)
З теореми 4.2.1 випливає, що величина у лівій частині (4.26), поділена на σ 2, має розподіл c2 з N – 2 степенями волі, де N = m 1 + … + mn. Позначимо першу і другу суму з правої частини (4.26) через Z2 та Z1 відповідно. Щойно доведено, що Z2/ σ 2 має розподіл c2 з N – n степенями волі. Якщо тепер скористатися наведеною нижче теоремою 4.3.3, то одержимо, що Z1 / σ 2 має розподіл c2 з N – 2 – (N – n) = n – 2 степенями волі, причому величини Z1/ σ 2 і Z2 / σ 2 не залежать одна від одної. З першого положення випливає, що величина S 21 = Z1/(n – 2) є незсуненою оцінкою σ 2. З другого положення випливає, що величини S 21 = Z1 σ 2/(σ 2(n – 2)) та S 22 = Z2 σ 2/(σ 2(N – n))є незалежними.
4.3.2. Вправа. Доведіть рівність (4.26) самостійно, скориставшись міркуваннями типу тих, що використовувалися при доведенні рівності (3.2).
4.3.3. Теорема. Нехай x = (x 1,…, xn) — випадковий вектор з нормальним розподілом N (m, In), m = (m 1,…, mn), Qi, i = 1,2 — квадратичні форми від x 1 – m 1,…, xn – mn. Тоді якщо Qi Îc2(ri), причому Q 1 – Q 2 ³ 0, то Q 1 – Q 2 та Q 2 є незалежними і мають розподіли c2(r 1– r 2) та c2(r 2) відповідно.
4.3.4. Статистика для перевірки гіпотези про адекватність.
Із встановленого вище випливає співвідношення
S 21 / S 22 Î F (n – 2, N – n), (4.27)
де F — розподіл Фішера. Якщо розглядувана модель є адекватною, величини S 21 та S 22 оцінюють однаковий параметр σ 2. Звідси випливає процедура перевірки досліджуваної умови, що використовує вираз з лівої частини (4.27) (F -статистику) в якості статистики критерію і з квантилями розподілу F (n – 2, N – n) в якості критичних точок.
4.3.5. Зауваження. Застосовувати методику п. 4.2.8 перевірки гіпотези про незначимість регресії має сенс лише після перевірки гіпотези про адекватність моделі (2.3).
4.3.6. Зауваження. Згадану гіпотезу про незначимість коефіцієнту регресії (яка полягає в тому, що β 1 = 0) можна також перевірити, вживаючи F -розподіл Фішера. Наприклад, це випливає з того, що коли деяка випадкова величина має розподіл Стьюдента tn, то квадрат цієї величини має розподіл Фішера F 1, n. У поширених комп’ютерних програмах перевірка зазначеної гіпотези виконується з використанням обох розподілів. Для випадку розглядуваної тут простої лінійної регресії статистика критерію, що використовує розподіл F 1, n є просто квадратом статистики T (b 1) при b 10 = 0 (див. нижче зауваження 4.3.8). Звідси, по-перше, стає очевидним, що при використанні F 1, n для всіх трьох основних альтернатив (β 1¹0, β 1>0, β 1<0) слід використовувати односторонні критичні множини типу (u, +¥). (Тільки при перевірці першої з цих гіпотез в якості граничної точки u слід брати квантиль розподілу F 1, n рівня 1 – α, а при перевірці двох інших гіпотез — аналогічний квантиль рівня 1 – α / 2, де α — рівень значущості критерію). По-друге, ми бачимо, що обидва згадані способи перевірки гіпотези про незначимість регресії є, по суті, еквівалентними. Використання обох цих способів у статистичному комп’ютерному забезпеченні пояснюється тим, що при розгляданні лінійної регресії з кількома незалежними змінними Т -статистики служать для перевірки значущості окремих коефіцієнтів регресії, а F -статистики — для перевірки значущості регресії в цілому.
4.3.7. Вправа. Довести, що для простої лінійної регресії відношення F суми квадратів, що обумовлена регресією (інакше, обумовлена моделлю –рівність (3.3)) до суми квадратів відносно регресії має розподіл Фішера F 1, n – 2.
Вказівка. Величина у лівій частині рівності (3.3), поділена на σ 2, має розподіл c2(n –1). За теоремою 4.2.1 перший доданок у правій її частині, поділений на σ 2, розподілений за законом c2(n –2). Тому за теоремою 4.3.3 другий доданок з правої частини (3.2), поділений на σ 2, має розподіл c2(1) і не залежить від першого доданку. Звідси розглядуване відношення
F =  (4.27)
(4.27)
має розподіл F 1, n – 2.
4.3.8. Зауваження. За означенням b 1,
F =  .
.
Дана величина є квадратом статистики T (b 1) при β 1=0 (рівність (4.19)). Звідси випливає, що F -відношення (4.27) дійсно може використовуватися як статистика критерію при перевірці гіпотези про незначущість коефіцієнту регресії β 1.
Лабораторні роботи
Лабораторна робота № 9
Проста лінійна регресія
Завдання. На основі поданої (згідно варіанту) вибірки спостережень
| х |
| ||
| Х(1) | y(1) | ||
| Х(2) | y(2) | ||
| … | … | ||
| х(m) | y(m) |
Хід роботи
та вказівки до використання прикладного пакету STATGRAPHICS
1. Запустити STATGRAPHICS, ввести експериментальні дані, отримані згідно варіанту. Зберегти файл даних (пункт меню File→Save→Data File…). Роздрукувати файл даних.
Наприклад:
| X | 0,1 | 0,2 | 0,3 | 0,4 | 0,5 | 0,6 | 0,7 | 0,8 | 0,9 | 1,0 | 1,1 | 1,2 | 1,3 | 1,4 | 1,5 | 1,6 | 1,7 | 1,8 | 1,9 | 2,0 |
| y | -0,02 | 0,44 | 0,51 | 0,67 | 0,69 | 1.04 | 1,14 | 1,37 | 1,77 | 2,12 | 2,47 | 2,9 | 3,5 | 3,99 | 4,06 | 4,54 | 4,99 | 5,36 | 5,99 |
2. У верхньому рядку меню знайти пункт Relate → Simple Regression. На екрані з’явиться діалогове вікно із списком усіх доступних даних. Треба виділити незалежну змінну (х) і залежну змінну (у). Після цього натиснути кнопку ОК на цій формі. Відбудеться процедура простого регресійного аналізу. На екрані з’являться дві таблиці і статистичне зведення. Перша з цих таблиць пов’язана із коефіцієнтами моделі, їх статистичною значимістю, а друга – із якістю моделі в цілому. Роздрукувати таблиці і статистичне зведення. Наприклад:
Regression Analysis - Linear model: Y = a + b*X
-----------------------------------------------------------------------------
Dependent variable: y
Independent variable: x
-----------------------------------------------------------------------------
Standard T
Parameter Estimate Error Statistic P-Value
-----------------------------------------------------------------------------
Intercept 0,264386 0,0422984 6,25048 0,0000
Slope 0,317228 0,0138497 22,905 0,0000
-----------------------------------------------------------------------------
Analysis of Variance
-----------------------------------------------------------------------------
Source Sum of Squares Df Mean Square F-Ratio P-Value
-----------------------------------------------------------------------------
Model 6,42941 1 6,42941 524,64 0,0000
Residual 0,220589 18 0,012255
-----------------------------------------------------------------------------
Total (Corr.) 6,65 19
Correlation Coefficient = 0,983274
R-squared = 96,6829 percent
Standard Error of Est. = 0,110702
The StatAdvisor
---------------
The output shows the results of fitting a linear model to describe
the relationship between y and x. The equation of the fitted model is
y = 0,264386 + 0,317228*x
Since the P-value in the ANOVA table is less than 0.01, there is a
statistically significant relationship between y and x at the 99%
confidence level.
The R-Squared statistic indicates that the model as fitted explains
96,6829% of the variability in y. The correlation coefficient equals
0,983274, indicating a relatively strong relationship between the
variables. The standard error of the estimate shows the standard
deviation of the residuals to be 0,110702. This value can be used to
construct prediction limits for new observations by selecting the
Forecasts option from the text menu.
3. На рядку меню посередині екрана знайти кнопку Graphical Options. Натиснути її і вибрати:
- plot of fitted model;
- residual versus x.
Отримаємо графіки: графік побудованої моделі, графік остатків.

 Роздрукувати ці графіки.
Роздрукувати ці графіки.
4. В контекстному меню знайти і вибрати Comparison of Alternative Models (порівняння альтернативних моделей). На екрані з’явиться таблиця:
Comparison of Alternative Models
--------------------------------------------------
Model Correlation R-Squared
--------------------------------------------------
Linear 0,9833 96,68%
Square root-Y 0,9431 88,95%
Exponential 0,8637 74,59%
Reciprocal-Y <no fit>
Reciprocal-X <no fit>
Double reciproc <no fit>
Logarithmic-X <no fit>
Multiplicative <no fit>
Square root-X <no fit>
S-curve <no fit>
Logistic <no fit>
Log probit <no fit>
--------------------------------------------------
Ця таблиця дає порівняльний аналіз усіх простих регресійних моделей, які можна побудувати за допомогою STATGRAPHICS, за обґрунтованістю моделі, за значеннями коефіцієнтів кореляції та детермінації, за дисперсією розрахунків і т. ін. Роздрукувати порівняльну таблицю.
5*. Дослідити таблицю з попереднього пункту (на якому місці з побудованих моделей знаходиться лінійна і т.д.). Виконати пункти 1 - 3 лабораторної роботи для моделі, що виявилась на першому місці за якістю, якщо це не лінійна, або для другої, якщо лінійна – перша.
Лабораторна робота № 10
Поліноміальна регресія
Завдання. На основі поданої (згідно варіанту) вибірки спостережень побудувати поліноміальні регресійні залежності y = a0 + а1x + а2х2 та y = a0 + а1x + а2х2 + а3х3. Оцінити якість побудованих моделей.
Хід роботи
1. Запустити STATGRAPHICS, відкрити збережений в лаб. роботі № 9 файл даних.
2. У меню знайти пункт Relate → Polynomial Regression. Подальші дії аналогічні проведеним в лаб. роботі № 9. Побудувати регресійні моделі у вигляді поліномів 2-го і 3-го порядків. Роздрукувати таблиці щодо коефіцієнтів і якості моделей і статистичні зведення для цих моделей.
3. Побудувати для поліноміальних моделей 2-го і 3-го порядків по два графіки: графік моделі і графік остатків. Роздрукувати ці графіки.
Лабораторна робота № 11

