




Koncentrací hodnot číselné proměnné rozumíme hustější nakupení hodnot této proměnné v některé části variačního rozpětí oproti jiným částem tohoto variačního rozpětí. Máme dva základní druhy koncentrace, a tedy dva základní způsoby charakterizování koncentrace.
První druh koncentrace spočívá ve srovnání stupně nahuštěnosti malých hodnot sledované proměnné se stupněm nahuštěnosti velkých hodnot dané proměnné. Stejný stupeň koncentrace malých i velkých hodnot sledované proměnné značí zpravidla symetričnost tvaru rozdělení četností. Větší stupeň koncentrace malých hodnot v porovnání se stupněm koncentrace velkých hodnot značí zpravidla kladně sešikmený tvar rozdělení četností. Větší stupeň koncentrace velkých hodnot v porovnání se stupněm koncentrace malých hodnot značí zpravidla záporně sešikmený tvar rozdělení četností. Charakterizování koncentrace je zde vázáno na charakterizování šikmosti, někdy říkáme kososti, rozdělení četností.
Druhý druh koncentrace spočívá ve srovnání stupně nahuštěnosti hodnot sledované proměnné, které mají prostřední velikost, se stupněm nahuštěnosti ostatních hodnot dané proměnné. Stejný stupeň koncentrace prostředních hodnot i ostatních hodnot sledované proměnné značí zpravidla plochost tvaru rozdělení četností. Větší stupeň koncentrace prostředních hodnot v porovnání se stupněm koncentrace ostatních hodnot značí zpravidla špičatý tvar rozdělení četností. Charakterizování koncentrace je zde vázáno na charakterizování špičatosti, někdy říkáme excesu, rozdělení četností. V případě špičatého rozdělení četností vrchol tohoto rozdělení četností velmi výrazně vystupuje.
Charakteristiky šikmosti
Je-li rozdělení četností souměrné, viz obrázek 1.7, platí
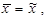
| (1.98) |
tj. aritmetický průměr se rovná mediánu, polovina malých hodnot sledované proměnné x je nahuštěna v rámci první poloviny variačního rozpětí a polovina velkých hodnot sledované proměnné x je nahuštěna v rámci druhé poloviny variačního rozpětí. Je zde stejný počet podprůměrných a nadprůměrných hodnot.
Je-li rozdělení četností nesouměrné sešikmené kladně, viz obrázek 1.8, platí
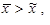
| (1.99) |
tj. aritmetický průměr je větší než medián, polovina malých hodnot sledované proměnné x je nahuštěna v rámci menší části variačního rozpětí a polovina velkých hodnot sledované proměnné x je nahuštěna v rámci větší části variačního rozpětí. Je zde větší počet hodnot podprůměrných než nadprůměrných.
Je-li rozdělení četností nesouměrné sešikmené záporně, viz obrázek 1.9, platí
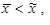
| (1.100) |
tj. aritmetický průměr je menší než medián, polovina malých hodnot sledované proměnné x je nahuštěna v rámci větší části variačního rozpětí a polovina velkých hodnot sledované proměnné x je nahuštěna v rámci menší části variačního rozpětí. Je zde větší počet hodnot nadprůměrných než podprůměrných.
K měření šikmosti používáme různé charakteristiky šikmosti vycházející vesměs ze součtu třetích mocnin odchylek hodnot sledované proměnné od jejich aritmetického průměru. Je-li hodnota charakteristiky šikmosti nulová, jedná se o souměrné rozdělení četností a stejný stupeň koncentrace malých a velkých hodnot sledované proměnné. Je-li hodnota charakteristiky šikmosti kladná, jedná se o nesouměrné kladně sešikmené rozdělení četností a větší stupeň koncentrace malých hodnot sledované proměnné než velkých hodnot této proměnné. Je-li hodnota charakteristiky šikmosti záporná, jedná se o nesouměrné záporně sešikmené rozdělení četností a větší stupeň koncentrace velkých hodnot sledované proměnné než malých hodnot této proměnné.
Momentovou charakteristikou šikmosti rozdělení četností je třetí normovaný moment (1.93), značí se zpravidla a. Z n hodnot x 1, x 2,..., xn, které nemusí být uspořádány, se vypočítá
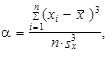
| (1.101) |
jsou-li hodnoty proměnné setříděny do tabulky rozdělení četností, vypočteme a
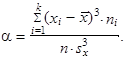
| (1.102) |
Charakteristiku šikmosti (1.101) a (1.102) často stručně nazýváme pouze šikmost. V případě souměrného rozdělení četností nabývá nulové hodnoty, v případě nesouměrného kladně sešikmeného rozdělení četností nabývá kladné hodnoty a v případě nesouměrného záporně sešikmeného rozdělení četností nabývá záporné hodnoty.
Často je charakteristika šikmosti různě modifikována, ale vztah (1.101) je základem momentového měření šikmosti rozdělení četností. Šikmost, kterou budeme značit a\, je definována jako
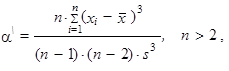
| (1.103) |
kde směrodatná odchylka je definována jako kladná druhá odmocnina ze vztahu (1.38)
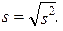
| (1.104) |
K měření šikmosti rozdělení četností se rovněž používá standardizovaná šikmost, kterou budeme značit a\ \ a která je definována jako
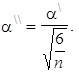
| (1.105) |
Dále je možno k měření šikmosti rozdělení četností použít velmi jednoduchou charakteristiku šikmosti, kterou označíme a\ \ \ a která je definována jako
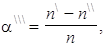
| (1.106) |
| kde: | n n \ n \ \ | je celkový počet hodnot sledované proměnné, tj. rozsah statistického souboru, je počet hodnot sledované proměnné menších než aritmetický průměr, je počet hodnot sledované proměnné větších než aritmetický průměr. |
V případě souměrného rozdělení četností nabude charakteristika šikmosti (1.106) nulové hodnoty, v případě nesouměrného kladně sešikmeného rozdělení četností nabude kladné hodnoty a v případě nesouměrného záporně sešikmeného rozdělení četností nabude záporné hodnoty.
Charakteristiky špičatosti
Rozdělení četností číselné proměnné se mohou lišit svojí špičatostí, jejíž podstatou je větší stupeň nahuštěnosti hodnot prostřední velikosti ve srovnání se stupněm nahuštěnosti ostatních hodnot sledované proměnné. Rozdělení četností je špičatější, tj. má výraznější vrchol, jestliže polovina prostředních hodnot sledované proměnné x je nahuštěna v rámci značně menší části variačního rozpětí než zbývající polovina hodnot sledované proměnné. Velká špičatost představuje vysoký stupeň koncentrace hodnot sledované proměnné v blízkosti středních hodnot. O špičatosti rozdělení četností se velmi často hovoří jako o excesu, což pochází z latinského slova „excedere“, které znamená „vystupovat“, neboť ve špičatém rozdělení četností vrchol velmi výrazně vystupuje.
K měření špičatosti používáme různé charakteristiky špičatosti vycházející vesměs ze součtu čtvrtých mocnin odchylek hodnot sledované proměnné od jejich aritmetického průměru. Vyšší hodnota těchto charakteristik špičatosti znamená špičatější rozdělení četností a vyšší stupeň koncentrace prostředních hodnot sledované proměnné v porovnání s ostatními hodnotami dané proměnné.
Momentovou charakteristikou špičatosti rozdělení četností je čtvrtý normovaný moment (1.94) zmenšený o 3, značí se zpravidla b. Z n hodnot x 1, x 2,..., xn, které nemusí být uspořádány, se vypočítá
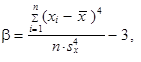
| (1.107) |
jsou-li hodnoty proměnné setříděny do tabulky rozdělení četností, vypočteme b
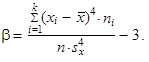
| (1.108) |
Charakteristiku špičatosti (1.107) a (1.108) často stručně nazýváme pouze špičatost nebo exces. Je-li rozdělení četností stejně špičaté jako tzv. normované normální rozdělení (viz část věnovaná počtu pravděpodobnosti tohoto textu), nabývá uvedená charakteristika nulové hodnoty, je-li rozdělení četností špičatější než normované normální rozdělení, nabývá uvedená charakteristika kladné hodnoty, je-li rozdělení četností plošší než normované normální rozdělení, nabývá uvedená charakteristika záporné hodnoty.
Charakteristika špičatosti je často různě modifikována, ale vztah (1.107) je základem momentového měření špičatosti rozdělení četností. Špičatost, kterou budeme značit b\, je definována jako
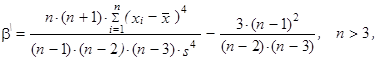
| (1.109) |
kde směrodatná odchylka je opět definována vztahem (1.104).
K měření špičatosti rozdělení četností se rovněž používá standardizovaná špičatost, kterou budeme značit b\ \ a která je definována jako
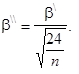
| (1.110) |
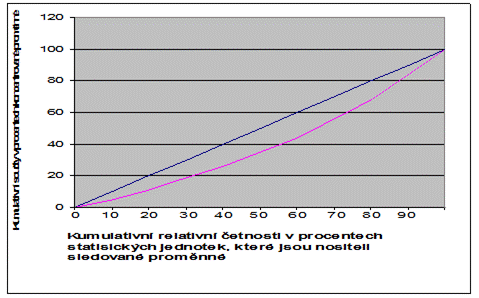
Před momentovými i dalšími charakteristikami špičatosti se často v ekonomických aplikacích upřednostňují některá názornější měření stupně koncentrace. Často používaným nástrojem grafického znázornění a měření stupně koncentrace číselné proměnné je Lorenzova křivka. Lorenzovu křivku, viz obrázek 1.18, zakreslujeme do pravoúhlého grafu se dvěma stupnicemi, z nichž každá je od 0 % do 100 %. Na vodorovné ose jsou kumulativní relativní četnosti v procentech statistických jednotek, které jsou nositeli sledované proměnné, na svislé ose jsou naopak kumulativní součty v procentech koncentrované proměnné. Souřadnicemi bodů na Lorenzově křivce jsou tedy kumulativní relativní četnosti v procentech statistických jednotek, které jsou nositeli zkoumané proměnné, a jim odpovídající kumulativní součty v procentech koncentrované proměnné. V případě nulové koncentrace splývá Lorenzova křivka s úhlopříčkou, což znamená, že na každou statistickou jednotku připadá stejně z celkového součtu hodnot sledované proměnné. Čím se Lorenzova křivka více prohýbá, tím větší je koncentrace zkoumané proměnné, tj. koncentrace poměrně velké části z celkového součtu hodnot sledované proměnné do malého počtu statistických jednotek. V případě nejvyšší možné koncentrace se Lorenzova křivka promění ve dvě navzájem na sebe kolmé úsečky, tj. splyne s vodorovnou osou a pravým okrajem grafu, což znamená, že úhrnný součet hodnot zkoumané proměnné je soustředěn pouze do jedné statistické jednotky. Charakteristikou koncentrace je potom poměr obsahu plochy mezi úhlopříčkou a Lorenzovou křivkou k ploše celého trojúhelníku pod úhlopříčkou. Při nulové koncentraci nabývá tato charakteristika hodnoty nula, při nejvyšší možné koncentraci nabývá tato charakteristika hodnoty jedna, tj. pohybuje se od nuly do jedné.
Obrázek 1.18
Příklad 1.26
Máme k dispozici následující údaje týkající se počtu ztracených kreditů u 51 studentů druhého ročníku jisté vysoké školy, které byly zjištěny po zkoušce ze statistiky, viz tabulka 1.40.
| Tabulka 1.40 | |||||||||
| Číslo studenta | Počet ztracených kreditů | Číslo studenta | Počet ztracených kreditů | Číslo studenta | Počet ztracených kreditů | ||||
Na základě údajů tabulky 1.40 posuďte, na kolik je rozdělení počtu ztracených kreditů u 51 studentů zešikmené a rozhodněte, zda je rozdělení počtu ztracených kreditů u 51 studentů z hlediska tvaru rozdělení špičaté nebo ploché.
Řešení:
Jedná se o statistický znak počet ztracených kreditů studenta, statistickou jednotkou je student a statistický soubor je soubor zjišťovaných 51 studentů. Rozsah statistického souboru je tedy
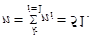
|
Máme zde následujících k = 9 obměn statistického znaku: x 1 = 0, žádný kredit neztratilo n 1 = 6 studentů, x 2 = 1, jeden kredit ztratilo rovněž n 2 = 6 studentů, x 3 = 2, dva kredity ztratilo n 3 = 8 studentů, x 4 = 3, tři kredity ztratilo n 4 = 5 studentů, x 5 = 4, čtyři kredity ztratilo rovněž n 5 = 5 studentů, x 6 = 5, pět kreditů ztratili n 6 = 4 studenti, x 7 = 6, šest kreditů ztratilo n 7 = 7 studentů, x 8 = 7, sedm kreditů ztratilo n 8 = 6 studentů a x 9 = 8, osm kreditů ztratili n 9 = 4 studenti. Výpočty uspořádáme do tabulky 1.41.
| Tabulka 1.41 | ||||||||
| Počet ztracených kreditů | Počet studentů | |||||||
| xi | ni | 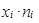
| 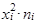
| |||||
| 0 ∙ 6 = 1 ∙ 6 = 2 ∙ 8 = 3 ∙ 5 = 4 ∙ 5 = 5 ∙ 4 = 6 ∙ 7 = 7 ∙ 6 = 8 ∙ 4 = | 02 ∙ 6 = 12 ∙ 6 = 22 ∙ 8 = 32 ∙ 5 = 42 ∙ 5 = 52 ∙ 4 = 62 ∙ 7 = 72 ∙ 6 = 82 ∙ 4 = | |||||||
| Celkem | 1 065 | |||||||
S využitím (1.13) vypočteme průměrný počet ztracených kreditů na jednoho studenta
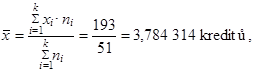
|
s využitím (1.48) vypočteme rozptyl počtu ztracených kreditů
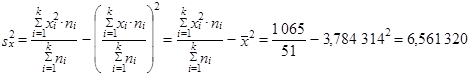
|
a podle (1.60) vypočteme směrodatnou odchylku počtu ztracených kreditů
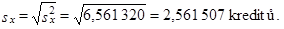
|
V tabulce 1.42 si připravíme další výpočty, budeme potřebovat ještě sloupce
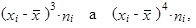
|
kde za 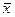 dosadíme již vypočtené
dosadíme již vypočtené 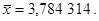
| Tabulka 1.42 | |||||||
| Počet ztracených kreditů | Počet studentů | ||||||
| xi | ni | 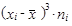
| |||||
| (0 − 3,784 314)3 ∙ 6 = (1 − 3,784 314)3 ∙ 6 = (2 − 3,784 314)3 ∙ 8 = (3 − 3,784 314)3 ∙ 5 = (4 − 3,784 314)3 ∙ 5 = (5 − 3,784 314)3 ∙ 4 = (6 − 3,784 314)3 ∙ 7 = (7 − 3,784 314)3 ∙ 6 = (8 − 3,784 314)3 ∙ 4 = | − 325,171 702 − 129,510 770 − 45,446 855 − 2,412 348 0,050 169 7,186 613 76,141 720 199,513 439 299,684 829 | ||||||
| Celkem | 80,035 095 | ||||||
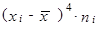
| ||||
| (0 − 3,784 314)4 ∙ 6 = (1 − 3,784 314)4 ∙ 6 = (2 − 3,784 314)4 ∙ 8 = (3 − 3,784 314)4 ∙ 5 = (4 − 3,784 314)4 ∙ 5 = (5 − 3,784 314)4 ∙ 4 = (6 − 3,784 314)4 ∙ 7 = (7 − 3,784 314)4 ∙ 6 = (8 − 3,784 314)4 ∙ 4 = | 1 230,551 823 360,598 649 81,091 460 1,892 038 0,010 821 8,736 664 168,706 142 641,572 573 1 263,377 137 | |||
| 3 756,537 307 |
Z tabulky 1.42 získáváme
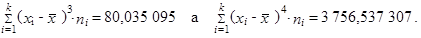
|
Nyní již vypočteme s využitím (1.102) šikmost
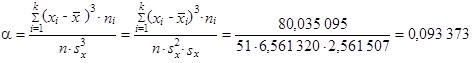
|
a s využitím (1.108) špičatost
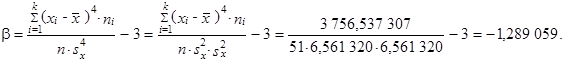
|
Z vypočtené hodnoty α = 0,093 373 lze usuzovat, že rozdělení četností počtu ztracených kreditů je mírně kladně zešikmené, což představuje, že počty ztracených kreditů u sledovaného souboru studentů jsou spíše menší než větší. Z vypočtené hodnoty β = − 1,289 059 můžeme usuzovat, že rozdělení četností počtu ztracených kreditů je poměrně ploché. Polygon četností graficky znázorňující rozdělení četností počtu ztracených kreditů představuje obrázek 1.19.
Obrázek 1.19

Cvičení
1. Výsledky zkoušky z matematiky za 1.ročník jsou uvedeny v tabulce 1.43. Určete šikmost a špičatost tohoto souboru.
| Tabulka 1.43 | |
| Číslo studenta | Hodnocení studentů |
2. Určete šikmost a špičatost následujícího statistického souboru, viz tabulka 1.44.
| Tabulka 1.44 | |
| Pořadové číslo | Hodnota |
3. Určete šikmost a špičatost následujícího statistického souboru, viz tabulka 1.45.
| Tabulka 1.45 | |
| Pořadové číslo | Hodnota |
4. Tabulka 1.46 obsahuje denní počty vyrobených nákladních vozů za jeden měsíc roku.
| Tabulka 1.46 | |||||||||
Určete modus, kvartily, aritmetický průměr, rozptyl, šikmost a špičatost.
Výsledky
1.
α = 1,153
β = -1,603
2.
α = 0,676
β = -1,110
3.
α = -0,153
β =.-0,659
4.
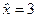
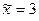
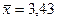
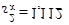
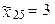
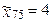
α = 0,0904
β = -1,12
1.6.5 Korelační koeficient
K měření síly (těsnosti, intenzity) lineární závislosti dvou číselných proměnných x a y lze využít různé statistické charakteristiky, mezi nejčastěji používané patří korelační koeficient. Korelační koeficient proměnných x a y budeme značit rxy a je to poměr kovariance (1.55) těchto proměnných k součinu jejich směrodatných odchylek (1.60)
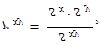
| (1.111) |
vztah (1.111) lze ještě rozepsat
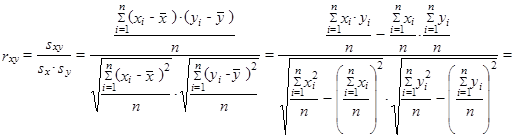
|
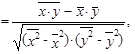
|
tj. pro numerický výpočet korelačního koeficientu můžeme použít vzorec
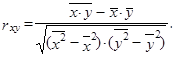
| (1.112) |
Korelační koeficient může nabývat hodnot z intervalu 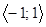 . Znaménko hodnoty korelačního koeficientu určuje směr závislosti. V případě přímé závislosti je rxy > 0, v případě nepřímé závislosti je rxy < 0. Z absolutní hodnoty korelačního koeficientu usuzujeme na sílu závislosti obou proměnných. Jestliže pro všechny dvojice hodnot (xi; yi) platí vztah yi = a + b xi, a ≠ 0. b ≠ 0, i = 1, 2, …, n, mezi proměnnými x a y existuje funkční lineární závislost a absolutní hodnota korelačního koeficientu je v takovém případě rovna jedné. Čím více se liší závislost proměnných x a y od funkční lineární závislosti, tím je absolutní hodnota korelačního koeficientu bližší nule. Proměnné x a y jsou lineárně nezávislé, jestliže rxy = 0, říkáme, že jsou nekorelované. Z hlediska toho, zda je absolutní hodnota korelačního koeficientu blízká nule či jedné, hovoříme o slabě či silně korelovaných proměnných.
. Znaménko hodnoty korelačního koeficientu určuje směr závislosti. V případě přímé závislosti je rxy > 0, v případě nepřímé závislosti je rxy < 0. Z absolutní hodnoty korelačního koeficientu usuzujeme na sílu závislosti obou proměnných. Jestliže pro všechny dvojice hodnot (xi; yi) platí vztah yi = a + b xi, a ≠ 0. b ≠ 0, i = 1, 2, …, n, mezi proměnnými x a y existuje funkční lineární závislost a absolutní hodnota korelačního koeficientu je v takovém případě rovna jedné. Čím více se liší závislost proměnných x a y od funkční lineární závislosti, tím je absolutní hodnota korelačního koeficientu bližší nule. Proměnné x a y jsou lineárně nezávislé, jestliže rxy = 0, říkáme, že jsou nekorelované. Z hlediska toho, zda je absolutní hodnota korelačního koeficientu blízká nule či jedné, hovoříme o slabě či silně korelovaných proměnných.
Závěrem je třeba zdůraznit, že korelační koeficient měří sílu lineární závislosti dvou proměnných a nikoliv sílu jejich závislosti obecně, z čehož plyne, že jestliže je absolutní hodnota korelačního koeficientu blízká jedné, jedná se o silně závislé proměnné. Je-li absolutní hodnota korelačního koeficientu blízká nule, nelze tyto proměnné ještě prohlásit za slabě závislé, neboť mohou být silně závislé jinak než lineárně.
Příklad 1.27
Ve výzkumu byli respondenti požádáni, aby udali výši svého čistého měsíčního příjmu a odhadli, kolik hodin týdně v průměru pracují. Výsledky byly získány u deseti majitelů firem s jedním zaměstnancem a jsou uvedeny v tabulce 1.47. Vypočtěte korelační koeficient a výsledky interpretujte.
| Tabulka 1.47 | ||||||||||||
| Majitel firmy | 1. | 2. | 3. | 4. | 5. | 6. | 7. | 8. | 9. | 10. | ||
| Týdenní počet odpracovaných hodin | ||||||||||||
| Měsíční příjem (v tis. Kč) | 21,6 | 27,3 | 24,0 | 27,6 | 33,9 | 36,6 | 35,4 | 25,5 | 18,9 | 19,2 | ||
Řešení:
Rozsah výběru n = 10 majitelů firem. Označme x proměnnou průměrný týdenní počet odpracovaných hodin a proměnnou y označíme čistý měsíční příjem. Údaje z tabulky 1.47 uspořádáme do následující tabulky 1.48 umožňující využití uvedených pomocných výpočtů.
| Tabulka 1.48 | |||||||
| Majitel firmy | Týdenní počet hodin | Měsíční příjem | Pomocné výpočty | ||||
| i | xi | yi | xi 2 | yi 2 | xi ∙ yi | ||
| 21,6 27,3 24,0 27,6 33,9 36,6 35,4 25,5 18,9 19,2 | 3 721 3 600 4 225 3 025 4 225 2 116 3 600 2 809 2 500 4 225 | 466,56 745,29 576,00 761,76 1 149,21 1 339,56 1 253,16 650,25 357,21 368,64 | 1 317,6 1 638,0 1 560,0 1 518,0 2 203,5 1 683,6 2 124,0 1 351,5 945,0 1 248,0 | ||||
| Celkem | 270,0 | 34 046 | 7 667,64 | 15 589,2 |
Vypočteme
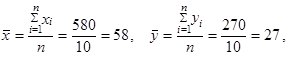
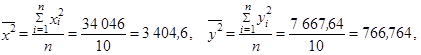
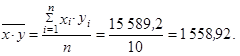
Pro výpočet korelačního koeficientu použijeme vztah (1.112)
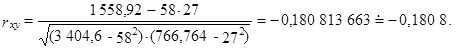
V tomto statistickém souboru majitelů firem se projevila velice slabá nepřímá lineární závislost obou proměnných. Vzhledem k nízké absolutní hodnotě korelačního koeficientu lze konstatovat, že se v tomto statistickém souboru příjmy majitelů firem při růstu pracovního zatížení prakticky nezvětšovaly ani nezmenšovaly.
Cvičení
1. Zkouška z matematiky má dvě části. Ústní a písemnou. Obě části se hodnotí nezávisle na sobě pomocí bodového ohodnocení v rozsahu 0 až 20 bodů. Výsledky zkoušek jsou uvedeny v tabulce 1.49.
| Tabulka 1.49 | |||||||||||||
| Číslo studenta | |||||||||||||
| Výsledek písemné části | |||||||||||||
| Výsledek ústní části |
Vypočtěte korelační koeficient a výsledky interpretujte.
2. Pro statistický soubor uvedený v tabulce 1.50 vypočtěte koeficient korelace.
| Tabulka 1.50 | |||||||||||
| Pořadové číslo | |||||||||||
| x | 4,6 | 4,9 | 6,1 | 5,3 | 4,1 | 6,2 | 7,3 | 5,1 | 4,1 | 4,3 | |
| y | |||||||||||
3. Pro statistický soubor uvedený v tabulce 1.51 vypočtěte koeficient korelace.
| Tabulka 1.51 | ||||||||
| Pořadové číslo | ||||||||
| x | 2,3 | 4,1 | 1,8 | 2,3 | 3,2 | 4,7 | ||
| y |
4. Pro statistický soubor uvedený v tabulce 1.52 vypočtěte koeficient korelace.
| Tabulka 1.52 | ||||||||||
| Pořadové číslo | ||||||||||
| x | 2,3 | 4,1 | 1,8 | 2,3 | 3,2 | 4,7 | ||||
| y | ||||||||||
Výsledky
1. 0,848; relativně silná lineární závislost
2. 0,839
3. -0,604
4. -0,123

