




Для непрерывных случайных величин применяют такую форму закона распределения, как функция распределения. Функция распределения случайной величины Х, называется функцией аргумента х, что случайная величина Х принимает любое значение меньшее х (Х<х) F(х)=Р(Х<х) F(х) - иногда называют интегральной функцией распределения или интегральным законом распределения. Функция распределения обладает следующими свойствами:
1. 0<F(х)<1
2. если х1>х2,то F(х1)>F(х2)
3. 
функция может быть изображена в виде графика. Для непрерывной величины это будет кривая изменяющееся в пределах от 0 до 1, а для дискретной величины - ступенчатая фигура со скачками.С помощью функции распределения легко находится вероятность попадания величины на участок от α до β
Р(α<х<β) рассмотрим 3 события
А - α<Х
В - α<Х<β
С - Х<β
С=А+В
Р(С)=Р(А)+Р(В)
Р(α<х<β)=Р(α)-Р(β)
9.Числовые характеристики дискретных случайных величин Модой (Мо) случайной величины х называется наиболее вероятное ее значение. Это определение строго относится к дискретным случайным величинам. Для непрерывной величины модой называется такое ее значение для которого ф-ция плотности распределения имеет максимальную величину. Медианой (Ме) случайной величины называется такое ее значение для которого окажется ли случайная величина меньше этого значения. Для непрерывной случайной величины медиана это абсцисса точки в которой площадь под кривой распределяется пополам. Для дискретной случайной величины значение медианы зависит от того четное или нечетное значение случайной величины n=2k+1, то Ме=хк+1 (среднее по порядку значение) Если значение случайных величин четное, т.е n=2k, то 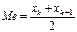
Математическое ожидание случайной величины. Математическим ожиданием случайной величины х (M[x])называется средне взвешенно значение случайной величины причем в качестве весов выступают вероятности появления тех или иных значений. Для дискретной случайной величины

Для непрерывной
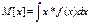
С механической точки зрения мат. Ожидание это абсцисса центра тяжести системы точек расположенных по одноименной оси. Размерность мат. Ожидания совпадает с размерностью самой случайной величины. Математическое ожидание случайной величины всегда больше наименьшего значения и меньше наибольшего
10.Непрерывная случайная величина. Дифференциальные и интегральные функции. Интегральная функция F(x)=P(X < x) Геометрический смысл интегральной функции распределения – это вероятность того, что случайная величина X примет значение, которое на числовой оси лежит левее точки x.
Свойства интегральной функции распределения: Значения интегральной функции распределения принадлежат отрезку [0;1]:.Вероятность того, что случайная величина X примет значение, заключенной в интервале (a,b), равна приращению интегральной функции распределения на этом интервале  Если все возможные значения x случайной величины принадлежат интервалу (a, b), то
Если все возможные значения x случайной величины принадлежат интервалу (a, b), то  , если
, если 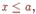
 ,если
,если 

Для описания распределения вероятностей непрерывной случайной величины используется дифференциальная функция распределения. Дифференциальная функция распределения (ДФР) (или плотность вероятности) – это первая производная от интегральной функции.  Интегральная функция распределения является первообразной для дифференциальной функции распределения. Тогда
Интегральная функция распределения является первообразной для дифференциальной функции распределения. Тогда  Вероятность того, что непрерывная случайная величина X примет значение, принадлежащее интервалу (a,b), равна определенному интегралу от дифференциальной функции, взятому в пределах от a до b:
Вероятность того, что непрерывная случайная величина X примет значение, принадлежащее интервалу (a,b), равна определенному интегралу от дифференциальной функции, взятому в пределах от a до b:  Геометрический смысл ДФР состоит в следующем: вероятность того, что непрерывная случайная величина X примет значение, принадлежащее интервалу (a, b), равна площади криволинейной трапеции, ограниченной осью x, кривой распределения f(x) и прямыми x = a и x = b
Геометрический смысл ДФР состоит в следующем: вероятность того, что непрерывная случайная величина X примет значение, принадлежащее интервалу (a, b), равна площади криволинейной трапеции, ограниченной осью x, кривой распределения f(x) и прямыми x = a и x = b 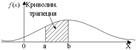
Свойства дифференциальной функции распределения: Дифференциальная функция распределения неотрицательна. Если все возможные значения случайной величины принадлежат интервалу (a, b), то  Так как дифференциальная функция распределения равна f(x)=F’(x), то можно записать
Так как дифференциальная функция распределения равна f(x)=F’(x), то можно записать 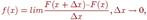 (6.1) т. е. предел отношения вероятности того, что непрерывная случайная величина примет значение, принадлежащее интервалу к длине этого интервала (при), равен значению дифференциальной функции распределения в точке x. Аналогичное (6.1) определение дается в механике для определения плотности массы в точке (если масса распределена вдоль оси X по закону F(x)), поэтому в теории вероятности для дифференциальной функции распределения f(x) часто используется термин "плотность вероятности в точке". На основании (6.1) запишем:
(6.1) т. е. предел отношения вероятности того, что непрерывная случайная величина примет значение, принадлежащее интервалу к длине этого интервала (при), равен значению дифференциальной функции распределения в точке x. Аналогичное (6.1) определение дается в механике для определения плотности массы в точке (если масса распределена вдоль оси X по закону F(x)), поэтому в теории вероятности для дифференциальной функции распределения f(x) часто используется термин "плотность вероятности в точке". На основании (6.1) запишем:  (6.2)Вероятностный смысл дифференциальной функции распределения на основании (6.2) таков: вероятность того, что случайная величина примет значение принадлежащее интервалу приближенно равна произведению плотности вероятности в точке x на длину интервала или (на графике) площади прямоугольника с основанием и высотой f(x). Дифференциальную функцию распределения часто называют законом распределения вероятностей непрерывных случайных величин.
(6.2)Вероятностный смысл дифференциальной функции распределения на основании (6.2) таков: вероятность того, что случайная величина примет значение принадлежащее интервалу приближенно равна произведению плотности вероятности в точке x на длину интервала или (на графике) площади прямоугольника с основанием и высотой f(x). Дифференциальную функцию распределения часто называют законом распределения вероятностей непрерывных случайных величин.
11.Численные характеристики непрерывных случайных величин Математическим ожиданием  Дисперсия
Дисперсия 
12.Мода и медиана случайной величины Модой (Мо) случайной величины х называется наиболее вероятное ее значение. Это определение строго относится к дискретным случайным величинам. Для непрерывной величины модой называется такое ее значение для которого ф-ция плотности распределения имеет максимальную величину. Медианой (Ме) случайной величины называется такое ее значение для которого окажется ли случайная величина меньше этого значения. Для непрерывной случайной величины медиана это абсцисса точки в которой площадь под кривой распределяется пополам. Для дискретной случайной величины значение медианы зависит от того четное или нечетное значение случайной величины n=2k+1, то Ме=хк+1 (среднее по порядку значение) Если значение случайных величин четное, т.е n=2k, то 13.Равномерное распределение Закон равномерного распределения вероятностей непрерывной случайной величины используется при имитационном моделировании сложных систем на ЭВМ как первоначальная основа для получения всех необходимых статистических моделей. При этом, если специально не оговорен закон распределения случайных чисел, то имеют ввиду равномерное распределение. Распределение вероятностей называют равномерным, если на интервале (a,b), которому принадлежат все возможные значения случайной величины, дифференциальная функция распределения имеет постоянное значение, т. е. f(x) = C. Так как  то
то 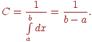 Отсюда закон равномерного распределения аналитически можно записать так:
Отсюда закон равномерного распределения аналитически можно записать так: 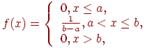 График дифференциальной функции равномерного распределения вероятностей представлен на рис. 6.5
График дифференциальной функции равномерного распределения вероятностей представлен на рис. 6.5  Рис. 6.5. Интегральную функцию равномерного распределения аналитически можно записать так:
Рис. 6.5. Интегральную функцию равномерного распределения аналитически можно записать так: 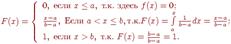 График интегральной функции равномерного распределения вероятностей представлен на рис. 6.6
График интегральной функции равномерного распределения вероятностей представлен на рис. 6.6 
14.Биномиальное распределение. Биномиальным называют законы распределения случайной величины Х числа появления некоторого события в n опытах если вероятность р появления события в каждом опыте постоянна 
Сумма вероятностей представляют собой бином Ньютона 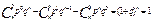
Для определения числовых характеристик в биномиальное распределение подставить вероятность которая определяется по формуле Бернули. 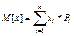

При биномиальном распределении дисперсия равна мат. Ожиданию умноженному на вероятность появления события в отдельном опыте.
15. Распределение Пуассона Когда требуется спрогнозировать ожидаемую очередь и разумно сбалансировать число и производительность точек обслуживания и время ожидания в очереди. Пуассоновским называют закон распределения дискретной случайной величины Х числа появления некоторого события в n-независимых опытах если вероятность того, что событие появится ровно m раз определяется по формуле.
 a=np
a=np
n-число проведенных опытов
р-вероятность появления события в каждом опыте
В теории массового обслуживания параметр пуассоновского распределения определяется по формуле
а=λt, где λ - интенсивность потока сообщений t-время
Необходимо отметить, что пуассоновское распределение является предельным случаем биномиального, когда испытаний стремится к бесконечности, а вероятность появления события в каждом опыте стремится к 0. 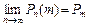 Пуассоновское распределение является единичным распределением для которого такие характеристики как мат. Ожидание и дисперсия совпадают и они равны параметру этого закона распределения а.
Пуассоновское распределение является единичным распределением для которого такие характеристики как мат. Ожидание и дисперсия совпадают и они равны параметру этого закона распределения а.
16. Нормальный закон распределения В начале XIX века нормальное распределение затмило собой все остальные, поскольку в работах Гаусса и Лежандра утверждалось о нормальном законе распределения ошибок наблюдений. Нормальный закон распределения (или распределение Гаусса) задается следующей дифференциальной функцией параметры  .
. 
 (
( - max
- max 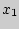 = а -
= а -  , x
, x  = а + - точки перегиба.
= а + - точки перегиба.
17. Правило трех сигм При рассмотрении нормального закона распределения выделяется важный частный случай, известный как правило трех сигм. Запишем вероятность того, что отклонение нормально распределенной случайной величины от математического ожидания меньше заданной величины D:  Если принять D = 3s, то получаем с использованием таблиц значений функции Лапласа:
Если принять D = 3s, то получаем с использованием таблиц значений функции Лапласа:  Т.е. вероятность того, что случайная величина отклонится от своего математического ожидание на величину, большую чем утроенное среднее. На практике считается, что если для какой – либо случайной величины выполняется правило трех сигм, то эта случайная величина имеет нормальное распределение.
Т.е. вероятность того, что случайная величина отклонится от своего математического ожидание на величину, большую чем утроенное среднее. На практике считается, что если для какой – либо случайной величины выполняется правило трех сигм, то эта случайная величина имеет нормальное распределение.
18. Закон больших чисел Неравенство Чебышева На практике сложно сказать какое конкретное значение примет случайная величина, однако, при воздействии большого числа различных факторов поведение большого числа случайных величин практически утрачивает случайный характер и становится закономерным. Этот факт очень важен на практике, т.к. позволяет предвидеть результат опыта при воздействии большого числа случайных факторов.Однако, это возможно только при выполнении некоторых условий, которые определяются законом больших чисел. К законам больших чисел относятся теоремы Чебышева (наиболее общий случай) и теорема Бернулли (простейший случай), которые будут рассмотрены далее.
Рассмотрим дискретную случайную величину Х (хотя все сказанное ниже будет справедливо и для непрерывных случайных величин), заданную таблицей распределения Требуется определить вероятность того, что отклонение значения случайной величины от ее математического ожидания будет не больше, чем заданное число e. Теорема. (Неравенство Чебышева) Вероятность того, что отклонение случайной величины Х от ее математического ожидания по абсолютной величине меньше положительного числа e, не меньше чем 

19. Локальная и интегральная теорема Лапласа Если число опытов достаточно велико но не бесконечно, а вероятность появления события А в каждом опыте не стремится к 0, применяют локальную и интегральную теоремы Лапласа Локальная теорема Лапласа. Вероятность того, что в n независимых испытаниях в каждом из которых вероятность появления события А равно р причем 1>р>0, то это событие наступает ровно m раз приблизительно равна  Интегральная теорема Лапласа. Вероятность того, что в n независимых испытаниях в каждом из которых вероятность появления события А равно р, причем 1>р>0, то событие А наступит не менее m1 раз и не более m2 раза приблизительно равно
Интегральная теорема Лапласа. Вероятность того, что в n независимых испытаниях в каждом из которых вероятность появления события А равно р, причем 1>р>0, то событие А наступит не менее m1 раз и не более m2 раза приблизительно равно
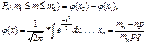
20. Совместное распределение случайных величин Совместной функцией распределения случайных величин, назовем функцию, зависящую от n вещественных переменных, такую, что 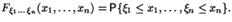 Предложение 4.1 (Без доказательства). Перечислим некоторые свойства функций распределения нескольких случайных величин:
Предложение 4.1 (Без доказательства). Перечислим некоторые свойства функций распределения нескольких случайных величин:  Монотонность по каждой переменной, например,
Монотонность по каждой переменной, например, 
Пределы на ``минус бесконечности'': если в совместной функции распределения зафиксировать все переменные, кроме одной, а оставшуюся переменную устремить к  , то предел равен нулю. Например, для фиксированных
, то предел равен нулю. Например, для фиксированных 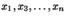 Пределы на ``плюс бесконечности''.Если все переменные устремить к
Пределы на ``плюс бесконечности''.Если все переменные устремить к  ,в пределе получится единица
,в пределе получится единица 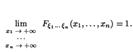 Если зафиксируем все переменные, кроме одной, которую устремим к , получим функцию распределения меньшего набора случайных величин. Например,
Если зафиксируем все переменные, кроме одной, которую устремим к , получим функцию распределения меньшего набора случайных величин. Например, 
21.Линии регрессии, корелляции Если две случайные величины Х и Y имеют в отношении друг друга линейные функции регрессии, то говорят, что величины Х и Y связаны линейной корреляционной зависимостью. Теорема. Если двумерная случайная величина (X, Y) распределена нормально, то Х и Y связаны линейной корреляционной зависимостью.
22. «Хи-квадрат» распределение с f степенями свободы, распределение вероятностей суммы квадратов c^2 = X1^2+...+Xf^2, независимых случайных величин X1,..., Xf, подчиняющихся нормальному распределению с нулевым математическим ожиданием и единичной дисперсией. Функция «Х.-к.» р. выражается интегралом 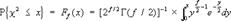
Первые три момента (математическое ожидание дисперсия и третий центральный момент) суммы c2 равны соответственно f, 2f, 8f. Сумма двух независимых случайных величин c1^2 и c2^2, с f^1 и f^2 степенями свободы подчиняется «Х.-к.» р. с f^1 + f^2 степенями свободы. Примерами «Х.-к.» р. могут служить распределения квадратов случайных величин, подчиняющихся Рэлея распределению и Максвелла распределению. В терминах «Х.-к.» р. с чётным числом степеней свободы выражается Пуассона распределение:  Если количество слагаемых f суммы c2 неограниченно увеличивается, то согласно центральной предельной теореме распределение нормированного отношения сходится к стандартному нормальному распределению:
Если количество слагаемых f суммы c2 неограниченно увеличивается, то согласно центральной предельной теореме распределение нормированного отношения сходится к стандартному нормальному распределению:  где
где 
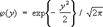 Следствием этого факта является другое предельное соотношение, удобное для вычисления Ff (x) при больших значениях f:
Следствием этого факта является другое предельное соотношение, удобное для вычисления Ff (x) при больших значениях f: 
23. Распределение Стьюдента - распределение получило свое название от псевдонима Student, которым английский ученый Госсет подписывал свои работы по статистике. Пусть  -- независимые стандартные нормальные случайные величины. Распределением Стьюдента с степенями свободы называется распределениеследующей случайной величины:
-- независимые стандартные нормальные случайные величины. Распределением Стьюдента с степенями свободы называется распределениеследующей случайной величины:  (46) Если вспомнить введенную формулой (44) случайную величину
(46) Если вспомнить введенную формулой (44) случайную величину  , то можно сказать, что отношение
, то можно сказать, что отношение 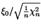 имеет распределение Стьюдента. Плотность этого распределения представляет собой симметричную функцию, задаваемую формулой
имеет распределение Стьюдента. Плотность этого распределения представляет собой симметричную функцию, задаваемую формулой 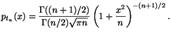 По форме график функции
По форме график функции  напоминает график плотности стандартного нормального закона, но с более медленным убыванием ``хвостов''. При
напоминает график плотности стандартного нормального закона, но с более медленным убыванием ``хвостов''. При  последовательность функций
последовательность функций  сходится к функции
сходится к функции  , которая есть плотность распределения
, которая есть плотность распределения  . Чтобы понять, почему этот факт имеет место, следует обратить внимание на то, что по закону больших чисел знаменатель выражения (46) при
. Чтобы понять, почему этот факт имеет место, следует обратить внимание на то, что по закону больших чисел знаменатель выражения (46) при  стремится к
стремится к 
24. Теорема Фишера для нормальных выборок В этом параграфе мы приводим теорему, впервые доказанную Р.А. Фишером в 1925 г. Она существенно облегчает статистический анализ независимых выборок из нормального распределения. Теорема Фишера. Пусть  независимая выборка из распределения
независимая выборка из распределения 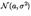 Тогда 1. выборочное среднее
Тогда 1. выборочное среднее  и выборочная дисперсия
и выборочная дисперсия  независимы;
независимы;
2.  имеет
имеет 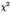 -распределение с
-распределение с  степенью свободы.
степенью свободы.
25. Задачи математической статистики Математическая статистика, раздел математики, посвященный математическим методам систематизации, обработки и использования статистических данных для научных и практических выводов. При этом статистическими данными называются сведения о числе объектов в какой-либо более или менее обширной совокупности, обладающих теми или иными признаками. Предмет и метод математической статистики. Статистическое описание совокупности объектов занимает промежуточное положение между индивидуальным описанием каждого из объектов совокупности, с одной стороны, и описанием совокупности по её общим свойствам, совсем не требующим её расчленения на отдельные объекты, — с другой. По сравнению с первым способом статистические данные всегда в большей или меньшей степени обезличены и имеют лишь ограниченную ценность в случаях, когда существенны именно индивидуальные данные (например, учитель, знакомясь с классом, получит лишь весьма предварительную ориентировку о положении дела из одной статистики числа выставленных его предшественником отличных, хороших, удовлетворительных и неудовлетворительных оценок). С другой стороны, по сравнению с данными о наблюдаемых извне суммарных свойствах совокупности статистические данные позволяют глубже проникнуть в существо дела. Метод исследования, опирающийся на рассмотрение статистических данных о тех или иных совокупностях объектов, называется статистическим. Статистический метод применяется в самых различных областях знания.
26. Выборочный метод Общее понятие о выборочном методе. Множество всех единиц совокупности, обладающих определенным признаком и подлежащих изучению, носит в статистике название генеральной совокупности. На практике по тем или иным причинам не всегда возможно или же нецелесообразно рассматривать всю генеральную совокупность. Тогда ограничиваются изучением лишь некоторой части ее, конечной целью которого является распространение полученных результатов на всю генеральную совокупность, т. е. применяют выборочный метод. Для этого из генеральной совокупности особым образом отбирается часть элементов, так называемая выборка, и результаты обработки выборочных данных (например, средние арифметические значения) обобщаются на всю совокупность. Теоретической основой выборочного метода является закон больших чисел. В силу этого закона при ограниченном рассеивании признака в генеральной совокупности и достаточно большой выборке с вероятностью, близкой к полной достоверности, выборочная средняя может быть сколь угодно близка к генеральной средней. Закон этот, включающий в себя группу теорем, доказан строго математически. Таким образом, средняя арифметическая, рассчитанная по выборке, может с достаточным основанием рассматриваться как показатель, характеризующий генеральную совокупность в целом. Разумеется, не всякая выборка может быть основой для характеристики всей совокупности, к которой она принадлежит. Таким свойством обладают лишь репрезентативные (представительные) выборки, т. е. выборки, которые правильно отражают свойства генеральной совокупности. Существуют способы, позволяющие гарантировать достаточную репрезентативность выборки. Как доказано в ряде теорем математической статистики, таким способом при условии достаточно большой выборки является метод случайного отбора элементов генеральной совокупности, такого отбора, когда каждый элемент генеральной совокупности имеет равный с другими элементами шанс попасть в выборку. Выборки, полученные таким способом, называются случайными выборками. Случайность выборки является, таким образом, существенным условием применения выборочного метода.
27. Точечные оценки параметров генеральной совокупности Оценка параметра — определенная числовая характеристика, полученная из выборки. Точечной называют статистическую оценку, которая определяется одним числом. В качестве точечных оценок параметров генеральной совокупности используются соответствующие выборочные характеристики. Теоретическое обоснование возможности использования этих выборочных оценок для суждений о характеристиках и свойствах генеральной совокупности дают закон больших чисел и центральная предельная теорема Ляпунова. Несмещенной называют точечную оценку, математическое ожидание которой равно оцениваемому параметру при любом объеме выборки. Смещенной называют точечную оценку, математическое ожидание которой не равно оцениваемому параметру. Выборочная средняя является точечной оценкой генеральной средней, т. е. Несмещенной оценкой генеральной средней (математического ожидания)служит выборочная средняя. Генеральная дисперсия имеет две точечные оценки: — выборочная дисперсия, которая исчисляется при н  30; S^2 — исправленная выборочная дисперсия, которая исчисляется при n < 30. Причем в математической статистике доказывается, что
30; S^2 — исправленная выборочная дисперсия, которая исчисляется при n < 30. Причем в математической статистике доказывается, что 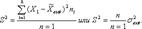 При больших объемах выборки и S^2практически совпадают. Смещенной оценко й генеральной дисперсии служит выборочная дисперсия. Генеральное среднее квадратическое отклонение также имеет две точечные оценки: — выборочное среднее квадратическое отклонение и S — исправленное выборочное среднее квадратическое отклонение. используется для оценивания при п 30, a S для оценивания при п < 30; пpи этом
При больших объемах выборки и S^2практически совпадают. Смещенной оценко й генеральной дисперсии служит выборочная дисперсия. Генеральное среднее квадратическое отклонение также имеет две точечные оценки: — выборочное среднее квадратическое отклонение и S — исправленное выборочное среднее квадратическое отклонение. используется для оценивания при п 30, a S для оценивания при п < 30; пpи этом 
28. Интервальные оценки параметров генеральной совокупности Интервальной оценкой называют оценку, которая определяется двумя числами — концами интервала, который с определенной вероятностью накрывает неизвестный параметр генеральной совокупности. Интервал, содержащий оцениваемый параметр генеральной совокупности, называют доверительным интервалом. Для его определения вычисляется предельная ошибка выборки  , позволяющая установить предельные границы, в которых с заданной вероятностью (надежностью) должен находиться параметр генеральной совокупности.
, позволяющая установить предельные границы, в которых с заданной вероятностью (надежностью) должен находиться параметр генеральной совокупности.
Предельная ошибка выборки равна t-кратному числу средних ошибок выборки. Коэффициент t позволяет установить, насколько надежно высказывание о том, что заданный интервал содержит параметр генеральной совокупности. Если выбирается коэффициент таким, что высказывание в 95% случаев окажется правильным и только в 5% — неправильным, то говорится, что: со статистической надежностью в 95% доверительный интервал выборочной статистики содержит параметр генеральной совокупности. Статистической надежности в 95% соответствует доверительная вероятность — 0,95. В 5% случаев утверждение «параметр принадлежит доверительному интервалу» будет неверным, т. е. 5% задает уровень значимости ( ) или 0,05 вероятность ошибки. Обычно в статистике уровень значимости выбирают таким, чтобы он не превысил 5% (α < 0,05). Доверительная вероятность и уровень значимости дополняют друг друга до 1 (или 100%) и определяют надежность статистического высказывания. С помощью доверительного интервала можно оценить не только генеральную среднюю, но и другие неизвестные параметры генеральной совокупности.
) или 0,05 вероятность ошибки. Обычно в статистике уровень значимости выбирают таким, чтобы он не превысил 5% (α < 0,05). Доверительная вероятность и уровень значимости дополняют друг друга до 1 (или 100%) и определяют надежность статистического высказывания. С помощью доверительного интервала можно оценить не только генеральную среднюю, но и другие неизвестные параметры генеральной совокупности.
29. Для оценки математического ожидания а (генеральной средней) нормально распределенного количественного признака X по выборочной средней  при известном среднем квадратическом отклонении а генеральной совокупности (на практике — при большом объеме выборки, т. е. при п 30) и собственно-случайном повторном отборе формула (5.5) примет вид
при известном среднем квадратическом отклонении а генеральной совокупности (на практике — при большом объеме выборки, т. е. при п 30) и собственно-случайном повторном отборе формула (5.5) примет вид 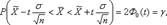 (6.6) где tопределяется по таблицам функции Лапласа (приложение 2) из соотношения
(6.6) где tопределяется по таблицам функции Лапласа (приложение 2) из соотношения  ; — среднее квадратическое отклонение; п — объем выборки (число обследованных единиц).
; — среднее квадратическое отклонение; п — объем выборки (число обследованных единиц). 
30 Для оценки математического ожидания а (генеральной средней) нормально распределенного количественного признака X по выборочной средней при известном среднем квадратическом отклонении генеральной совокупности (при большом объеме выборки, т. е. при п 30) и собственно-случайном бесповторном отборе формула (5.6) примет вид.
 (6.7)
(6.7) 
Для оценки математического ожидания а (генеральной средней) нормально распределенного количественного признака Xпо выборочной средней при неизвестном среднем квадратическом отклонении генеральной совокупности (на практике — при малом объеме выборки, т. е. при п < 30) и собственно-случайном повторном отборе формула (6.6) будет иметь вид  (6.8) где tопределяется по таблицам Стьюдента (приложение 5), по уровню значимости
(6.8) где tопределяется по таблицам Стьюдента (приложение 5), по уровню значимости  и числу степеней свободы k = п - 1; — исправленное выборочное среднее квадратическое отклонение; п — объем выборки.
и числу степеней свободы k = п - 1; — исправленное выборочное среднее квадратическое отклонение; п — объем выборки.  Для оценки математического ожидания а (генеральной средней) нормально распределенного количественного признака X по выборочной средней при неизвестном среднем квадратическом отклонении генеральной совокупности (при малом объеме выборки, т. е. при п < 30) и собственно-случайном бесповторном отборе формула (5.8) примет вид
Для оценки математического ожидания а (генеральной средней) нормально распределенного количественного признака X по выборочной средней при неизвестном среднем квадратическом отклонении генеральной совокупности (при малом объеме выборки, т. е. при п < 30) и собственно-случайном бесповторном отборе формула (5.8) примет вид  (6.9)
(6.9)  Для оценки генеральной доли р нормально распределенного количественного признака по выборочной доле w = m/п (при большом объеме выборки, т. е. при п 30) и собственно-случайном повторном отборе формула (6.5) будет иметь вид
Для оценки генеральной доли р нормально распределенного количественного признака по выборочной доле w = m/п (при большом объеме выборки, т. е. при п 30) и собственно-случайном повторном отборе формула (6.5) будет иметь вид  где tопределяется по таблицам функции Лапласа (приложение 2) из соотношения 2Ф0(t) =; w— выборочная доля; п — объем выборки (число обследованных единиц);
где tопределяется по таблицам функции Лапласа (приложение 2) из соотношения 2Ф0(t) =; w— выборочная доля; п — объем выборки (число обследованных единиц);  Для оценки генеральной доли р нормально распределенного количественного признака по выборочной доле w= т/п (при большом объеме выборки, т. е. при п 30) и собственно-случайном бесповторном отборе формула (5.10) примет вид
Для оценки генеральной доли р нормально распределенного количественного признака по выборочной доле w= т/п (при большом объеме выборки, т. е. при п 30) и собственно-случайном бесповторном отборе формула (5.10) примет вид 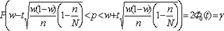 ,(6.11)
,(6.11)  Для оценки генеральной доли р нормально распределенного количественного признака по выборочной доле w ~ т/п (при малом объеме выборки, т. е. при п < 30) и собственно-случайном повторном отборе формула (6.10) примет вид
Для оценки генеральной доли р нормально распределенного количественного признака по выборочной доле w ~ т/п (при малом объеме выборки, т. е. при п < 30) и собственно-случайном повторном отборе формула (6.10) примет вид  где tопределяется по таблицам Стьюдента (приложение 5), по уровню значимости а = 1 - и числу степеней свободы k — п - 1.
где tопределяется по таблицам Стьюдента (приложение 5), по уровню значимости а = 1 - и числу степеней свободы k — п - 1. 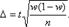 Для оценки генеральной доли р нормально распределенного количественного признака по выборочной доле w= т/п (при малом объеме выборки, т. е. при п < 30) и собственно-случайном бесповторном отборе формула (6.12) будет иметь вид
Для оценки генеральной доли р нормально распределенного количественного признака по выборочной доле w= т/п (при малом объеме выборки, т. е. при п < 30) и собственно-случайном бесповторном отборе формула (6.12) будет иметь вид 

31. Доверительный интервал для дисперсии По закону c 2 ("хи-квадрат") распределена сумма n квадратов независимых нормально распределенных величин, каждая из которых имеет математическое ожидание, равное 0, и дисперсию, равную 1. Очевидно, у этого закона один параметр n, получивший название - "число степеней свободы". Используя элементарные знания теории вероятностей, легко показать, что математическое ожидание Mc 2n = n, дисперсия Dc 2n = 2n, плотность распределения p(c 2n) имеет один максимум, который при n = 1 и n = 2 лежит в точке c 2n = 0, а затем с ростом n сдвигается в сторону увеличения c 2n. При очень больших n (n > 30) распределение, как следует из центральной предельной теоремы, практически неотличимо от нормального с соответствующими значениями матeматического ожидания и дисперсии. Можно показать, что комбинация  Здесь: n - объем выборки; Sx2 - оценка дисперсии результата измерения х, определенная по формуле (1.2); s 2 - "истинная" дисперсия результата измерения, т.е. оцениваемый параметр, который нам не известен; символ " ~ " здесь и в дальнейшем использован для сокращения записи вместо слов "распределено по закону". Рассмотрим на примере, как закон (2.1) можно использовать для построения доверительного интервала для дисперсии. Допустим, что мы создали новую установку для измерения длины волны l в оптическом спектре. Нас интересует оценка случайной погрешности измерений на этой установке, т.е. какова дисперсия значений длин волн, полученных на нашей установке. Осветим установку источником с паспортизованной длиной волны (например,
Здесь: n - объем выборки; Sx2 - оценка дисперсии результата измерения х, определенная по формуле (1.2); s 2 - "истинная" дисперсия результата измерения, т.е. оцениваемый параметр, который нам не известен; символ " ~ " здесь и в дальнейшем использован для сокращения записи вместо слов "распределено по закону". Рассмотрим на примере, как закон (2.1) можно использовать для построения доверительного интервала для дисперсии. Допустим, что мы создали новую установку для измерения длины волны l в оптическом спектре. Нас интересует оценка случайной погрешности измерений на этой установке, т.е. какова дисперсия значений длин волн, полученных на нашей установке. Осветим установку источником с паспортизованной длиной волны (например,
l 0= 632,8 нм) и выполним 5 измерений. Получим выборку из пяти значений: l 1= 633.1 нм, l 2 = 632.9 нм, l 3 = 633.4 нм, l 4 = 633.3 нм, l 5= 632.5 нм. Вычислим согласно (1.1) и (1.2): 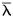 = 633.04 нм, Sl 2 = 0.128 нм2.
= 633.04 нм, Sl 2 = 0.128 нм2.
32. Проверка статистической гипотезы о мат ожидании нормального распределения при известной дисперсии Применение критерия сравнения двух выборочных средних при известных и равных дисперсиях предусматривает вычисление статистики  где
где 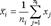 ,
, 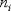 - объем
- объем  -й выборки,
-й выборки, 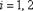 В случае принадлежности наблюдений нормальным законам статистика подчиняется стандартному нормальному закону.
В случае принадлежности наблюдений нормальным законам статистика подчиняется стандартному нормальному закону.
33. Проверка гипотезы о равенстве дисперсии Проверяемая гипотеза о постоянстве дисперсии 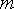 выборок объема
выборок объема  имеет вид:
имеет вид:  . (1) а конкурирующая с ней гипотеза –
. (1) а конкурирующая с ней гипотеза –  (2) где неравенство выполняется, по крайней мере, для одной пары индексов
(2) где неравенство выполняется, по крайней мере, для одной пары индексов  ,
,  Статистика для проверки гипотезы имеет вид
Статистика для проверки гипотезы имеет вид  Степенями свободы для распределения статистики являются число выборок
Степенями свободы для распределения статистики являются число выборок  и.
и.  В [Закс Л.] приводятся таблицы процентных точек для статистик, заимствованные из [Pearson E.S., Hartley H.O.
В [Закс Л.] приводятся таблицы процентных точек для статистик, заимствованные из [Pearson E.S., Hartley H.O.
34.Проверка статистической значимости. Выборочного коэффициента корреляции Проверкой статистической значимости выборочной оценки d параметра D генеральной совокупности называется проверка статистической гипотезы H0: D =0,при конкурирующей гипотезе
H1: D ¹ 0. Если гипотеза H0 отвергается, то оценка d считается статистически значимой. Пусть имеются две случайные величины x и h, определенные на множестве объектов одной и той же генеральной совокупности, причем обе имеют нормальное распределение. Задача заключается в проверке статистической гипотезы об отсутствии корреляционной зависимости между случайными величинами x и h: H0: rxh = 0; H1: rxh ¹ 0. Здесь rxh – коэффициент линейной корреляции.Производится выборка объема n и вычисляется выборочный коэффициент корреляции r. За статистический критерий принимается случайная величина  , которая распределена по закону Стьюдента с n – 2 степенями свободы. Отметим сначала, что все возможные значения выборочного коэффициента корреляции r лежат в промежутке [–1;1]. Очевидно, что относительно большие отклонения в любую сторону значений t от нуля получаются при относительно больших, то есть близких к 1, значениях модуля r. Близкие к 1 значения модуля r противоречат гипотезе H0, поэтому здесь естественно рассматривать двустороннюю критическую область для критерия t. По уровню значимости a и по числу степеней свободы n – 2 находим из таблицы распределения Стьюдента значение tкр. Если модуль выборочного значения критерия tв превосходит tкр, то гипотеза H0 отвергается и выборочный коэффициент корреляции считается статистически значимым. В противном случае, то есть если |tв| < tкр и принимается гипотеза H0, выборочный коэффициент корреляции считается статистически незначимым.
, которая распределена по закону Стьюдента с n – 2 степенями свободы. Отметим сначала, что все возможные значения выборочного коэффициента корреляции r лежат в промежутке [–1;1]. Очевидно, что относительно большие отклонения в любую сторону значений t от нуля получаются при относительно больших, то есть близких к 1, значениях модуля r. Близкие к 1 значения модуля r противоречат гипотезе H0, поэтому здесь естественно рассматривать двустороннюю критическую область для критерия t. По уровню значимости a и по числу степеней свободы n – 2 находим из таблицы распределения Стьюдента значение tкр. Если модуль выборочного значения критерия tв превосходит tкр, то гипотеза H0 отвергается и выборочный коэффициент корреляции считается статистически значимым. В противном случае, то есть если |tв| < tкр и принимается гипотеза H0, выборочный коэффициент корреляции считается статистически незначимым.

