




При вводе данных, они, независимо от своей первоначальной формы представления, автоматически (аппаратно или программно) преобразуются в цепочки двоичных цифр, которые затем обрабатываются.
При выводе данных, они снова преобразуются в удобную для пользования форму, например, в числовую с десятичными числами.
Теоретически один двоичный разряд может служить минимальной единицей представления данных, так как он может иметь два различных значения: 0 и 1. Этот двоичный разряд называется битом. Однако бит – слишком мелкая единица представления данных, поэтому на практике используется более крупная единица, состоящая из восьми битов, и которая называется байтом.
Отдельные двоичные разряды в байте (биты) нумеруются справа налево, начиная с нулевого разряда (рис. 1.4.1).
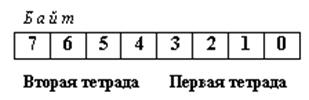
Рис. 1.4.1. Типовая структура байта
В некоторых случая один байт разбивается на две равные части, состоящие из четырех битов. Каждая из этих частей называется тетрадой, причем в первую тетраду входят биты 0…3, а во вторую – биты 4…7.
Понятие байта, как группы взаимосвязанных битов появились в месте с первыми образцами электронно-вычислительной техники. Долгое время оно был машинозависимым, т.е. для разных вычислительных машин длинна байта была разная. Только в конце 60 годов понятие байта стало универсальным, восьмиразрядным и следовательно машинонезависимым.
Во многих случаях для представления данных одного байта оказывается недостаточно, поэтому на практике часто используются их группы, состоящие из двух, четырех, восьми и даже десяти байтов. Все эти группы имеют следующие названия:
два байта (16 битов) – слово
четыре байта (32 бита) – двойное слово
восемь байтов (64 бита) – длинное слово
десять байтов (80 битов) – нет названия.
Все рассмотренные варианты представления данных показаны на рис. 1.4.2.
| Бит | Бит Тетрада Байт Слово Двойное слово Длинное слово | ||||||
| Бит 3(7) | Бит 2(6) | Бит 1(5) | Бит 0(4) | ||||
| Бит 7 | Бит 6 | Бит 5 | Бит 4 | Бит 3 | Бит 2 | Бит 1 | Бит 0 |
| Байт 1 | Байт 0 | ||||||
| Байт 3 | Байт 2 | Байт 1 | Байт 0 | ||||
| Байт 7 | Байт 6 | Байт 5 | Байт 4 | Байт 3 | Байт 2 | Байт 1 | Байт 0 |
Рисунок 1.4.2. Варианты представления данных.
Один байт является не только минимальной единицей представления данных, но также и минимальной единицей измерения данных. Однако существуют и более крупные единицы измерения информации: килобайт (КБ), мегабайт (МБ), гигабайт (ГБ) и терабайт (ТБ), причем:
1 КБ = 210 байт = 1024 байта
1 МБ = 220 байт = 1024 КБ
1 ГБ = 230 байт = 1024 МБ
1 ТБ = 240 байт = 1024 ГБ.
Единицы хранения данных.
При хранении данных необходимо решать одновременно две проблемы:
как сохранить данные в наиболее компактном виде;
как обеспечить к ним удобный и быстрый доступ.
Для обеспечения доступа необходимо, чтобы данные имели упорядоченную структуру, однако в этом случае образуется «паразитная нагрузка» в виде адресных данных. Без них нельзя обеспечить доступ к нужным элементам данных, входящих в структуру.
Поскольку адресные данные также имеют размер и также подлежат хранению, хранить данные в виде мелких единиц так же, как байты, неудобно. Их неудобно хранить и в более крупных единицах (килобайтах, мегабайтах и т.д.), поскольку неполное заполнение одной единицы хранения приводит к неэффективности хранения.
Исходя из этих соображений, в качестве единицы хранения данных принят объект переменной длины, называемый файлом.
Файл – это последовательность произвольного количества байтов, обладающая уникальным собственным именем.
Обычно в одном файле хранят данные, относящиеся к одному типу. В этом случае вид данных определяет тип файла. Поскольку в определении файла нет ограничений на его размер, то, следовательно, можно представить себе файл, имеющий 0 байтов (пустой файл), и файл, имеющий любое количество байтов.
В определении файла особое внимание уделяется имени. Оно фактически несет в себе адресные данные, без которых данные, хранящиеся в файле, не станут информацией.
Кроме функций связанных с адресацией имя файла может хранить и сведения о типе данных заключенных в нем. Для автоматических средств работы с данными это очень важно, так как по имени файла они могут определять адекватный метод извлечения информации из файла. Имя файла состоит из двух частей: собственного имени и расширения.
Собственное имя файла в операционной системе WINDOWS может содержать от 1 до 255 символов, расширение (если оно имеется) – от 1 до 3 символов.
Примеры собственных имен файлов.
Задача 1.1. Лабор. 1.1.
Задача 1.2. Лабор. 1.2.
Расширение, как правило, уточняет происхождение, назначение и принадлежность файла к какой-либо группе. Наиболее распространенными расширениями являются:
EXE, COM – программные файлы - TXT, DOC – текстовые файлы
TXT – текстовый файл - DAT – файл данных
BAT – командный файл - ARJ, ZIP, RAR – архивные файлы
BAK – страховая копия файла - BMP, JPG, GIF – графические файлы
OBY – объектный модуль - XLS - табличный файл EXCEL.
Требование уникальности имени файла очевидно – без этого невозможно обеспечить однозначность доступа к данным. В современных компьютерных системах требование уникальности имени обеспечивается автоматически - создать файл с именем, тождественным с уже имеющимся, невозможно.
Хранение файлов организуется в иерархической структуре, которая называется файловой структурой. В качестве вершины структуры служит имя носителя, на котором хранятся файлы (например, магнитный диск С). Далее файлы группируются в папки (каталоги). Путь доступа к файлу начинается с имени носителя (диска) и включает все папки (каталоги), через которые он проходит. В качестве разделителя используется символ «\» (обратная косая черта). Например,
С\users\informatica\Иванов\задача 1.1.
Уникальность имени файла обеспечивается тем, что полным именем файла считается собственное имя файла вместе с путем доступа к нему. Отсюда следует, что на одном носителе не может быть двух файлов с одинаковыми полными именами. Например,
С\users\informatica\Петров\задача 1.1.
С\users\informatica\Сидоров\задача 1.1.
Здесь в обоих случаях собственные имена файлов одинаково (задача 1.1), но полные имена файлов различные.
О том, как на практике реализуются файловые структуры, рассмотрим в дальнейшем, когда познакомимся с понятием файловой системы.
Кодирование данных
Для автоматизации работы с данными очень важно унифицировать их формы представления. Для этого используются различные приемы кодирования.
Данные считаются закодированными, если они представлены в виде набора цифр, которые называются кодами. Любая компьютерная система обрабатывает данные в закодированном виде, причем для построения кодов используется двоичная система счисления.
Рассмотрим методы кодирования цифровых, текстовых, графических и звуковых данных.
Кодирование цифровых данных заключается в представлении исходных десятичных цифр в виде двоично-десятичных кодов согласно следующей таблице 1.6.1.
Таблица 1.6.1
Двоичные коды десятичных чисел
| Десятичные цифры | Двоичный код | Десятичные цифры | Двоичный код |
Таким образом, десятичное число 375,125(10) в двоично-десятичном коде будет выглядеть следующим образом: 001101110101.000100100101.
В дальнейшем эти двоично-десятичные коды по специальной программе переводятся в двоичную систему счисления.
Для кодирования символьных данных существуют две международные системы:
- Восьмиразрядная система ASCII (AMERICAN STANDARD CODE FOR INFORMATIONAL INTERCHANGE – американский стандартный код информационного обмена).
- Шестнадцати разрядная система кодирования UNICODE
Восьмиразрядная система ASCII осуществляет кодирование в пределах одного байта и позволяет получить 256 кодовых комбинаций (28=256).
Существует специальная кодовая таблица для кодирования символьных данных, которая имеет 16 строк и 16 столбцов (таблица 1.6.2).
Таблица 1.6.2
Кодовая таблица символов
| А | В | С | D | Е | F | |||||||||||
| Управляющие коды | ||||||||||||||||
| Буквы английского алфавита десятичные цифры, знаки арифметических и логических операций | ||||||||||||||||
| А | ||||||||||||||||
| А | Буквы национальных алфавитов (в частности русского) и символы псевдографики | |||||||||||||||
| В | ||||||||||||||||
| С | А | |||||||||||||||
| D | ||||||||||||||||
| Е | ||||||||||||||||
| F | ||||||||||||||||
| А | В | С | D | Е | F |
Примеры:
А- английская – 41(16) = 01000001(2)
А- русская - C0(16) = 11000000(2)
Шестнадцати разрядная система кодирования UNICODE осуществляет кодирование в пределах двух байтов и позволяет иметь 65536 кодовых комбинаций. (216 = 65536)
Несмотря на очевидное преимущество этой системы внедрение ее сдерживалось из-за недостаточных ресурсов памяти персональных компьютеров, так как в системе UNICODE все символы занимают объем памяти в два раза больший, чем в системе ASCII. Однако в настоящее время объем оперативной памяти современных персональных компьютеров достигает 256, 512 и даже 1024 МБ (1 ГБ), и поэтому данная система начинает постепенно внедряться в практику.
Графические данные, хранящиеся в аналоговой (непрерывной) форме на бумаге, фото и кинопленке могут быть преобразованы в цифровой компьютерный формат путем пространственной дискретизации. Это реализуется путем сканирования (сканером), результатом которого является растровое изображение (растр). Растровое изображение состоит из отдельных точек – пикселов (от английского словосочетания picture element – элемент изображения).
Для кодирования цветных изображений применяется принцип декомпозиции произвольного цвета на три основных составляющих: красного – R (RED), зеленого – G (GREEN) и синего B (BLUE). На практике считается, что любой цвет, видимый человеческим глазом, можно получить путем механического смешения этих трех основных цветов. Если для кодирования яркости каждого из этих основных цветовых составляющих использовать также 8-разрядный двоичный код, то можно закодировать по 256 градаций их яркости (28 = 256). Очевидно, что для кодирования цвета одного пиксела необходимо 24 двоичных разряда (три байта). Такая система кодирования называется системой RGB – по первым буквам названий основных цветов (RED – красный, GREEN – зеленый, BLUE – синий). Такая система обеспечивает однозначное кодирование примерно 16,5 миллиона различных цветовых оттенков (224» 16,5 миллиона), что близко к чувствительности человеческого глаза. Система кодирования RGB называется еще полноцветной (TRUE COLOR).

