




Доведемо спочатку властивість 1). Маємо Mb 1= 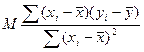 . При цьому
. При цьому 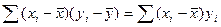 (Переконайтеся у вірності останньої рівності). Враховуючи ще рівність
(Переконайтеся у вірності останньої рівності). Враховуючи ще рівність
yi = β 0 + β 1 xi + εі, (4.11)
одержуємо
Mb 1 = 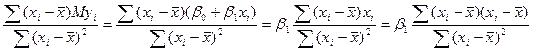 =
=
=  .
.
Mb 0 = 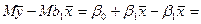
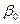 .
.
Рівності (4.6) доведено.
Аналогічним чином отримуємо:
Db 1= 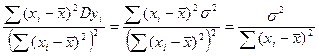 .
.
Другу з нерівностей (4.7) доведено. Першу з зазначених нерівностей буде доведено трохи пізніше. Перед доказом властивості 3) нагадаємо, що для випадкових величин x, h їх коваріація Cov (x, h) обчислюється за формулою Cov (x, h) = Мxh – Мx Мh. Згадаємо також кілька властивостей коваріацій випадкових величин та коваріаційних матриць випадкових векторів.
1. Для випадкової величини x має місце рівність Cov (x, x) = Dx.
2. Для випадкових величин x, h, x 1, x 2, h 1, h 2 та сталих а 1, а 2 мають місце рівності
Cov (а 1 x 1+ а 2 x 2, h) = а 1 Cov (x 1, h) + а 2 Cov (x 2, h),
Cov (x, а 1 h 1 + а 2 h 2) = а 1 Cov (x, h 1) + а 2 Cov (x, h 2).
3. Нехай D (x, h) – коваріаційна матриця випадкових векторів x, h, що мають компоненти x 1, x 2,… та h 1, h 2,… відповідно (так що на місті (i, j) матриці D (x, h) стоїть величина Cov(xi, hj)); нехай також А, В – невипадкові матриці. Тоді D (Аx, Вh) = АD (x, h) 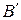 , де – транспонована до В матриця.
, де – транспонована до В матриця.
Повернемося до доказу властивості 3) оцінок МНК. Нехай Y = (y 1, y 2,..., yn)' – n -вимірний вектор-стовбець спостережень, А =  , В =
, В =  . Легко бачити, що
. Легко бачити, що 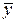 = АY, b 1 = ВY. При цьому DY = σ 2 I, де I – одинична матриця розміру n ´ n. Отже, використовуючи властивість 3. коваріаційної матриці, одержуємо
= АY, b 1 = ВY. При цьому DY = σ 2 I, де I – одинична матриця розміру n ´ n. Отже, використовуючи властивість 3. коваріаційної матриці, одержуємо
Cov (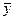 , b 1) = Cov (АY, ВY) = А (DY) В ' =
, b 1) = Cov (АY, ВY) = А (DY) В ' = 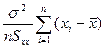 = 0,
= 0,
тобто рівність (4.8) доведено. Тепер, користуючись відомою властивістю дисперсії суми некорельованих випадкових величин, одержимо:
Db 0 = D ( – 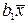 ) = D +
) = D + 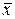 2 D
2 D 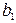 =
= 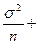
 =
=
=  , що й доводить першу з нерівностей (4.7). Для доказу (4.9), використовуючи відомі властивості коваріацій випадкових величин, знайдемо:
, що й доводить першу з нерівностей (4.7). Для доказу (4.9), використовуючи відомі властивості коваріацій випадкових величин, знайдемо:
Cov (b 0, b 1) = Cov ( – b 1 , b 1) = Cov (, b 1) + Cov (– b 1 , b 1) = – Cov (b 1, b 1) = = – Db 1.
Тепер лишається скористатися другою з властивостей 2).
Нарешті, згідно з рівностями (2.10) та (4.8), маємо
D ŷ 0 = D [ + (х 0 – х) b 1] = D + (х 0 – х)2 D b 1.
Тепер лишається скористатися рівностями (4.5) та (4.7). Зауважимо, що дисперсія величини ŷ 0 є мінімальною, коли точка х 0 співпадає з і зростає при віддаленні цієї точки від .
4.2. Нормальність випадкової складової. Надалі постійно припускатиметься, що випадкова складова e регресійної моделі (2.3) є нормально розподіленою випадковою величиною з нульовим математичним сподіванням і деякою (невідомою) дисперсією s 2:
e Î N (0, s). (4.12)
Припущення, зроблені вище, зумовлюють, що вектор випадкових складових E = (e 1, e 2,…, eп), де ei = yi – (β 0 + β 1 xi), i = 1,2,…, n, є нормально розподіленим випадковим вектором з взаємно незалежними компонентами, кожна з яких має тип (4.12). Зокрема, коваріаційна матриця D (E) вектора E є діагональною з елементами s 2 на головній діагоналі:
D (E) =  = s 2 In, (4.13)
= s 2 In, (4.13)
де In – одинична матриця розміру n ´ n.
Позначимо ще Y вектор спостережень, тобто Y = (y 1,…, yn). Зауважимо, що оскільки β 0 + β 1 xi — є невипадковими величинами, то
D (Y) = D (E). (4.14)
З припущення (4.12) випливає дуже багато корисних наслідків. Зокрема, такими є дві наступні теореми, справедливість яких буде наведено у подальших розділах курсу як наслідок деяких більш загальних положень.
4.2.1. Теорема. Остаточна сума квадратів, поділена на s 2, має розподіл c2 з
n – 2 степенями волі, коротше:
RSS / s 2 Îc2 n –2,
де RSS = S(yi – ŷi)2.
4.2.2. Зауваження. Нехай відомо, що відношення деякої випадкової величини 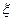 до деякої сталої величини (параметру) q має розподіл c2 з m степенями волі. Тоді відношення / m є незсуненою оцінкою для q.
до деякої сталої величини (параметру) q має розподіл c2 з m степенями волі. Тоді відношення / m є незсуненою оцінкою для q.
ð Дійсно, оскільки x / q має розподіл c2 m, то M (x / q) = m, тому M (x / m) = q. ð
Позначимо
RSS /(n – 2) = S 2. (4.15)
4.2.3. Наслідок. Величина S 2 є незсуненою оцінкою величини s 2:
M S 2 = s 2 (4.16)
4.2.4. Зауваження. Можна довести, що рівність (4.16) є справедливою і без припущення щодо нормальності розподілу x (за виконанням інших зроблених вище припущень щодо випадкової складової моделі (2.3).
4.2.5. Наслідок. Величини
 b 0 =
b 0 =  S 2, b 1 =
S 2, b 1 = 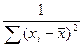 S 2 (4.17)
S 2 (4.17)
є незсуненими оцінками величин Db 0 та Db 1 відповідно.
4.2.6. Теорема. За умови (4.12) мають місце співвідношення
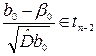 , (4.18)
, (4.18)
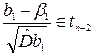 , (4.19)
, (4.19)
де tn – 2 — розподіл Стьюдента з n – 2 степенями волі.
4.2.7. Наслідок. Нехай 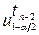 – квантиль рівня 1 – α /2 розподілу Стьюдента
– квантиль рівня 1 – α /2 розподілу Стьюдента
tn –2. Тоді інтервали
B 0 = [(b 0 – 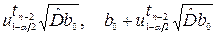 ],
],
B 1 = [(b 1 – 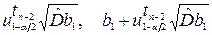 ],
],
є довірчими інтервалами рівня α для параметрів b 0 та b 1 відповідно.
ð Це випливає із співвідношень (4.18), (4.19) та тією властивістю квантилів неперервних випадкових величин, що F (up) = p, де F – функція розподілу даної випадкової величини, up – її квантиль рівня p. ð
4.2.8. Зауваження про перевірку гіпотез щодо значень коефіцієнтів β 0, β 1.
Щойно наведені результати дають змогу перевіряти гіпотези 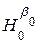 : β 0 = b 00 та
: β 0 = b 00 та  : β 1 = b 10, де b 00 та b 10 – фіксовані числа. Ідея перевірки є дуже простою. Якщо число b 00 належить інтервалові B 0, то гіпотеза приймається, у протилежному випадку – не приймається. Аналогічно перевіряється гіпотеза .
: β 1 = b 10, де b 00 та b 10 – фіксовані числа. Ідея перевірки є дуже простою. Якщо число b 00 належить інтервалові B 0, то гіпотеза приймається, у протилежному випадку – не приймається. Аналогічно перевіряється гіпотеза .
Досить часто, зокрема, в комп’ютерних реалізаціях даної процедури перевірки використовуються дещо інші (формально, але не по суті) дії. А саме, позначимо T (b 0) (T (b 1)) величину з правої частини (4.18) ((4.19)) при β 0 = b 00 (β 1 = b 10). Ця величина порівнюється з – квантилем рівня 1 – α /2 розподілу Стьюдента tn –2. Відповідна гіпотеза не приймається, якщо за абсолютною величиною вказана величина перевищує даний квантиль. Іншими словами, гіпотеза не приймається, якщо T (b 0) (відповідно, T (b 1)) попадає у двосторонню критичну множину (– ¥, – ) È (, + ¥). За наявністю альтернативної гіпотези { bi ³ bi 0} ({ bi £ bi 0}), i Î {0,1}, доцільніше використовувати односторонню критичну множину ( , + ¥) ((– ¥, – )
, + ¥) ((– ¥, – )
Особливо часто доводиться перевіряти гіпотезу при b 10 = 0 (тобто мова йде про перевірку гіпотези { β 1 = 0}. У цьому випадку називається гіпотезою про незначимість коефіцієнту регресії. Якщо вона приймається, то можна вважати, що y не залежить від x (в рамках лінійної моделі(2.3)).
4.2.9. Зауваження. Деякі поширені комп’ютерні статистичні програми, наприклад, Statgraphics 3.0, використовують дещо іншу техніку перевірки гіпотез. А саме, не фіксуються заздалегідь критичні множини, а обчислюються так звані P -значення (P -values). Зокрема, при перевірці гіпотези () P -значення є ймовірністю того, що за умови справедливості даної гіпотези, статистика T (b 0) (відповідно, T (b 1)) буде за абсолютною величиною рівною або більшою того значення, що конкретно отримано. Малість P -значення свідчить про недоцільність довіри до цієї гіпотези. Навпаки, великі P -значення свідчать на користь гіпотез, що перевіряються. Так, малі P -значення при перевірці гіпотези з b 10 = 0 свідчать про значимість коефіцієнту регресії b 1. З коментарів, які містяться у відповідних роздруківках, можна зрозуміти, що вважається малим, а що – великим P -значенням у кожному конкретному випадку.

