




Příklad 1.6
U 38 domácností jsme sledovali měsíční výdaje za potraviny (v Kč). Zjištěné údaje poskytuje tabulka 1.18.
| Tabulka 1.18 | |||||||||
| Číslo domácnosti | Měsíční výdaje za potraviny | Číslo domácnosti | Měsíční výdaje za potraviny | Číslo domácnosti | Měsíční výdaje za potraviny | ||||
| 9 921 9 119 12 358 7 793 7 073 5 925 8 115 10 075 11 455 7 068 6 038 9 844 9 005 | 10 057 9 454 6 879 7 580 8 894 7 435 6 299 9 271 8 045 9 442 10 400 10 283 7 278 | 8 451 9 608 8 860 12 097 7 441 7 036 5 659 6 825 7 231 6 089 9 484 8 857 | |||||||
Vypočtěte kvartily a kvartilové rozpětí.
Řešení:
Hodnoty měsíčních výdajů za potraviny nejprve uspořádáme podle velikosti vzestupně, tj. od nejmenší hodnoty po největší, viz tabulka 1.19.
| Tabulka 1.19 | ||||||||||
| Pořadí | 1. | 2. | 3. | 4. | 5. | 6. | 7. | 8. | ||
| Hodnota | 5 659 | 5 925 | 6 038 | 6 089 | 6 299 | 6 825 | 6 879 | 7 036 | ||
| Pořadí | 9. | 10. | 11. | 12. | 13. | 14. | 15. | 16. |
| Hodnota | 7 068 | 7 073 | 7 231 | 7 278 | 7 435 | 7 441 | 7 580 | 7 793 |
| Pořadí | 17. | 18. | 19. | 20. | 21. | 22. | 23. | 24. |
| Hodnota | 8 045 | 8 115 | 8 451 | 8 857 | 8 860 | 8 894 | 9 005 | 9 119 |
| Pořadí | 25. | 26. | 27. | 28. | 29. | 30. | 31. | 32. |
| Hodnota | 9 271 | 9 442 | 9 454 | 9 484 | 9 608 | 9 844 | 9 921 | 10 057 |
| Pořadí | 33. | 34. | 35. | 36. | 37. | 38. | ||
| Hodnota | 10 075 | 10 283 | 10 400 | 11 455 | 12 097 | 12 358 |
Rozsah výběru (počet statistických jednotek) n = 38 domácností.
Nejprve vypočteme dolní a horní kvartil. K výpočtu dolního kvartilu opět použijeme vztah (1.9), kdy 100 p = 25, tedy p = 0,25
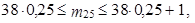
|
tedy
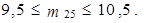
|
Získáváme, že m 25 = 10. Z tabulky 1.19 zjistíme, že 10. nejmenší hodnota je 7 073 Kč. Dolní kvartil tedy je
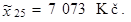
|
Obdobným způsobem vypočteme i horní kvartil, kdy 100 p = 75, tedy p = 0,75
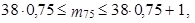
|
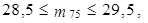
|
tedy m 75 = 29. Z tabulky 1.19 plyne, že 29. nejmenší hodnota je 9 608 Kč. Horní kvartil je
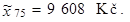
|
Zbývá výpočet mediánu, kdy 100 p = 50, tedy p = 0,5
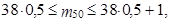
|
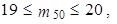
|
z tabulky 1.19 je zřejmé, že 19. nejmenší hodnota je 8 451 Kč a 20. nejmenší hodnota je 8 857 Kč. Medián vypočteme jako aritmetický průměr hodnot
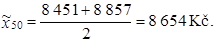
|
Interpretace dosud vypočtených výsledků je obdobná jako v příkladu 1.5. Kvartilové rozpětí vypočteme jako rozdíl horního a dolního kvartilu
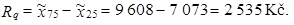
|
Na základě vypočteného kvartilového rozpětí můžeme konstatovat, že polovina, tj. 50 %, domácností má měsíční výdaje za potraviny v intervalu od 7 073 Kč do 9 608 Kč, tj. v rozmezí 2 535 Kč.
Příklad 1.7
V tabulce 1.20 máme k dispozici údaje o měsíčních nákladech na bydlení (v Kč) 33 domácností.
| Tabulka 1.20 | |||||||||
| Číslo domácnosti | Měsíční náklady na bydlení | Číslo domácnosti | Měsíční náklady na bydlení | Číslo domácnosti | Měsíční náklady na bydlení | ||||
| 6 838 9 116 8 386 9 546 9 950 9 030 9 755 7 310 6 536 9 676 9 288 | 6 405 8 257 6 708 8 558 7 776 8 160 8 988 7 870 8 798 8 342 6 966 | 7 956 6 902 6 816 7 320 6 794 7 482 6 139 8 531 9 423 9 925 8 125 | |||||||
Zkonstruujte číslicový dendrogram.
Řešení:
Protože číslicový dendrogram konstruujeme opět z neuspořádaných dat, budeme postupovat opět ve dvou krocích. Nejvyšší řád hodnot měsíčních nákladů na bydlení v tabulce 1.20 jsou tisíce, stonek číslicového dendrogramu budou tedy tvořeny tisíci (jsou zde číslice 6, 7, 8 a 9). Aby graf nebyl příliš široký, každou číslici napíšeme do stonku zase dvakrát, viz příklad 1.5. Druhý nejvyšší řád hodnot měsíčních nákladů na bydlení jsou stovky, listy budeme tedy tvořit stovkami. Číslice na ostatních nižších řádech (v tomto příkladu desítky a jednotky) zanedbáváme, ale nezaokrouhlujeme. K číslicím stonku postupně přiřazujeme číslice listů, přičemž se opět dohodneme, že číslice listů 0 až 4 budeme přiřazovat k příslušné horní číslici stonku a číslice listů 5 až 9 budeme přiřazovat k dolní dané číslici stonku. Zde končí první krok. V druhém kroku pouze číslice listů uspořádáme vzestupně, viz obrázek 1.16.
Obrázek 1.16
| První krok | Druhý krok | |||||
| stonek | Listy | stonek | listy | |||
| (*1000) | (*100) | (*1000) | (*100) | |||
Příklad 1.8
Tabulka 1.21 představuje tabulku intervalového rozdělení četností měsíčního příjmu domácnosti (v Kč) 36 domácností.
| Tabulka 1.21 | |||||||||
| Číslo | Hranice intervalu | Střed | Četnost | Kumulativní četnost | |||||
| intervalu | dolní | horní | intervalu | absolutní | relativní | absolutní | relativní | ||
| 15 001 20 001 25 001 30 001 35 001 40 001 | 20 000 25 000 30 000 35 000 40 000 45 000 | 17 500 22 500 27 500 32 500 37 500 42 500 | 0,139 0,222 0,361 0,139 0,083 0,056 | 0,139 0,361 0,722 0,861 0,944 1,000 | |||||
Odhadněte medián.
Řešení:
Ze sloupce kumulativních absolutních četností je zřejmé, že 36,1 % nejmenších hodnot měsíčního příjmu domácnosti se nachází v prvních dvou intervalech a 72,2 % nejmenších hodnot měsíčního příjmu domácnost je v prvních třech intervalech. Medián je 50% kvantil, z čehož vyplývá, že víme, že se bude s jistotou nacházet v prvních třech intervalech a že se nebude s jistotou nacházet v prvních dvou intervalech. Medián tedy musí být ve třetím intervalu.
Protože se jedná o 50% kvantil, 100 p = 50 a p = 0,5. Horní hranice intervalu, ve kterém leží hledaný kvantil, je horní hranice třetího intervalu, tj. xh = 30 000, dolní hranice intervalu, ve kterém leží hledaný kvantil, je dolní hranice třetího intervalu, tj. xd = 25 001. Kumulativní relativní četnost v procentech odpovídající xh je ih = 72,2 % a kumulativní relativní četnost v procentech odpovídající xd je vlastně kumulativní relativní četnost v procentech odpovídající horní hranici předcházejícího intervalu (dolní hranice daného intervalu vlastně odpovídá horní hranici předcházejícího intervalu), tj. id = 36,1 %. Medián odhadneme dosazením do vztahu (1.10)
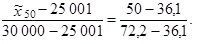
|
Medián měsíčního příjmu domácnosti je přibližně
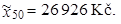
|
Cvičení
1. K dispozici máme následující údaje týkající se hrubého měsíčního příjmu 33 zaměstnanců jedné firmy, viz tabulka 1.22.
| Tabulka 1.22 | |||||||||
| Číslo zaměstnance | Hrubý měsíční příjem | Číslo zaměstnance | Hrubý měsíční příjem | Číslo zaměstnance | Hrubý měsíční příjem | ||||
| 25 405 29 335 28 234 29 333 27 245 30 845 26 894 24 444 25 679 27 385 27 853 | 27 354 31 856 28 353 26 893 23 555 22 843 24 788 25 785 27 784 25 689 24 333 | 28 965 27 466 27 888 29 974 28 758 29 486 29 544 25 784 27 543 28 864 24 796 | |||||||
Určete kvartily a kvartilové rozpětí.
2. Z tabulky intervalového rozdělení četností, viz tabulka 1.23, odhadněte přibližnou hodnotu sedmého decilu.
| Tabulka 1.23 | |||||||||
| Hranice intervalu | Četnost | Kumulativní četnost | |||||||
| Interval | dolní | horní | absolutní | relativní | absolutní | relativní | |||
| 0,048 0,323 0,387 0,242 | 0,048 0,371 0,758 1,000 | ||||||||
3. Z následující tabulky 1.24 určete kvartily a kvartilové rozpětí. Zkonstruujte krabičkový graf.
| Tabulka 1.24 | ||||||
4. Následující hodnoty v tabulce 1.25 představují životnost 50 obrazovek téhož typu (tis.hodin) zaokrouhleno na stovky hodin. Vypočtěte kvartily.
| Tabulka 1.25 | |||||||||
| 13,5 | 13,0 | 12,2 | 13,8 | 13,5 | 13,5 | 14,1 | 14,5 | 13,2 | 13,0 |
| 13,4 | 13,9 | 13,4 | 13,1 | 13,1 | 13,6 | 12,6 | 13,3 | 13,8 | 14,1 |
| 12,6 | 14,7 | 12,5 | 14,3 | 13,4 | 13,7 | 13,9 | 13,6 | 12,9 | 13,3 |
| 13,7 | 11,9 | 13,3 | 11,6 | 13,7 | 15,0 | 14,5 | 14,4 | 13,2 | 13,1 |
| 13,1 | 14,2 | 14,8 | 14,1 | 13,2 | 15,1 | 14,2 | 12,6 | 13,9 | 13,7 |
Výsledky
1.
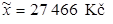
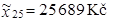
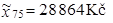
2.
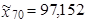
3.
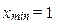
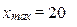
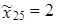
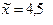
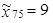
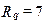

| 4,5 |
4.
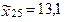
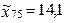
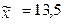
| 1.6 | Charakterizování polohy, variability a koncentrace hodnot číselné proměnné |
Při popisu statistických souborů nás zajímá poloha, někdy říkáme úroveň, rozdělení četností a variabilita rozdělení četností. Méně často sledujeme další dvě vlastnosti, a to šikmost, někdy říkáme asymetrii, a špičatost, neboli exces rozdělení četností.
Charakteristiky polohy
Základní vlastností rozdělení četností je jeho poloha. Měříme ji pomocí různých druhů středních hodnot, které rozdělujeme v zásadě na dvě skupiny. Do první skupiny patří takové střední hodnoty, které se počítají z hodnot sledované proměnné všech statistických jednotek statistického souboru. Takovéto střední hodnoty se nazývají průměry, z nichž nejdůležitější jsou aritmetický průměr, harmonický průměr, geometrický průměr a kvadratický průměr. Do druhé skupiny patří takové střední hodnoty, jejichž hodnoty jsou rovny pouze některým hodnotám proměnné ve statistickém souboru. Nejdůležitější z těchto středních hodnot je medián a modus. Průměry představují kvalitnější charakteristiku polohy, neboť jejich výpočet vychází z hodnot sledované proměnné všech statistických jednotek statistického souboru.
Střední hodnota číselné proměnné x nabývající hodnot xj, j = 1, 2,..., n, ze kterých některá hodnota je minimální hodnota, značíme xmin, a některá hodnota je maximální hodnota, značíme xmax, je každá hodnota xstr, pro kterou platí vztah
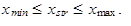
| (1.11) |
Z hodnot xstr vyhovujících vztahu (1.11) můžeme jmenovat extrémní hodnoty xmin a xmax, modus 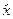 , medián
, medián 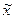 , dolní a horní kvartil, decily, percentily apod. Z těchto středních hodnot jsou velmi vhodnými charakteristikami polohy modus a medián. Všechny tyto druhy středních hodnot jsou konkrétní hodnoty sledované proměnné nebo aritmetický průměr dvou konkrétních hodnot sledované proměnné, a tedy nejsou přímo ovlivněny velikostí všech hodnot sledované proměnné, což se stává výhodou zejména tehdy, když se ve statistickém souboru vyskytují náhodně jedna nebo několik málo mimořádně extrémních hodnot proměnné, kterým říkáme odlehlá pozorování. V takovém případě je výhodou, že např. medián ani modus nejsou těmito odlehlými pozorováními ovlivněny. Někdy se však necitlivost těchto středních hodnot vnímá jako nevýhoda, kterou překonává jiná skupina středních hodnot, které říkáme průměry.
, dolní a horní kvartil, decily, percentily apod. Z těchto středních hodnot jsou velmi vhodnými charakteristikami polohy modus a medián. Všechny tyto druhy středních hodnot jsou konkrétní hodnoty sledované proměnné nebo aritmetický průměr dvou konkrétních hodnot sledované proměnné, a tedy nejsou přímo ovlivněny velikostí všech hodnot sledované proměnné, což se stává výhodou zejména tehdy, když se ve statistickém souboru vyskytují náhodně jedna nebo několik málo mimořádně extrémních hodnot proměnné, kterým říkáme odlehlá pozorování. V takovém případě je výhodou, že např. medián ani modus nejsou těmito odlehlými pozorováními ovlivněny. Někdy se však necitlivost těchto středních hodnot vnímá jako nevýhoda, kterou překonává jiná skupina středních hodnot, které říkáme průměry.
Průměry jsou střední hodnoty, které jsou funkcí všech hodnot sledované proměnné. Teoreticky rozlišujeme nekonečně mnoho druhů průměrů.
Aritmetický průměr
Prostý aritmetický průměr n hodnot x 1, x 2,..., xn, které nemusí být uspořádány, lze vypočítat jako
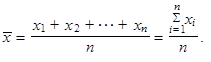
| (1.12) |
Máme-li hodnoty proměnné uspořádány do tabulky rozdělení četností, je lepší použít vážený aritmetický průměr
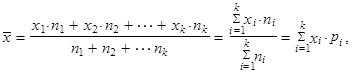
| (1.13) |
kde absolutní četnosti n 1, n 2,..., nk udávají váhu, kterou přisuzujeme jednotlivým obměnám proměnné x 1, x 2,..., xk. Aritmetický průměr má smysl tehdy, má-li nějaký informační smysl součet hodnot proměnné.
Aritmetický průměr má řadu vlastností:
| 1. | Jestliže vynásobíme aritmetický průměr 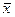 rozsahem statistického souboru n, získáme vždy součet všech hodnot proměnné rozsahem statistického souboru n, získáme vždy součet všech hodnot proměnné
| ||
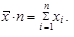
| (1.14) | ||
| 2. | Součet všech odchylek hodnot proměnné od jejich aritmetického průměru je vždy roven nule | ||
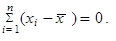
| (1.15) | ||
| 3. | Součet čtverců všech odchylek hodnot proměnné od jejich aritmetického průměru je minimální | ||
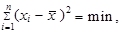
| (1.16) | ||
to znamená, že je menší než součet čtverců všech odchylek hodnot proměnné od jakékoliv konstanty 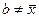 . .
| |||
| 4. | Aritmetický průměr konstanty je roven této konstantě | ||
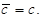
| (1.17) | ||
| 5. | Přičteme-li ke všem hodnotám, resp. odečteme-li od všech hodnot, proměnné libovolnou kladnou konstantu (a > 0), aritmetický průměr se zvětší, resp. zmenší, o tuto konstantu | ||
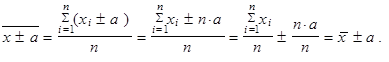
| (1.18) | ||
| 6. | Násobíme-li, resp. dělíme-li, všechny hodnoty proměnné libovolnou nenulovou konstantou (k ≠ 0), aritmetický průměr se rovněž znásobí, resp. vydělí, touto konstantou | ||
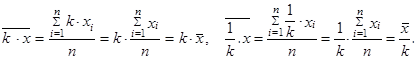
| (1.19) | ||
| 7. | Násobíme-li váhy váženého aritmetického průměru libovolnou nenulovou konstantou (b ≠ 0), aritmetický průměr se nezmění | ||
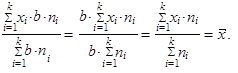
| (1.20) | ||
| 8. | Je-li statistický soubor rozdělen do k dílčích podsouborů s dílčími aritmetickými průměry v jednotlivých dílčích podsouborech | ||
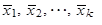
| |||
| a s počty pozorování v jednotlivých dílčích podsouborech n 1, n 2,..., nk, aritmetický průměr celkového statistického souboru vypočteme jako vážený aritmetický průměr dílčích aritmetických průměrů | |||
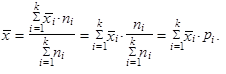
| (1.21) | ||
Počítáme-li aritmetický průměr z intervalového rozdělení četností s k intervaly a známe-li aritmetické průměry v jednotlivých intervalech

