




В окне Multiple Regression выберем вкладку Residuals/assumptions/prediction, позволяющую оценить остатки и нажмем на кнопку Perform Residual analysis. Далее кнопкой активизируем окно (рис. 2.6).
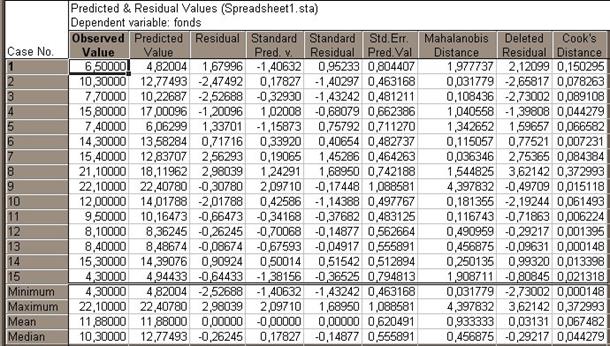
Рис. 2.6. Наблюдаемые и предсказанные значения остатков
Первые четыре столбца этой таблицы определяют: номера наблюдений (названия областей), фактические (Observed Value) и расчетные значения (Predicted Value) количества продукции, отклонения фактических данных от расчетных (Residual). Четыре последних строки содержат минимальное, максимальное, среднее и медианное значения показателей. Равенство нулю среднего значения остатков свидетельствует о корректности расчетов.
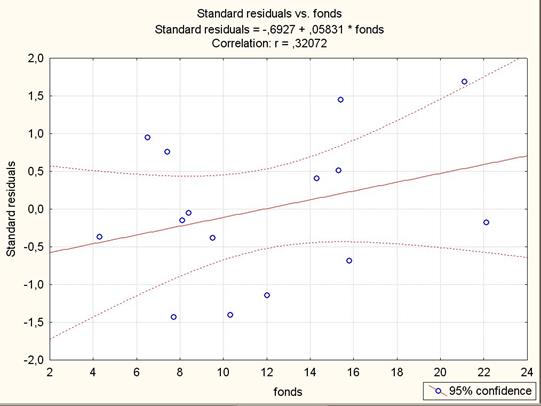
Рис. 2.7. Доверительные интервалы для зависимой переменной
Построим регрессию выработки по фондам для более однородной совокупности – для предприятий федерального подчинения (при z = 1). Можно ожидать, что качество подгонки улучшится. Предварительно визуально оценим данные процедурой Scatterplot. При отборе наблюдений будем использовать кнопку Select cases во вкладке Advanced. Зададим условие отбора в окне By expression: z = 1. Полученный график отображен на рис. 2.8.
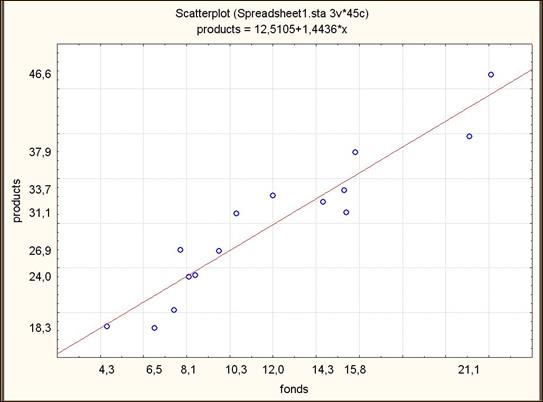
Рис. 2.8. Диаграмма рассеяния по отобранным данным
Возвращаемся в окно Multiple Regression. Нажав на кнопку Select cases, убеждаемся, что там также автоматически установлено условие отбора z = 1 (если нет – устанавливаем это условие).

Рис. 2.9. Таблица результатов регрессионного анализа по отобранным данным
Получаем результаты анализа
Product = 12.55 + 1.44 fonds,
R 2 = RI = 0.897, S = 2.68.
Коэффициент детерминации увеличился с 0.597 до 0.897, значение s уменьшилось с 5.01 до 2.68; действительно, подгонка улучшилась.

