




Визначимо так звані залишки регресійної моделі (2.3). За означенням, це величини ei = yi –  , де
, де  , i = 1,…, n. Вектором залишків моделі (2.3) називається вектор e = (e 1,…, en). Зауважимо, що коли з самого початку вільний член b 0 входив у модель (тобто не покладався одразу рівним 0), то сума всіх залишків (інакше, сума координат вектору залишків) дорівнює 0, тобто
, i = 1,…, n. Вектором залишків моделі (2.3) називається вектор e = (e 1,…, en). Зауважимо, що коли з самого початку вільний член b 0 входив у модель (тобто не покладався одразу рівним 0), то сума всіх залишків (інакше, сума координат вектору залишків) дорівнює 0, тобто
å еi = 0 (3.1)
Це одразу випливає з рівності ¶ S /¶ b 0 = 0 при b 0 = b 0, b 1 = b 1 (див. рівність на с. 9). Зазначена властивість використовується, наприклад, при перевірці обчислень за МНК, якщо останні виконувалися вручну.
3.1. Зауваження. Корисно помітити, що середнє арифметичне значень  , i = 1, 2, …, n дорівнює
, i = 1, 2, …, n дорівнює  – середньому значенню спостережуваних відгуків y 1,…, yn. Тобто, коли позначити
– середньому значенню спостережуваних відгуків y 1,…, yn. Тобто, коли позначити
 = , i = 1, 2, …, n;
= , i = 1, 2, …, n;  =(
=( +…+
+…+  )/ n,
)/ n,
то матимемо рівність
= . (3.2)
Дійсно, згідно з рівністю (2.10) маємо
=  / n = ( ( + b 1(xi –
/ n = ( ( + b 1(xi –  )))/ n = + b 1 – b 1 = .
)))/ n = + b 1 – b 1 = .
З рівності (3.2) одразу випливає вже відзначений вище факт рівності 0 суми координат вектора залишків e:
S ei = S (yi – ) = n – n = 0.
(Нагадаємо, що коли не робиться спеціальних роз’яснень, то за відсутністю індексів у символі S мається на увазі підсумовування від 1 до n).
3.2. Про одну властивість оцінок МНК.
У багатьох питаннях регресійного аналізу є корисною наступна рівність
S(yi – )2 = S(yi – )2 + S( – )2. (3.3)
Дана рівність часто називається основною тотожністю дисперсійного аналізу. (Зміст цієї назви стане зрозумілим дещо пізніше.) Сама ж рівність (3.3) може бути одержана наступним чином.
S(yi – )2 = S(yi – + – )2 = S(yi – )2 + S( – )2 +
+ 2S( – ) ( – ).
Тепер досить довести, що остання сума дорівнює 0. Використовуючи рівність (2.10), маємо
– = b 1(xi – ), yi – = yi – – b 1(xi – ).
Звідси вказана сума дорівнює
S b 1(xi – )((yi – ) – b 1(xi – )) = b 1(Sx y – b 1 Sx x) = 0
(врахувати рівність (2.9)). Рівність (3.3) доведено.
З аналогічних міркувань також зрозуміло, що
S( – )2 = S(b 1(xi – ))2 = b 12 Sx x = b 1 Sx y. (3.4)
Зауважимо, що суми квадратів у рівності (3.3) мають спеціальні назви. Сума зліва – сума квадратів відносно середнього; перша сума справа – сума квадратів відносно регресії; друга сума справа – сума квадратів, що зумовлена регресією.
3.3. Пояснювана частина варіації даних.
Позначимо
R 2 =  . (3.5)
. (3.5)
З рівності (3.3) одразу випливає нерівність
R 2 £ 1. (3.6)
Можна вважати, що величина R 2 вимірює „долю загального розкидання даних, що пояснюється регресією”. Її часто вимірюють в процентах, помножуючи на 100. Досить часто величина R 2 носить назву „ коефіцієнт детермінації ”. Величина R 2 виводиться на друк у більшості відомих комп’ютерних програм з регресійного аналізу. Чим ближчою є величина R 2 до 1, тим краще функція регресії (2.9) відповідає дійсному характеру зв’язку між незалежною та залежною змінними.
3.2.1. Зв’язок величини R 2 з вибірковими коефіцієнтами кореляції R x y та  .
.
Як відомо, коефіцієнтом кореляції між випадковими величинами x, h називається вираз
rxh = Cov(x, h) / (Dx × Dh)1 / 2,
де Cov(x, h) = Мxh – Мx Мh, D – символ дисперсії.
Оцінкою коефіцієнта кореляції (або вибірковим коефіцієнтом кореляції) між двома величинами x та h є вираз
Rxh =  , (3.7)
, (3.7)
де (xi, hi), i = 1,..., n – значення (x, h) в n незалежних експериментах,  та
та  – відповідні середні арифметичні, а підсумовування виконується від 1 до n.
– відповідні середні арифметичні, а підсумовування виконується від 1 до n.
Позначимо Rxy та , відповідно, вибіркові коефіцієнти кореляції між x та y і y та ŷ відповідно. Тоді мають місце рівності
= sign (b 1) × Rxy (3.8)
де
sign x = 
R 2 = (Rxy)2, (3.9)
R 2 = ()2 (3.10)
Дійсно, з використанням (3.4) одержуємо
 = sign (b 1)× Rxy (3.11)
= sign (b 1)× Rxy (3.11)
З іншого боку,
R 2 =  = (Rxy)2.
= (Rxy)2.
(3.11) і останні співвідношення доводять рівності (3.8) — (3.10).
РОЗДІЛ 4.
Ймовірнісні припущення про випадкову складову моделі простої лінійної регресії та їх наслідки.
4.1. Незалежність, однорідність і відсутність систематичних похибок.
Надалі буде вважатися, що всі експерименти є незалежними, виконуються в однакових умовах і не мають систематичних похибок. Математично це виражається наступним чином. Нехай εі позначає величину похибки в і -му експерименті (тобто εі = yi – (β 0 + β 1 xi)), і = 1,..., n Тоді вектор похибок ε = (ε 1,..., εn) становить собою сукупність незалежних однаково розподілених випадкових величин, причому математичні сподівання кожної з цих величин дорівнюють 0:
Mεі = 0, і = 1,..., n, (4.1)
а дисперсії дорівнюють деякій сталій σ2:
Dεі = σ 2, і = 1,..., n. (4.2)
4.1.1. Зауваження. З (4.1) та (4.2) одразу випливають рівності (переконайтеся в цьому):
Mу (х) = β 0 + β 1 х, (4.3)
D у (х) = σ 2, (4.4)
D 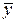 = σ 2 ∕ n (4.5)
= σ 2 ∕ n (4.5)
4.1.2. Наслідки. Наслідками зроблених вище припущень є також наступні властивості оцінок параметрів моделі:
1) Mb 0 = β 0, Mb 1 = β 1; (4.6)
2) Db 0 =  σ 2, Db 1 =
σ 2, Db 1 = 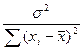 . (4.7)
. (4.7)
3) Cov (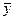 , b 1) = 0, (4.8)
, b 1) = 0, (4.8)
4) Cov (b 0, b 1) =  . (4.9)
. (4.9)
5) Нехай х 0 – довільне значення змінної х. Позначимо ŷ 0 значення оцінки функції регресії ŷ в точці х 0. Тоді має місце рівність
D ŷ 0 =  . (4.10)
. (4.10)
Зокрема, рівності (4.6) означають, що b 0 та b 1 є незсуненими оцінками, відповідно, величин β0 та β1. Рівності (4.7) дають вирази дисперсій оцінок коефіцієнтів регресії через дисперсію випадкової складової моделі (2.3). Рівність (4.8) стверджує некорельованість величин та b 1. Рівність (4.9) дає явний вираз коваріацій між оцінками b 0, b 1, а (4.10) — вираз дисперсії оцінки функції регресії у довільній точці спостережень. З останньої рівності одразу бачимо, що дисперсія величини ŷ 0 є мінімальною, коли точка х 0 співпадає з 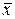 і зростає при віддаленні цієї точки від .
і зростає при віддаленні цієї точки від .

