




Из анализа материала предыдущего раздела следует, что с точки зрения обработки информации каждый нейрон можно считать своеобразным процессором, который суммирует с соответствующими весами сигналы от других нейронов, выполняет нелинейную обработку полученной суммы и формирует результирующий сигнал для передачи связанным с ним нейронам. На основе принципов функционирования биологических нейронов были созданы различные математические модели, реализующие (в большей или меньшей степени) свойства природной нервной клетки. Основу большинства таких моделей составляет структура формального нейрона (ФН) МакКаллока–Питтса (1943 г.), представленная на рис. 2.1, где компоненты входного вектора  (х 1, х 2, …, хN) суммируются с учетом весов wij и сравниваются с пороговым значением wi 0. Выходной сигнал ФН yi определяется как
(х 1, х 2, …, хN) суммируются с учетом весов wij и сравниваются с пороговым значением wi 0. Выходной сигнал ФН yi определяется как
 (2.1)
(2.1)
где в общем случае нелинейная функция преобразования f (ui) называется функцией активации. Коэффициенты wij соответствуют весам синаптических связей: положительное значение wij – возбуждающим, отрицательное wij – тормозящим синапсам, wij = 0 означает отсутствие связи между i – м и j – м нейронами.

Функция активации ФН – это пороговая функция вида
 (2.2)
(2.2)
хотя в принципе набор используемых в моделях нейронов f (u) достаточно разнообразен (табл. 2.1), поскольку их свойства, особенно непрерывность, оказывают значительное влияние на выбор способа обучения нейрона (подбор wij). Наиболее распространенными функциями активации являются пороговая, линейная (в том числе с насыщением) и сигмоидальные – логистическая и гиперболический тангенс (рис. 2.2). Заметим, что с уменьшением a сигмоиды становятся более пологими, а при a®¥ превращаются в пороговую и сигнатурную функции соответственно. В числе их достоинств следует также упомянуть относительную простоту и непрерывность производных и свойство усиливать слабые сигналы лучше, чем большие.
Таблица 2.1
Функции активации нейронов
| Название | Формула | Область значений |
| Линейная | 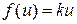
| (–¥, ¥) |
| Полулинейная | 
| (0, ¥) |
| Логистическая (сигмоидальная) | 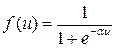
| (0, 1) |
| Гиперболический тангенс (сигмоидальная) | 
| (–1, 1) |
| Экспоненциальная | 
| (0, ¥) |
| Синусоидальная | 
| (–1, 1) |
| Сигмоидальная (рациональная) | 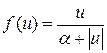
| (–1, 1) |
| Линейная с насыщением | 
| (–1, 1) |
| Пороговая | 
| (0, 1) |
| Модульная | 
| (0, ¥) |
| Сигнатурная | 
| (–1, 1) |
| Квадратичная | 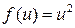
| (0, ¥) |
Помимо выбора f (u) важным фактором является выбор стратегии обучения. При обучении с учителем для каждого входного  должны быть известны ожидаемые выходные сигналы
должны быть известны ожидаемые выходные сигналы  , а подбор wij должен быть организован так, чтобы фактические значения
, а подбор wij должен быть организован так, чтобы фактические значения 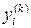 были наиболее близки к
были наиболее близки к  . При обучении без учителя подбор весовых коэффициентов проводится на основании либо конкуренции нейронов между собой, либо с учетом корреляции обучающих и выходных сигналов. В этом случае (в отличие от обучения с учителем) прогнозирование выходных сигналов нейрона на этапе адаптации невозможно. Наиболее распространенные модели нейронов, реализующие каждый из указанных подходов, представлены ниже.
. При обучении без учителя подбор весовых коэффициентов проводится на основании либо конкуренции нейронов между собой, либо с учетом корреляции обучающих и выходных сигналов. В этом случае (в отличие от обучения с учителем) прогнозирование выходных сигналов нейрона на этапе адаптации невозможно. Наиболее распространенные модели нейронов, реализующие каждый из указанных подходов, представлены ниже.

Персептрон
Простой персептрон – это ФН МакКаллока–Питтса со структурой рис. 2.1 и соответствующей стратегией обучения. Функция активации – пороговая, вследствие чего выходные сигналы могут принимать только два значения
 (2.3)
(2.3)
где для выходного сигнала сумматора
 (2.4)
(2.4)
входной вектор дополнен нулевым членом х 0=1, формирующим сигнал поляризации, т.е. =(х 0, х 1, х 2, …, хN).
Обучение – с учителем по правилу персептрона в соответствии с алгоритмом:
1) при начальных значениях wij (выбранных, как правило, случайным образом) на вход подается обучающий , рассчитывается yi и по результатам сравнения yi с известным di уточняются значения весов;
2) если yi = di, то wij = const;
3) если yi = 0, а di = 1, то wij (t +1) = wij (t)+ xj, где t – номер итерации;
4) если yi = 1, а di = 0, то wij (t +1) = wij (t)– xj.
После уточнения весовых коэффициентов подается следующая обучающая пара  и значения wij уточняются заново. Процесс повторяется многократно на всех обучающих выборках до минимизации разницы между всеми yi и di. Вообще говоря, правило персептрона является частным случаем предложенного позднее правила Видроу–Хоффа
и значения wij уточняются заново. Процесс повторяется многократно на всех обучающих выборках до минимизации разницы между всеми yi и di. Вообще говоря, правило персептрона является частным случаем предложенного позднее правила Видроу–Хоффа
 (2.5)
(2.5)
где di, yi могут принимать любые значения.
Минимизация различий между фактическими yi и ожидаемыми di выходными сигналами нейрона может быть представлена как минимизация некоторой (целевой) функции погрешности E (w), чаще всего определяемой как
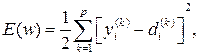 (2.6)
(2.6)
где р – количество обучающих выборок. Оптимизация E (w) по правилу персептрона является безградиентной, при большом р количество циклов обучения и его длительность быстро возрастают без всякой гарантии достижения минимума целевой функции. Устранить эти недостатки можно только при использовании непрерывных f (u) и E (w).
Сигмоидальный нейрон
Структура – ФН МакКаллока–Питтса (рис. 2.1).
Функции активации – униполярный f 1 (табл. 2.1, рис. 2.2 в) или биполярный f 2 (табл. 2.1, рис. 2.2 г) сигмоиды, непрерывно дифференцируемые во всей области определения, причем как  , так и
, так и 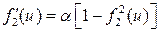 имеют практически одинаковую колоколообразную форму с максимумом при u =0 (рис. 2.3).
имеют практически одинаковую колоколообразную форму с максимумом при u =0 (рис. 2.3).
Обучение – с учителем путем минимизации целевой функции (2.6) с использованием градиентных методов оптимизации, чаще всего алгоритма наискорейшего спуска (АНС). Для одной обучающей пары (р =1) j –я составляющая градиента согласно (2.4), (2.6) имеет вид:
 (2.7)
(2.7)
где  . При этом значения wij уточняются либо дискретным
. При этом значения wij уточняются либо дискретным
 (2.8)
(2.8)
либо аналоговым способом из решения разностного уравнения
 (2.9)
(2.9)
где h, m Î (0,1) играют роль коэффициентов обучения, от которых сильно зависит его эффективность. Наиболее быстрым (но одновременно наиболее трудоемким) считается метод направленной минимизации с адаптивным выбором значений h, m.

Следует отметить, что применение градиентных методов обучения нейрона гарантирует достижение только локального экстремума, который для полимодальной E (w) может быть достаточно далек от глобального минимума. В этом случае результативным может оказаться обучение с моментом (ММ)
 (2.10)
(2.10)
где 0<a<1 – коэффициент момента, или использование стохастических методов оптимизации.

