




Парная регрессия может дать хороший результат при моделировании, если влиянием других факторов, воздействующих на объект исследования, можно пренебречь. Если же этим влиянием пренебречь нельзя, то в этом случае следует попытаться выявить влияние других факторов, введя их в модель, т.е. построить уравнение множественной регрессии
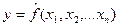 ,
,
где  – зависимая переменная (результативный признак),
– зависимая переменная (результативный признак),  – независимые, или объясняющие, переменные (признаки-факторы).
– независимые, или объясняющие, переменные (признаки-факторы).
Построение уравнения множественной регрессии начинается с решения вопроса о спецификации модели. Он включает в себя два круга вопросов: отбор факторов и выбор вида уравнения регрессии.
Включение в уравнение множественной регрессии того или иного набора факторов связано прежде всего с представлением исследователя о природе взаимосвязи моделируемого показателя с другими экономическими явлениями. Факторы, включаемые во множественную регрессию, должны отвечать следующим требованиям.
1. Они должны быть количественно измеримы. Если необходимо включить в модель качественный фактор, не имеющий количественного измерения, то ему нужно придать количественную определенность.
2. Факторы не должны быть интеркоррелированы и тем более находиться в точной функциональной связи.
Включение в модель факторов с высокой интеркорреляцией, может привести к нежелательным последствиям – система нормальных уравнений может оказаться плохо обусловленной и повлечь за собой неустойчивость и ненадежность оценок коэффициентов регрессии.
Если между факторами существует высокая корреляция, то нельзя определить их изолированное влияние на результативный показатель и параметры уравнения регрессии оказываются неинтерпретируемыми.
Включаемые во множественную регрессию факторы должны объяснить вариацию независимой переменной. Если строится модель с набором  факторов, то для нее рассчитывается показатель детерминации
факторов, то для нее рассчитывается показатель детерминации 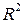 , который фиксирует долю объясненной вариации результативного признака за счет рассматриваемых в регрессии
, который фиксирует долю объясненной вариации результативного признака за счет рассматриваемых в регрессии  факторов. Влияние других, не учтенных в модели факторов, оценивается как
факторов. Влияние других, не учтенных в модели факторов, оценивается как  с соответствующей остаточной дисперсией
с соответствующей остаточной дисперсией  .
.
При дополнительном включении в регрессию  фактора коэффициент детерминации должен возрастать, а остаточная дисперсия уменьшаться:
фактора коэффициент детерминации должен возрастать, а остаточная дисперсия уменьшаться:
 и
и  .
.
Если же этого не происходит и данные показатели практически не отличаются друг от друга, то включаемый в анализ фактор  не улучшает модель и практически является лишним фактором.
не улучшает модель и практически является лишним фактором.
Насыщение модели лишними факторами не только не снижает величину остаточной дисперсии и не увеличивает показатель детерминации, но и приводит к статистической незначимости параметров регрессии по критерию Стьюдента.
Таким образом, хотя теоретически регрессионная модель позволяет учесть любое число факторов, практически в этом нет необходимости. Отбор факторов производится на основе качественного теоретико-экономического анализа. Однако теоретический анализ часто не позволяет однозначно ответить на вопрос о количественной взаимосвязи рассматриваемых признаков и целесообразности включения фактора в модель. Поэтому отбор факторов обычно осуществляется в две стадии: на первой подбираются факторы исходя из сущности проблемы; на второй – на основе матрицы показателей корреляции определяют статистики для параметров регрессии.
Коэффициенты интеркорреляции (т.е. корреляции между объясняющими переменными) позволяют исключать из модели дублирующие факторы. Считается, что две переменные явно коллинеарны, т.е. находятся между собой в линейной зависимости, если  . Если факторы явно коллинеарны, то они дублируют друг друга и один из них рекомендуется исключить из регрессии. Предпочтение при этом отдается не фактору, более тесно связанному с результатом, а тому фактору, который при достаточно тесной связи с результатом имеет наименьшую тесноту связи с другими факторами. В этом требовании проявляется специфика множественной регрессии как метода исследования комплексного воздействия факторов в условиях их независимости друг от друга.
. Если факторы явно коллинеарны, то они дублируют друг друга и один из них рекомендуется исключить из регрессии. Предпочтение при этом отдается не фактору, более тесно связанному с результатом, а тому фактору, который при достаточно тесной связи с результатом имеет наименьшую тесноту связи с другими факторами. В этом требовании проявляется специфика множественной регрессии как метода исследования комплексного воздействия факторов в условиях их независимости друг от друга.
Пусть, например, при изучении зависимости  матрица парных коэффициентов корреляции оказалась следующей:
матрица парных коэффициентов корреляции оказалась следующей:
|
| 
| 
| 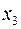
| |
|
| 0,8 | 0,7 | 0,6 | |
|
| 0,8 | 0,8 | 0,5 | |
|
| 0,7 | 0,8 | 0,2 | |
|
| 0,6 | 0,5 | 0,2 |
Очевидно, что факторы  и
и  дублируют друг друга. В анализ целесообразно включить фактор , а не
дублируют друг друга. В анализ целесообразно включить фактор , а не  , хотя корреляция с результатом слабее, чем корреляция фактора
, хотя корреляция с результатом слабее, чем корреляция фактора  с
с 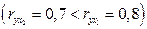 , но зато значительно слабее межфакторная корреляция
, но зато значительно слабее межфакторная корреляция  . Поэтому в данном случае в уравнение множественной регрессии включаются факторы
. Поэтому в данном случае в уравнение множественной регрессии включаются факторы 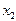 ,
,  .
.
По величине парных коэффициентов корреляции обнаруживается лишь явная коллинеарность факторов. Наибольшие трудности в использовании аппарата множественной регрессии возникают при наличии мультиколлинеарности факторов, когда более чем два фактора связаны между собой линейной зависимостью, т.е. имеет место совокупное воздействие факторов друг на друга. Наличие мультиколлинеарности факторов может означать, что некоторые факторы будут всегда действовать в унисон. В результате вариация в исходных данных перестает быть полностью независимой и нельзя оценить воздействие каждого фактора в отдельности.
Включение в модель мультиколлинеарных факторов нежелательно в силу следующих последствий:
1. Затрудняется интерпретация параметров множественной регрессии как характеристик действия факторов в «чистом» виде, ибо факторы коррелированы; параметры линейной регрессии теряют экономический смысл.
2. Оценки параметров ненадежны, обнаруживают большие стандартные ошибки и меняются с изменением объема наблюдений (не только по величине, но и по знаку), что делает модель непригодной для анализа и прогнозирования.
Для оценки мультиколлинеарности факторов может использоваться определитель матрицы парных коэффициентов корреляции между факторами.
Если бы факторы не коррелировали между собой, то матрица парных коэффициентов корреляции между факторами была бы единичной матрицей, поскольку все недиагональные элементы 
 были бы равны нулю. Так, для уравнения, включающего три объясняющих переменных
были бы равны нулю. Так, для уравнения, включающего три объясняющих переменных
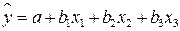
матрица коэффициентов корреляции между факторами имела бы определитель, равный единице:
 .
.
Если же, наоборот, между факторами существует полная линейная зависимость и все коэффициенты корреляции равны единице, то определитель такой матрицы равен нулю:
 .
.
Чем ближе к нулю определитель матрицы межфакторной корреляции, тем сильнее мультиколлинеарность факторов и ненадежнее результаты множественной регрессии. И, наоборот, чем ближе к единице определитель матрицы межфакторной корреляции, тем меньше мультиколлинеарность факторов.
Существует ряд подходов преодоления сильной межфакторной корреляции. Самый простой путь устранения мультиколлинеарности состоит в исключении из модели одного или нескольких факторов. Другой подход связан с преобразованием факторов, при котором уменьшается корреляция между ними.
Одним из путей учета внутренней корреляции факторов является переход к совмещенным уравнениям регрессии, т.е. к уравнениям, которые отражают не только влияние факторов, но и их взаимодействие. Так, если  , то возможно построение следующего совмещенного уравнения:
, то возможно построение следующего совмещенного уравнения:
 .
.
Рассматриваемое уравнение включает взаимодействие первого порядка (взаимодействие двух факторов). Возможно включение в модель и взаимодействий более высокого порядка, если будет доказана их статистическая значимость по  -критерию Фишера, но, как правило, взаимодействия третьего и более высоких порядков оказываются статистически незначимыми.
-критерию Фишера, но, как правило, взаимодействия третьего и более высоких порядков оказываются статистически незначимыми.
Отбор факторов, включаемых в регрессию, является одним из важнейших этапов практического использования методов регрессии. Подходы к отбору факторов на основе показателей корреляции могут быть разные. Они приводят построение уравнения множественной регрессии соответственно к разным методикам. В зависимости от того, какая методика построения уравнения регрессии принята, меняется алгоритм ее решения на ЭВМ.
Наиболее широкое применение получили следующие методы построения уравнения множественной регрессии:
1. Метод исключения – отсев факторов из полного его набора.
2. Метод включения – дополнительное введение фактора.
3. Шаговый регрессионный анализ – исключение ранее введенного фактора.
При отборе факторов также рекомендуется пользоваться следующим правилом: число включаемых факторов обычно в 6–7 раз меньше объема совокупности, по которой строится регрессия. Если это соотношение нарушено, то число степеней свободы остаточной дисперсии очень мало. Это приводит к тому, что параметры уравнения регрессии оказываются статистически незначимыми, а -критерий меньше табличного значения.
Возможны разные виды уравнений множественной регрессии: линейные и нелинейные.
Ввиду четкой интерпретации параметров наиболее широко используется линейная функция. В линейной множественной регрессии  параметры при
параметры при  называются коэффициентами «чистой» регрессии. Они характеризуют среднее изменение результата с изменением соответствующего фактора на единицу при неизмененном значении других факторов, закрепленных на среднем уровне.
называются коэффициентами «чистой» регрессии. Они характеризуют среднее изменение результата с изменением соответствующего фактора на единицу при неизмененном значении других факторов, закрепленных на среднем уровне.
Рассмотрим линейную модель множественной регрессии
 . (24)
. (24)
Классический подход к оцениванию параметров линейной модели множественной регрессии основан на методе наименьших квадратов (МНК).
Как известно из курса математического анализа, для того чтобы найти экстремум функции нескольких переменных, надо вычислить частные производные первого порядка по каждому из параметров и приравнять их к нулю.
Итак, имеем функцию 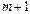 аргумента:
аргумента:
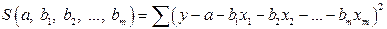 .
.
Находим частные производные первого порядка:
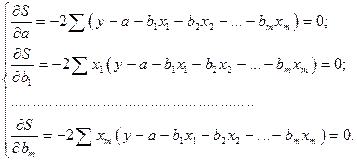
После элементарных преобразований приходим к системе линейных нормальных уравнений для нахождения параметров линейного уравнения множественной регрессии (25):
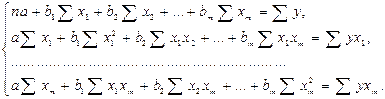 (25)
(25)
Для двухфакторной модели данная система будет иметь вид:

Решить полученную систему уравнений можно методом Крамера или воспользоваться готовыми формулами:
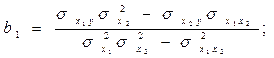
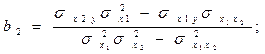
где 



Практическая значимость уравнения множественной регрессии оценивается с помощью показателя множественной корреляции и его квадрата – показателя детерминации.
Показатель множественной корреляции характеризует тесноту связи рассматриваемого набора факторов с исследуемым признаком или, иначе, оценивает тесноту совместного влияния факторов на результат.
Независимо от формы связи показатель множественной корреляции может быть найден как индекс множественной корреляции:
 , (26)
, (26)
где  – общая дисперсия результативного признака;
– общая дисперсия результативного признака;  – остаточная дисперсия.
– остаточная дисперсия.
Границы изменения индекса множественной корреляции от 0 до 1. Чем ближе его значение к 1, тем теснее связь результативного признака со всем набором исследуемых факторов. Величина индекса множественной корреляции должна быть больше или равна максимальному парному индексу корреляции:
 .
.
При правильном включении факторов в регрессионную модель величина индекса множественной корреляции будет существенно отличаться от индекса корреляции парной зависимости. Если же дополнительно включенные в уравнение множественной регрессии факторы третьестепенны, то индекс множественной корреляции может практически совпадать с индексом парной корреляции (различия в третьем, четвертом знаках). Отсюда ясно, что сравнивая индексы множественной и парной корреляции, можно сделать вывод о целесообразности включения в уравнение регрессии того или иного фактора.
Формула индекса множественной корреляции для линейной регрессии получила название линейного коэффициента множественной корреляции, или, что то же самое, совокупного коэффициента корреляции.
Возможно также при линейной зависимости определение совокупного коэффициента корреляции через матрицу парных коэффициентов корреляции:
 , (27)
, (27)
где
 – определитель матрицы парных коэффициентов корреляции;
– определитель матрицы парных коэффициентов корреляции;
 – определитель матрицы межфакторной корреляции.
– определитель матрицы межфакторной корреляции.
Как видим, величина множественного коэффициента корреляции зависит не только от корреляции результата с каждым из факторов, но и от межфакторной корреляции. Рассмотренная формула позволяет определять совокупный коэффициент корреляции, не обращаясь при этом к уравнению множественной регрессии, а используя лишь парные коэффициенты корреляции.
Коэффициенты частной корреляции более высоких порядков можно определить через коэффициенты частной корреляции более низких порядков по рекуррентной формуле:
 .(28)
.(28)
При двух факторах данная формула примет вид:
 ;
;  . (29)
. (29)
Рассчитанные по рекуррентной формуле частные коэффициенты корреляции изменяются в пределах от –1 до +1, а по формулам через множественные коэффициенты детерминации – от 0 до 1. Сравнение их друг с другом позволяет ранжировать факторы по тесноте их связи с результатом.
Значимость уравнения множественной регрессии в целом, так же как и в парной регрессии, оценивается с помощью -критерия Фишера:
 , (30)
, (30)
где  – факторная сумма квадратов на одну степень свободы;
– факторная сумма квадратов на одну степень свободы;  – остаточная сумма квадратов на одну степень свободы;
– остаточная сумма квадратов на одну степень свободы;  – коэффициент (индекс) множественной детерминации; m – число параметров при переменных x (в линейной регрессии совпадает с числом включенных в модель факторов); n – число наблюдений.
– коэффициент (индекс) множественной детерминации; m – число параметров при переменных x (в линейной регрессии совпадает с числом включенных в модель факторов); n – число наблюдений.
Оценивается значимость не только уравнения в целом, но и фактора, дополнительно включенного в регрессионную модель. Необходимость такой оценки связана с тем, что не каждый фактор, вошедший в модель, может существенно увеличивать долю объясненной вариации результативного признака. Кроме того, при наличии в модели нескольких факторов они могут вводиться в модель в разной последовательности. Ввиду корреляции между факторами значимость одного и того же фактора может быть разной в зависимости от последовательности его введения в модель. Мерой для оценки включения фактора в модель служит частный  -критерий, т.е.
-критерий, т.е.  .
.
Частный -критерий построен на сравнении прироста факторной дисперсии, обусловленного влиянием дополнительно включенного фактора, с остаточной дисперсией на одну степень свободы по регрессионной модели в целом. В общем виде для фактора  частный -критерий определится как
частный -критерий определится как
 , (31)
, (31)
где  – коэффициент множественной детерминации для модели с полным набором факторов,
– коэффициент множественной детерминации для модели с полным набором факторов,  – тот же показатель, но без включения в модель фактора
– тот же показатель, но без включения в модель фактора  , n – число наблюдений, m – число параметров в модели (без свободного члена).
, n – число наблюдений, m – число параметров в модели (без свободного члена).
Фактическое значение частного -критерия сравнивается с табличным при уровне значимости α и числе степеней свободы: 1 и 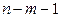 . Если фактическое значение
. Если фактическое значение  превышает
превышает  , то дополнительное включение фактора в модель статистически оправданно и коэффициент чистой регрессии
, то дополнительное включение фактора в модель статистически оправданно и коэффициент чистой регрессии  при факторе статистически значим. Если же фактическое значение
при факторе статистически значим. Если же фактическое значение 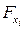 меньше табличного, то дополнительное включение в модель фактора
меньше табличного, то дополнительное включение в модель фактора  не увеличивает существенно долю объясненной вариации признака y, следовательно, нецелесообразно его включение в модель; коэффициент регрессии при данном факторе в этом случае статистически незначим.
не увеличивает существенно долю объясненной вариации признака y, следовательно, нецелесообразно его включение в модель; коэффициент регрессии при данном факторе в этом случае статистически незначим.
Для двухфакторного уравнения частные -критерии имеют вид:
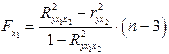 ,
, 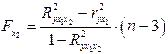 . (32)
. (32)
С помощью частного -критерия можно проверить значимость всех коэффициентов регрессии в предположении, что каждый соответствующий фактор вводился в уравнение множественной регрессии последним.
Временные ряды
При построении эконометрической модели используются два типа данных:
1) данные, характеризующие совокупность различных объектов в определенный момент времени;
2) данные, характеризующие один объект за ряд последовательных моментов времени.
Модели, построенные по данным первого типа, называются пространственными моделями. Модели, построенные на основе второго типа данных, называются моделями временных рядов.
Происходящие в экономических системах процессы в основном проявляются как ряд расположенных в хронологическом порядке значений определенного показателя, который в своем изменении несет определенную информацию о динамике изучаемого явления.
Временной ряд (ряд динамики) – это совокупность значений какого-либо показателя за несколько последовательных моментов или периодов времени. Каждый уровень временного ряда формируется под воздействием большого числа факторов, которые условно можно подразделить на три группы:
1) факторы, формирующие тенденцию ряда;
2) факторы, формирующие циклические колебания ряда;
3) случайные факторы.
Рассмотрим воздействие каждого фактора на временной ряд в отдельности.
Большинство временных рядов экономических показателей имеют тенденцию, характеризующую совокупное долговременное воздействие множества факторов на динамику изучаемого показателя. Все эти факторы, взятые в отдельности, могут оказывать разнонаправленное воздействие на исследуемый показатель. Однако в совокупности они формируют его возрастающую или убывающую тенденцию. На рис.1 показан гипотетический временной ряд, содержащий возрастающую тенденцию.

Рис. 1
Также изучаемый показатель может быть подвержен циклическим колебаниям. Эти колебания могут носить сезонный характер, поскольку экономическая деятельность ряда отраслей экономики зависит от времени года (например, цены на сельскохозяйственную продукцию в летний период выше, чем в зимний; уровень безработицы в курортных городах в зимний период выше по сравнению с летним). При наличии больших массивов данных за длительные промежутки времени можно выявить циклические колебания, связанные с общей динамикой конъюнктуры рынка. На рис.2 представлен гипотетический временной ряд, содержащий только сезонную компоненту.

Рис. 2
Некоторые временные ряды не содержат тенденции и циклической компоненты, а каждый следующий их уровень образуется как сумма среднего уровня ряда и некоторой (положительной или отрицательной) случайной компоненты. Пример ряда, содержащего только случайную компоненту, приведен на рис.3.

Рис. 3
Итак, во временном ряде можно выделить три составляющие:
1) Тренд, т.е. общая некоторая закономерность к росту или убыванию, тренд относят к систематической составляющей долговременного действия.
2) Сезонная (или циклическая) компонента. Если период колебаний не превышает года, то это сезонная компонента, если более года, то - циклическая.
3) Случайная компонента (шум).
В большинстве случаев фактический уровень временного ряда можно представить как сумму или произведение трендовой, циклической и случайной компонент. Модель, в которой временной ряд представлен как сумма перечисленных компонент, называется аддитивной моделью временного ряда. Модель, в которой временной ряд представлен как произведение перечисленных компонент, называется мультипликативной моделью временного ряда. Основная задача эконометрического исследования отдельного временного ряда – выявление и придание количественного выражения каждой из перечисленных выше компонент с тем, чтобы использовать полученную информацию для прогнозирования будущих значений ряда или при построении моделей взаимосвязи двух или более временных рядов.
Отдельные наблюдения временного ряда называются уровнями этого ряда.
В экономических приложениях это могут быть, например, объемы производства или продаж каких-либо товаров, цены акций, курсы валют и т.п. Данные могут регистрироваться ежегодно, ежемесячно, ежедневно и т.п.
Основными целями анализа временных рядов является выявление присущих им закономерностей и прогнозирование на будущее (с учетом этих закономерностей).
Временные ряды бывают моментные, интервальные и производные.
Моментные временные ряды характеризуют значения показателя на определенные моменты времени (например, численность людей фирмы на 1 число каждого месяца).
Интервальные ряды характеризуют значения показателя за определенные интервалы времени (например, фонд заработной платы по месяцам).
Производные ряды получаются из средних или относительных величин показателя (например, среднемесячная заработная плата работников фирмы по месяцам).
Уровни ряда могут иметь детерминированные или случайные значения. Ряд последовательных данных о количестве дней в месяце, квартале, году являются примерами рядов с детерминированными значениями.
Прогнозированию подвергаются ряды со случайными значениями уровней. Каждый показатель таких рядов может иметь дискретную или непрерывную величину.
Важное значение для прогнозирования имеет выбор интервалов между соседними уровнями ряда. При слишком большом интервале времени могут быть упущены некоторые закономерности в динамике показателя. При слишком малом – увеличивается объем вычислений, могут появляться несущественные детали в динамике процесса. Выбор интервала времени между уровнями ряда должен решаться конкретно для каждого процесса, причем удобнее иметь равноотстоящие друг от друга уровни.
Уровни временных рядов могут иметь аномальные значения. Появление таких значений может быть вызвано ошибками при сборе, записи или передаче информации – это ошибки технического порядка, или ошибки первого рода. Однако аномальные значения могут отражать реальные процессы, например, скачок курса доллара или падение курса ценных бумаг на фондовом рынке и др. Такие аномальные значения относят к ошибкам второго рода, они не подлежат устранению.
Для выявления аномальных уровней временного ряда может быть использован метод Ирвина.
Пусть имеется временной ряд y1, y2, …yt,…,yn.
Метод Ирвина предполагает использование следующей формулы:
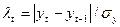 , где σy – среднее квадратическое отклонение временного ряда.
, где σy – среднее квадратическое отклонение временного ряда.
Расчетные значения λ1,λ2,…,λn сравниваются с табличными значениями критерия Ирвина. Если какое-либо из них оказывается больше табличного, то соответствующее значение yt уровня ряда считается аномальным.
Значения критерия Ирвина для уровня значимости a = 0,05 приведены в таблице.
| n | |||||||
| λα | 2,8 | 2,3 | 1,5 | 1,3 | 1,2 | 1,1 | 1,0 |
После выявления аномальных уровней необходимо определить причины их возникновения. Если они вызваны ошибками технического порядка, то они устраняются либо заменой аномальных уровней соответствующими значениями по кривой, аппроксимирующей временной ряд, либо заменой уровней средней арифметической двух соседних уровней ряда.
Ошибки, возникающие из-за воздействия факторов, имеющих объективный характер, устранению не подлежат.
Проверка гипотезы существования тенденции.
Прогнозирование временных рядов целесообразно начинать с построения графика исследуемого показателя. Однако в нем не всегда прослеживается присутствие тренда. Поэтому в этих случаях необходимо выяснить, существует ли тенденция во временном ряду.
Рассмотрим критерий «восходящих и нисходящих» серий, согласно которому тенденция определяется по следующему алгоритму:
1. Для исследуемого временного ряда определяется последовательность знаков, исходя из условий


При этом, если последующее наблюдение равно предыдущему, то учитывается только одно из наблюдений.
2. Подсчитывается число серий v(n). Под серией понимается последовательность подряд расположенных плюсов и минусов, причем один плюс или один минус считается серией.
3. Определяется протяженность самой длинной серии lmax(n).
4. По таблице находится значение l(n).
| Длина ряда n | n ≤ 26 | 26 < n < 153 | 153 < n < 170 |
| Значение l(n) |
5. Если нарушается хотя бы одно из следующих неравенств, то гипотеза об отсутствии тренда отвергается с доверительной вероятностью 0,95:

(Квадратные скобки первого неравенства означают целую часть числа)
Основные показатели динамики.
Для количественной оценки динамики экономических процессов применяют такие статистические показатели, как абсолютные приросты, темпы роста и прироста. Они подразделяются на цепные базисные и средние. Если сравнение уровней временного ряда осуществляется с одним и тем же уровнем, принятым за базу, то показатели называются базисными. Если сравнение осуществляется с переменной базой, причем каждый последующий уровень сравнивается с предыдущим, то вычисленные показатели называют цепными.
Формулы для вычисления абсолютных приростов и темпов прироста представим в виде таблицы, где y1,y2,…,yt,…,yn – уровни временного ряда; n – длина ряда; yб – уровень временного ряда, принятый за базу сравнения.
| Обозначение | Абсолютный прирост | Темп роста | Темп прироста |
| Цепной | 
| 
| 
|
| Базисный | 
| 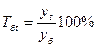
| 
|
| Средний | 
| 
| 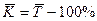
|
Описание динамики ряда средним приростом соответствует его представлению в виде прямой, проходящей через две крайние точки. Для получения прогнозного значения на один шаг вперед достаточно к последнему наблюдению добавить значение среднего абсолютного прироста:
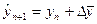 , (1)
, (1)
где yn – значение показателя в n точке временного ряда, yn+1 –прогнозное значение показателя в точке n+1, Δ 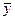 – значение среднего прироста временного ряда.
– значение среднего прироста временного ряда.
Получение прогнозного значения по формуле (1) корректно, если динамика ряда близка к линейной. На такой равномерный характер динамики указывают примерно одинаковые цепные абсолютные приросты.
Использование среднего темпа роста (среднего темпа прироста) для описания динамики развития ряда соответствует его представлению в виде показательной или экспоненциальной кривой, проведенной через две крайние точки. И характерно для процессов, изменение динами которых происходит с постоянным темпом роста. Прогнозное значение на i шагов вперед определяется по формуле
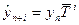 (2),
(2),
где yn+i – прогнозная оценка значения показателя в точке n+i, T – средний темп роста, выраженный в относительных величинах.
Недостатком прогнозирования с использованием среднего прироста и среднего темпа роста является то, что они учитывают начальный и конечный уровни ряда, исключая влияние промежуточных уровней. Тем не менее, они используются как простейшие, приближенные способы прогнозирования.
Автокорреляция уровней временного ряда
При наличии во временном ряде тенденции и циклических колебаний значения каждого последующего уровня ряда зависят от предыдущих. Корреляционную зависимость между последовательными уровнями временного ряда называют автокорреляцией уровней ряда.
Количественно ее можно измерить с помощью линейного коэффициента корреляции между уровнями исходного временного ряда и уровнями этого ряда, сдвинутыми на несколько шагов во времени.
Формула для расчета коэффициента автокорреляции имеет вид:
 (33)
(33)
где

Эту величину называют коэффициентом автокорреляции уровней ряда первого порядка, так как он измеряет зависимость между соседними уровнями ряда t и  .
.
Аналогично можно определить коэффициенты автокорреляции второго и более высоких порядков. Так, коэффициент автокорреляции второго порядка характеризует тесноту связи между уровнями  и
и  и определяется по формуле:
и определяется по формуле:
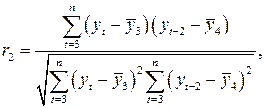 (34)
(34)
где

Число периодов, по которым рассчитывается коэффициент автокорреляции, называют лагом. С увеличением лага число пар значений, по которым рассчитывается коэффициент автокорреляции, уменьшается. Считается целесообразным для обеспечения статистической достоверности коэффициентов автокорреляции использовать правило – максимальный лаг должен быть не больше  .
.
Свойства коэффициента автокорреляции.
1. Он строится по аналогии с линейным коэффициентом корреляции и таким образом характеризует тесноту только линейной связи текущего и предыдущего уровней ряда. Поэтому по коэффициенту автокорреляции можно судить о наличии линейной (или близкой к линейной) тенденции. Для некоторых временных рядов, имеющих сильную нелинейную тенденцию (например, параболу второго порядка или экспоненту), коэффициент автокорреляции уровней исходного ряда может приближаться к нулю.
2. По знаку коэффициента автокорреляции нельзя делать вывод о возрастающей или убывающей тенденции в уровнях ряда. Большинство временных рядов экономических данных содержат положительную автокорреляцию уровней, однако при этом могут иметь убывающую тенденцию.
Последовательность коэффициентов автокорреляции уровней первого, второго и т.д. порядков называют автокорреляционной функцией временного ряда. График зависимости ее значений от величины лага (порядка коэффициента автокорреляции) называется коррелограммой.
Анализ автокорреляционной функции и коррелограммы позволяет определить лаг, при котором автокорреляция наиболее высокая, а следовательно, и лаг, при котором связь между текущим и предыдущими уровнями ряда наиболее тесная, т.е. при помощи анализа автокорреляционной функции и коррелограммы можно выявить структуру ряда.
Если наиболее высоким оказался коэффициент автокорреляции первого порядка, исследуемый ряд содержит только тенденцию. Если наиболее высоким оказался коэффициент автокорреляции порядка  , то ряд содержит циклические колебания с периодичностью в моментов времени. Если ни один из коэффициентов автокорреляции не является значимым, можно сделать одно из двух предположений относительно структуры этого ряда: либо ряд не содержит тенденции и циклических колебаний, либо ряд содержит сильную нелинейную тенденцию, для выявления которой нужно провести дополнительный анализ. Поэтому коэффициент автокорреляции уровней и автокорреляционную функцию целесообразно использовать для выявления во временном ряде наличия или отсутствия трендовой компоненты и циклической (сезонной) компоненты.
, то ряд содержит циклические колебания с периодичностью в моментов времени. Если ни один из коэффициентов автокорреляции не является значимым, можно сделать одно из двух предположений относительно структуры этого ряда: либо ряд не содержит тенденции и циклических колебаний, либо ряд содержит сильную нелинейную тенденцию, для выявления которой нужно провести дополнительный анализ. Поэтому коэффициент автокорреляции уровней и автокорреляционную функцию целесообразно использовать для выявления во временном ряде наличия или отсутствия трендовой компоненты и циклической (сезонной) компоненты.
Моделирование тенденции временного ряда
Распространенным способом моделирования тенденции временного ряда является построение аналитической функции, характеризующей зависимость уровней ряда от времени, или тренда. Этот способ называют аналитическим выравниванием временного ряда.
Поскольку зависимость от времени может принимать разные формы, для ее формализации можно использовать различные виды функций. Для построения трендов чаще всего применяются следующие функции:
линейный тренд:  ;
;
гипербола:  ;
;
экспоненциальный тренд: 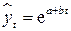 (или
(или  );
);
степенная функция:  ;
;
полиномы различных степеней: 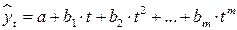 .
.
Параметры каждого из перечисленных выше трендов можно определить обычным МНК, используя в качестве независимой переменной время  , а в качестве зависимой переменной – фактические уровни временного ряда
, а в качестве зависимой переменной – фактические уровни временного ряда 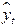 . Для нелинейных трендов предварительно проводят стандартную процедуру их линеаризации.
. Для нелинейных трендов предварительно проводят стандартную процедуру их линеаризации.
Существует несколько способов определения типа тенденции. К числу наиболее распространенных способов относятся качественный анализ изучаемого процесса, построение и визуальный анализ графика зависимости уровней ряда от времени. В этих же целях можно использовать и коэффициенты автокорреляции уровней ряда. Тип тенденции можно определить путем сравнения коэффициентов автокорреляции первого порядка, рассчитанных по исходным и преобразованным уровням ряда. Если временной ряд имеет линейную тенденцию, то его соседние уровни  и
и  тесно коррелируют. В этом случае коэффициент автокорреляции первого порядка уровней исходного ряда должен быть высоким. Если временной ряд содержит нелинейную тенденцию, например, в форме экспоненты, то коэффициент автокорреляции первого порядка по логарифмам уровней исходного ряда будет выше, чем соответствующий коэффициент, рассчитанный по уровням ряда. Чем сильнее выражена нелинейная тенденция в изучаемом временном ряде, тем в большей степени будут различаться значения указанных коэффициентов.
тесно коррелируют. В этом случае коэффициент автокорреляции первого порядка уровней исходного ряда должен быть высоким. Если временной ряд содержит нелинейную тенденцию, например, в форме экспоненты, то коэффициент автокорреляции первого порядка по логарифмам уровней исходного ряда будет выше, чем соответствующий коэффициент, рассчитанный по уровням ряда. Чем сильнее выражена нелинейная тенденция в изучаемом временном ряде, тем в большей степени будут различаться значения указанных коэффициентов.
Выбор наилучшего уравнения в случае, когда ряд содержит нелинейную тенденцию, можно осуществить путем перебора основных форм тренда, расчета по каждому уравнению скорректированного коэффициента детерминации и средней ошибки аппроксимации. Этот метод легко реализуется при компьютерной обработке данных.
Моделирование сезонных колебаний
Простейший подход к моделированию сезонных колебаний – это расчет значений сезонной компоненты методом скользящей средней и построение аддитивной или мультипликативной модели временного ряда.
Общий вид аддитивной модели следующий:
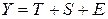 . (35)
. (35)
Эта модель предполагает, что каждый уровень временного ряда может быть представлен как сумма трендовой (T), сезонной (S) и случайной (E) компонент.
Общий вид мультипликативной модели выглядит так:
 . (36)
. (36)
Эта модель предполагает, что каждый уровень временного ряда может быть представлен как произведение трендовой (T), сезонной (S) и случайной (E) компонент.
Выбор одной из двух моделей осуществляется на основе анализа структуры сезонных колебаний. Если амплитуда колебаний приблизительно постоянна, строят аддитивную модель временного ряда, в которой значения сезонной компоненты предполагаются постоянными для различных циклов. Если амплитуда сезонных колебаний возрастает или уменьшается, строят мультипликативную модель временного ряда, которая ставит уровни ряда в зависимость от значений сезонной компоненты.
Построение аддитивной и мультипликативной моделей сводится к расчету значений T, S и E для каждого уровня ряда.
Процесс построения модели включает в себя следующие шаги.
1) Выравнивание исходного ряда методом скользящей средней.
2) Расчет значений сезонной компоненты S.
3) Устранение сезонной компоненты из исходных уровней ряда и получение выровненных данных (T+E) в аддитивной или (T∙E) в мультипликативной модели.
4) Аналитическое выравнивание уровней (T+E) или (T∙E) и расчет значений T с использованием полученного уравнения тренда.
5) Расчет полученных по модели значений (T+E) или (T∙E).
6) Расчет абсолютных и/или относительных ошибок. Если полученные значения ошибок не содержат автокорреляции, ими можно заменить исходные уровни ряда и в дальнейшем использовать временной ряд ошибок E для анализа взаимосвязи исходного ряда и других временных рядов.

