




Указания к выполнению и оформлению лабораторных работ
Работы выполняются на листах формата А-4. На титульном листе записывается название работы, фамилия и имя исполнителя, группа, отделение, текущий год и семестр.
Чертежи, схемы, рисунки, таблицы выполняются с помощью чертежных инструментов. Все они должны сопровождаться названиями и необходимыми надписями. Текущий текст пишется ручкой. Важные места работы можно выделять цветом. Работы можно оформлять на компьютере.
При выполнении работы во всех случаях записываются применяемые формулы, промежуточные вычисления, даются необходимые письменные пояснения. Особо выделяются получаемые результаты при обработке данных.
В конце каждой работы приводится письменный анализ полученных результатов, выдвигаются гипотезы, делаются выводы и обобщения, стоятся прогнозы.
Отбор числового материала для выполнения работ
Работы 1-2.
Ч исловые данные выбираются из таблицы "Статистические данные". Она находится в приложении к данному комплекту работ. Вариант сообщает преподаватель.
Работа 3.
Исходные числовые данные совпадают с числовыми данными, использованными при выполнении работы 1.
Работа 4.
Требуется две группы числовых данных: показатель Х и показатель У. Показатель Х совпадает с числовыми данными, использованными при выполнении первой работы. Показатель У берется из следующей строки таблицы "Статистические данные", по отношении к строке, использованной в первой работе.
Работа 5
Требуется две группы числовых данных: тест и ретест. Тест совпадает с числовыми данными, использованными при выполнении первой работы. Значения ретеста берутся из второй строки таблицы "Статистические данные", по отношении к строке, использованной в первой работе.
Работа 6
Требуется 5 групп данных (5 тестов). Работа выполняется для 7 спортсменов. Имена их выбираются самостоятельно, фамилии при этом не упоминаются
-Для получения значений теста "масса тела", надо взять числовые данные строки таблицы "Статистические данные", использованной в работе 1 и увеличить каждое из них их на одно и тоже число, взятое из промежутка 50 – 100. Полученные числа округлить до целых значений. Обратить внимание на то, что значения массы были правдоподобными.
-Для получения значений теста "рост", надо взять числовые данные строки таблицы "Статистические данные", использованной в работе 1 и увеличить каждое из них их на одно и тоже число, взятое из промежутка 100 - 150 Полученные числа округлить до целых значений. Обратите внимание на то, что бы значения роста были правдоподобными.
Откорректируйте полученную Массу и Рост до правдоподобных их значений.
-Остальные пять тестов и их числовые значения выбираются самостоятельно.
Работа 7,
Требуется один тест и два критерия. Значения теста берется из строки 33 таблицы "Статистические данные". Для первого критерия берутся числовые данные из строки, которая использовалась при выполнении первой работы. Для второго критерия берется следующая строка таблицы "Статистические данные", по отношении к строке, использованной в первой работе.
***
Тема 1. Обработка статистического материала методом средних величин
Теоретические сведения
Обработка статистических данных методом средних величин является наиболее популярным среди работников физической культуры и спорта. Он заключается в получении ряда средних показателей, которые позволяют анализировать статистические данные.
а). Первичная обработка поступающих данных
Устанавливается объем выборки, а именно определяется число обрабатываемых данных. Надо иметь в виду, что, чем больше объем выборки, тем точнее получаемые показатели и тем сложнее вести вычисления. В процессе соревнований или иных действий (используются протоколы соревнований) данные поступают в произвольном порядке. Для удобства рекомендуется ведение записей данных в виде таблицы по пять или десять чисел в каждой строчке, что облегчает установления их числа.
б). Построение вариационного ряда (вариационной таблицы) и определение их параметров и численных характеристик для рассматриваемой совокупности.
Каждый вариационный ряд представляет собой математическую систему, т.е. группу чисел, связанных между собой. Такую систему характеризуется следующими показателями:
~ среднее арифметическое, обозначается:  , Xсред,
, Xсред, 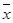 , Хср, хср
, Хср, хср
~ дисперсия, обозначается: d или s 2
~ среднее квадратичное отклонение, обозначается: s
~ коэффициент вариации, обозначается: u
2. Последовательность обработки данных:
1. Ранжирование данных.
Данные, взятые из таблицы (см. приложение) запишите в удобном для Вас порядке
а). Строится таблица ранжирования по образцу таблицы 1-1.
| Таблица 1-1. Ранжирование данных | ||
| Значение данных | Распределение данных | Число данных |
| … | … | … |
| Сумма данных |
В первом столбике записывается числовые значения показателей в порядке возрастания. Рекомендуется записать последовательно все значения от минимального показателя до максимального показателя. Соседние значения могут отличаться на значение точности измерений.
Во втором столбике делается отметка о наличии таковых показателей в выборке. Для этого ставится палочка (звездочка, точка или иной знак) против соответствующего показателя при последовательном просмотре выборки. Некоторые строчки в данном столбике могут оказаться пустыми.
В третьем столбике записывается число встречаемых одинаковых показателей.
| Таблица 1-2. Вариационный ряд прыжков с места | |
| xi | ni |
| … | … |
| Сумма |
б). На основе таблицы 1-1 строится обобщенная таблица 1-2, состоящая из двух столбиком.
Первый (левый) столбик состоит из собственных показателей – вариант. Он обозначается чрез xi и содержит значения очередного показателя.
Второй (правый) столбик содержит число показателей (вариант), называемых частотой Он показывает число соответствующих одинаковых показателей и обозначается через ni
Сумма частот определяет объемом совокупности.
| Таблица 1-3. Вычисление среднего арифметического | |||
| № | xi | ni | xini |
| … | … | … | … |
| Сумма |
Замечание. Собственный показатель и частота обозначаются латинскими буквами, индекс показывает на номер множества, которому принадлежит соответствующий показатель. Объем совокупности обозначается буквой без индекса. Например, n=40. При одновременном рассмотрении нескольких вариационных рядов, рекомендуется использовать различные буквы.
2. Вычисление среднего арифметического.
Эта характеристика является показателем, который вычисляется наиболее просто и поэтому часто используется исследователями.
 , n – объем совокупности; x1, x2 …xn – показатели, взятые из первоначальной таблицы 1-1.
, n – объем совокупности; x1, x2 …xn – показатели, взятые из первоначальной таблицы 1-1.
Для вычисления среднего арифметического удобно составить таблицу 1-3 и тогда формула вычисления среднего арифметического имеет вид:
Xсред= 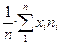 , где xi – частота; n – объем совокупности
, где xi – частота; n – объем совокупности
В дальнейшем будут рассмотрены и другие характеристики вариационного ряда.
Замечания:
1. Таблица 3 является частью таблицы 4, поэтому их можно объединить.
2. Точность полученных при вычислениях результатов вычислений и точность измерений должны совпадать. (Иметь одинаковое число десятичных знаков после запятой). Промежуточные результаты должны иметь более высокую точность: одну - две запасные цифры. Окончательный результат округляется до необходимой точности. Если округление с необходимой точность приводит к нулевому результату, то округление проводится до первой значащей цифры, отличной от нуля, считая слева.
3. Вычисление дисперсии.
Дисперсия указывает на варьирование (рассеивание) исходных данных относительно среднего арифметического. Дисперсия обозначается буквами d или σ2 ивычисляется по формуле:
d = 
Для вычисления дисперсии можно рекомендовать следующий алгоритм действий:
1. Вычерчивается макет таблицы 1-4, в который вносятся данные полученные ранее. Это, например, с первого по четвертый столбики. Остальные - заполняется по мере проведения вычислений. Обращаем внимание на то, что в этой таблице первые четыре столбика повторяют предыдущую таблицу 1-3. Поэтому, если исследователь заранее планирует вычисление дисперсии, то таблицу1-3 можно отдельно не приводить
| Таблица 1-4. Определение дисперсии | ||||||
| № | xi | ni | xini | (хi - xсред) | (хi - xсред)2 | (хi - xсред)2 ·ni |
| … | … | … | … | … | … | … |
| Сумма | - | - | - | S= |
2. Определяется Xсред
3. Заполняется пятый столбик таблицы 1-4, для этого из каждого показателя второго столбика вычитаются средний показатель: хi - xсред
4. Найденные разности, это показатели пятого столби, возводятся в квадрат: (хi - xсред)2 и вносятся в шестой столбик таблицы 1-4
5. Полученные квадраты (столбик 6) умножаются на соответствующие частоты (столбик 3), результаты вносятся в последний столбик таблицы 1-4: именно, (хi - xсред)2 ·ni.
6. Находится сумма S полученных произведений – суммируется последний столбик этой таблицы.
7. Полученная сумма S делится на объем совокупности n=25. Полученный результат и есть дисперсия. Округляется до точности исходных (обрабатываемых) показателей.
4. Вычисление среднего квадратичного отклонения
Средне квадратичное значение вычисляется по формуле s = 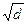 =
= 
5.Вычисление коэффициента вариации.
Коэффициент вариации вычисляется по формуле: 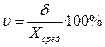 , если коэффициент представляется в виде процентов. Если надо представить его в виде десятичной дроби, то в формуле отсутствует множитель 100%
, если коэффициент представляется в виде процентов. Если надо представить его в виде десятичной дроби, то в формуле отсутствует множитель 100%
6. Анализ полученных показателей
Основными параметрами вариационного ряда являются среднее арифметическое, среднее квадратичное, коэффициент дисперсии.
Составляется неравенство
A < Xсред < B, где А = Xсред - s, В = Xсред + s
или Xсред - s < Xсред < В = Xсред + s
Из этих характеристик усматриваются типичные показатели, которые входят в промежуток (A; В) и нетипичные, которыми не входят в указанный промежуток. Можно рекомендовать к рассмотрению промежуток [A; B], т.е. включаются границы промежутка.
Все остальные показатели не являются типичными.
Показатели, которые меньше числа А, считаются не достающиеся показатели. Показатели, которые больше числа В считаются - превосходящие показатели.
Далее сравнивается число показателей, попавших в интервал и число показателей не попавших в него. При значительном расхождении можно говорить о стабильной группе. При незначительном расхождении или равенстве, можно говорить о не стабильных результатах
Анализ полученных результатов провидится с указанием их практической значимости для учебного, тренировочного, научного процесса.
Последний этап очень важен тем, что при неумении усмотреть полученные результаты сводится к минимуму значимость всей работы, связанной с обработкой соответствующей совокупности.
***
Тема 2. Обработка статистических данных интервальным методом,
эмпирическое распределение
Теоретические сведения
Интервальный метод связан с разбиением размаха выборки (разность между максимальным и минимальным значениями) на определенное число интервалов. Значения, попавшие в один и тот же интервал, фиксируются при этом как одинаковые значения. Данный метод сокращает вычисления и позволяет установить дополнительные характеристики выборки. А именно, получить, так называемое "Эмпирическое распределение" или "Вариационный ряд". Этот метод применяется в основном при обработке большого числа статистических данных
Полученные числовые данные (числовые значения исследуемого признака), как правило, поступают к исследователю в произвольном порядке. При этом, очень трудно анализировать ситуацию, строить прогнозы, делать обобщения. Такие числовые данные требуют математической обработки. В данной работе будут рассмотрено представление данных в форме вариационных таблиц, гистограмм (диаграмм), графиков (полигонов), используя разбиение данных на определенное число интервалов.

