




Для оценки параметров уравнения множественной регрессии  , так же как и для оценки этих параметров в простейшем случае парной однофакторной регрессии, используется метод наименьших квадратов (МНК) . Соответствующая система нормальных уравнений имеет структуру, аналогичную той, которая была в модели однофакторной регрессии, но теперь является более громоздкой и для ее решения можно применять известный из линейной алгебры метод определителей Крамера
, так же как и для оценки этих параметров в простейшем случае парной однофакторной регрессии, используется метод наименьших квадратов (МНК) . Соответствующая система нормальных уравнений имеет структуру, аналогичную той, которая была в модели однофакторной регрессии, но теперь является более громоздкой и для ее решения можно применять известный из линейной алгебры метод определителей Крамера 

 .
.
Если парная регрессия (однофакторная) может дать хороший результат в случае, когда влиянием других факторов можно пренебречь, то исследователь не может быть уверен в справедливости пренебрежения влиянием прочих факторов в общем случае. Более того, в экономике, в отличие от химии, физики и биологии, затруднительно использовать для преодоления этой трудности методы планирования эксперимента ввиду отсутствия в экономике возможности регулирования отдельных факторов! Поэтому большое значение приобретает попытка выявления влияния прочих факторов с помощью построения уравнения множественной регрессии и изучения такого уравнения.
Анализ модели множественной регрессии требует разрешения двух весьма важных новых вопросов. Первым является вопрос разграничения эффектов различных независимых переменных. Данная проблема, когда она становится особенно существенна, носит название проблемы мультиколлинеарности . Вторая, не менее важная проблема заключается в оценке совместной (объединенной) объясняющей способности независимых переменных в противоположность влиянию их индивидуальных предельных эффектов.
С этими двумя вопросами связана проблема спецификации модели . Дело в том, что среди нескольких объясняющих переменных имеются оказывающие влияние на зависимую переменную и не оказывающие такового влияния. Более того, некоторые переменные могут и вовсе не подходить для данной модели. Поэтому необходимо решить, какие переменные следует включать в модель (уравнение), а какие, напротив, исключить. Так, если в уравнение не вошла переменная, которая по природе исследуемых явлений и процессов в действительности должна была быть включена в эту модель, то оценки коэффициентов регрессии с довольно большой вероятностью могут оказаться смещенными. При этом рассчитанные по простым формулам стандартные ошибки коэффициентов и соответствующие тесты в целом становятся некорректными.
Если же включена переменная, которая не должна присутствовать в уравнении, то оценки коэффициентов регрессии будут несмещенными, но с высокой вероятностью окажутся неэффективными. Также в этом случае рассчитанные стандартные ошибки окажутся в целом приемлемы, но из-за неэффективности регрессионных оценок они станут чрезмерно большими.
Особого внимания заслуживают так называемые замещающие переменные . Часто оказывается, что данные по какой-либо переменной не могут быть найдены или что определение таких переменных столь расплывчато, что непонятно, как их в принципе измерить. Другие переменные поддаются измерению, но таковое весьма трудоемко и требует много времени, что практически весьма неудобно. В подобных случаях приходится использовать некоторую другую переменную вместо вызывающей описанные выше затруднения. Такая переменная называется замещающей, но каким условиям она должна удовлетворять? Замещающая переменная должна выражаться в виде линейной функции (зависимости) от неизвестной (замещаемой) переменной, и наоборот, последняя также связана линейной зависимостью с замещающей переменной. Важно, что сами коэффициенты линейной зависимости неизвестны. Иначе всегда можно выразить одну переменную через другую и вовсе не использовать замещающей переменной. Оставаясь неизвестными, коэффициенты являются обязательно постоянными величинами . Бывает и так, что замещающая переменная используется непреднамеренно (неосознанно).
Включаемые в уравнение множественной регрессии факторы должны объяснить вариацию зависимой переменной . Если строится модель с некоторым набором факторов, то для нее рассчитывается показатель детерминации , который фиксирует долю объясненной вариации результативного признака (объясняемой переменной ) за счет рассматриваемых в регрессии факторов. А как оценить влияние других, неучтенных в модели факторов? Их влияние оценивается вычитанием из единицы коэффициента детерминации , что и приводит к соответствующей остаточной дисперсии .
Таким образом, при дополнительном включении в регрессию еще одного фактора коэффициент детерминации должен возрастать, а остаточная дисперсия уменьшаться. Если этого не происходит и данные показатели практически недостаточно значимо отличаются друг от друга, то включаемый в анализ дополнительный фактор не улучшает модель и практически является лишним фактором.
Если модель насыщается такими лишними факторами, то не только не снижается величина остаточной дисперсии и не увеличивается показатель детерминации, но, более того, снижается статистическая значимость параметров регрессии по критерию Стьюдента вплоть до статистической незначимости!
Вернемся теперь к уравнению множественной регрессии с точки зрения различных форм, представляющих такое уравнение. Если ввести стандартизованные переменные , представляющие собой исходные переменные, из которых вычитаются соответствующие средние, а полученная разность делится на стандартное отклонение, то получим уравнения регрессии в стандартизованном масштабе . К этому уравнению применим МНК . Для него из соответствующей системы уравнений определяются стандартизованные коэффициенты регрессии β (бета-коэффициенты). В свою очередь, коэффициенты множественной регрессии просто связаны со стандартизованными β-коэффициентами, именно коэффициенты регрессии получаются из β-коэффициентов умножением последних на дробь, представляющую собой отношение стандартного отклонения результативного фактора к стандартному отклонению соответствующей объясняющей переменной.
В простейшем случае парной регрессии стандартизованный коэффициент регрессии — это не что иное, как линейный коэффициент корреляции. Вообще стандартизованные коэффициенты регрессии показывают, на сколько стандартных отклонений изменится в среднем результат, если соответствующий фактор изменится на одно стандартное отклонение при неизменном среднем уровне других факторов. Кроме того, поскольку все переменные заданы как центрированные и нормированные, все стандартизованные коэффициенты регрессии сравнимы между собой, поэтому можно ранжировать факторы по силе их воздействия на результат. Следовательно, можно использовать стандартизованные коэффициенты регрессии для отсева факторов с наименьшим влиянием на результат просто по величинам соответствующих стандартизованных коэффициентов регрессии.
Теснота совместного влияния факторов на результат оценивается с помощью индекса множественной корреляции , который дается простой формулой: из единицы вычитается отношение остаточной дисперсии к дисперсии результативного фактора, а из полученной разности извлекается квадратный корень:
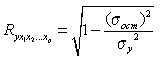 . (5.5)
. (5.5)
Его величина лежит в пределах от 0 до 1 и при этом больше или равна максимальному парному индексу корреляции. Для уравнения в стандартизованном виде (масштабе) индекс множественной корреляции записывается еще проще, т.к. подкоренное выражение в данном случае является просто суммой попарных произведений β-коэффициентов на соответствующие парные индексы корреляции:
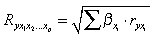 . (5.6)
. (5.6)
Таким образом, в целом качество построенной модели оценивают с помощью коэффициента или индекса детерминации, как показано выше. Этот коэффициент множественной детерминации рассчитывается как индекс множественной корреляции, а иногда используют скорректированный соответствующий индекс множественной детерминации, который содержит поправку на число степеней свободы. Значимость уравнения множественной регрессии в целом оценивается с помощью F-критерия Фишера . Имеется также частный F-критерий Фишера, оценивающий статистическую значимость присутствия каждого из факторов в уравнении.
Оценка значимости коэффициентов чистой регрессии с помощью t-критерия Стьюдента сводится к вычислению корня квадратного из величины соответствующего частного критерия Фишера или, что то же самое, нахождению величины отношения коэффициента регрессии к среднеквадратической ошибке коэффициента регрессии .
При тесной линейной связанности факторов, входящих в уравнение множественной регрессии , возможна проблема мультиколлинеарности факторов. Количественным показателем явной коллинеарности двух переменных является соответствующий линейный коэффициент парной корреляции между этими двумя факторами. Две переменные явно коллинеарны, если этот коэффициент корреляции больше или равен 0,7. Но это указание на явную коллинеарность факторов абсолютно недостаточно для исследования общей проблемы мультиколлинеарности факторов, т.к. чем сильнее мультиколлинеарность (без обязательного наличия явной коллинеарности ) факторов, тем менее надежна оценка распределения суммы объясненной вариации по отдельным факторам с помощью МНК .
3.3.
Нелинейная регрессия
Линейная регрессия и методы ее исследования и оценки не имели бы столь важного значения, если бы помимо этого весьма важного, но все же простейшего случая мы не получали бы с их помощью инструмента анализа более сложных нелинейных зависимостей. Нелинейные регрессии могут быть разделены на два существенно различных класса. Первым и более простым является класс нелинейных зависимостей, в которых имеется нелинейность относительно объясняющих переменных, но которые остаются линейными по входящим в них и подлежащим оценке параметрам. Сюда входят полиномы различных степеней и равносторонняя гипербола .
Такая нелинейная регрессия по включенным в объяснение переменным простым их преобразованием (заменой) легко сводится к обычной линейной регрессии для новых переменных. Поэтому оценка параметров в этом случае выполняется просто по МНК, поскольку зависимости линейны по параметрам. Так, важную роль в экономике играет нелинейная зависимость, описываемая равносторонней гиперболой:
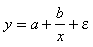 . (5.25)
. (5.25)
Ее параметры хорошо оцениваются по МНК и сама такая зависимость характеризует связь удельных расходов сырья, топлива, материалов с объемом выпускаемой продукции, временем обращением товаров и всех этих факторов с величиной товарооборота. Например, кривая Филлипса характеризует нелинейное соотношение между нормой безработицы и процентом прироста заработной платы.
Совершенно по-другому обстоит дело с регрессией, нелинейной по оцениваемым параметрам , например, представляемой степенной функцией, в которой сама степень (ее показатель) является параметром или зависит от него. Также это может быть показательная функция, где основанием степени является параметр и экспоненциальная функция, в которой опять же показатель содержит параметр или комбинацию параметров. Этот класс, в свою очередь, делится на два подкласса: к одному относятся внешне нелинейные , но по существу внутренне линейные. В этом случае можно привести модель к линейному виду с помощью преобразований. Однако, если модель внутренне нелинейна, то она не может быть сведена к линейной функции.
Таким образом, только модели внутренне нелинейные в регрессионном анализе считаются действительно нелинейными. Все прочие, сводящиеся к линейным посредством преобразований, таковыми не считаются, и именно они рассматриваются чаще всего в эконометрических исследованиях. В то же время это не означает невозможности исследования в эконометрике существенно нелинейных зависимостей. Если модель внутренне нелинейна по параметрам, то для оценки параметров используются численные итеративные процедуры, успешность которых зависит от вида уравнения и от особенностей применяемого итеративного метода.
Вернемся к зависимостям, приводимым к линейным. Если они нелинейны и по параметрам и по переменным, например, вида у = а, умноженному на степень х, показатель которой и есть параметр β (бета):
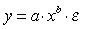 . (5.26)
. (5.26)
Очевидно, такое соотношение легко преобразуется в линейное уравнение простым логарифмированием:
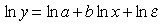 .
.
После введения новых переменных, обозначающих логарифмы, получается линейное уравнение. Тогда процедура оценивания регрессии состоит в вычислении новых переменных для каждого наблюдения путем взятия логарифмов от исходных значений. Затем оценивается регрессионная зависимость новых переменных . Для перехода к исходным переменным следует взять антилогарифм, т.е. фактически вернуться к самим степеням вместо их показателей (ведь логарифм это и есть показатель степени). Аналогично может рассматриваться случай показательных, или экспоненциальных, функций .
Для существенно нелинейной регрессии невозможно применение обычной процедуры оценивания регрессии, поскольку соответствующая зависимость не может быть преобразована в линейную. Общая схема действий при этом следующая.
· Принимаются некоторые правдоподобные исходные значения параметров.
· Вычисляются предсказанные значения у по фактическим значениям х с использованием этих значений параметров.
· Вычисляются остатки для всех наблюдений в выборке и затем сумма квадратов остатков.
· Вносятся небольшие изменения в одну или более оценку параметров.
· Вычисляются новые предсказанные значения у, остатки и сумма квадратов остатков.
· Если сумма квадратов остатков меньше, чем прежде, то новые оценки параметров лучше прежних и их следует использовать в качестве новой отправной точки.
· Шаги 4, 5 и 6 повторяются вновь до тех пор, пока не окажется невозможным внести такие изменения в оценки параметров, которые привели бы к изменению суммы остатков квадратов.
· Делается вывод о том, что величина суммы квадратов остатков минимизирована и конечные оценки параметров являются оценками по методу наименьших квадратов.
Среди нелинейных функций, которые могут быть приведены к линейному виду, в эконометрике широко используется степенная функция . Параметр b в ней имеет четкое истолкование, являясь коэффициентом эластичности . В моделях, нелинейных по оцениваемым параметрам, но приводимых к линейному виду, МНК применяется к преобразованным уравнениям. Практическое применение логарифмирования и, соответственно, экспоненты возможно тогда, когда результативный признак не имеет отрицательных значений. При исследовании взаимосвязей среди функций, использующих логарифм результативного признака, в эконометрике преобладают степенные зависимости (кривые спроса и предложения, производственные функции, кривые освоения для характеристики связи между трудоемкостью продукции, масштабами производства, зависимость ВНД от уровня занятости, кривые Энгеля ).
Иногда используется так называемая обратная модель, являющаяся внутренне нелинейной, но в ней, в отличие от равносторонней гиперболы, преобразованию подвергается не объясняющая переменная, а результативный признак у. Поэтому обратная модель оказывается внутренне нелинейной и требование МНК выполняется не для фактических значений результативного признака у, а для их обратных значений.
Особого внимания заслуживает исследование корреляции для нелинейной регрессии. В общем случае парабола второй степени, так же как и полиномы более высокого порядка, при линеаризации принимает вид уравнения множественной регрессии. Если же нелинейное относительно объясняемой переменной уравнение регрессии при линеаризации принимает форму линейного уравнения парной регрессии, то для оценки тесноты связи может быть использован линейный коэффициент корреляции .
Если преобразования уравнения регрессии в линейную форму связаны с зависимой переменной (результативным признаком), то линейный коэффициент корреляции по преобразованным значениям признаков дает лишь приближенную оценку связи и численно не совпадает с индексом корреляции . Следует иметь в виду, что при расчете индекса корреляции используются суммы квадратов отклонений результативного признака у, а не их логарифмов. Оценка значимости индекса корреляции выполняется так же, как оценка надежности (значимости) коэффициента корреляции. Сам индекс корреляции, как и индекс детерминации, используется для проверки значимости в целом уравнения нелинейной регрессии по F-критерию Фишера .
Отметим, что возможность построения нелинейных моделей как посредством приведения их к линейному виду, так и путем использования нелинейной регрессии, с одной стороны, повышает универсальность регрессионного анализа, а с другой — существенно усложняет задачи исследователя. Если ограничиваться парным регрессионным анализом, то можно построить график наблюдений у и х как диаграмму разброса. Часто несколько различных нелинейных функций приблизительно соответствуют наблюдениям, если они лежат на некоторой кривой. Но в случае множественного регрессионного анализа такой график построить невозможно.
При рассмотрении альтернативных моделей с одним и тем же определением зависимой переменной выбор прост. Разумнее всего оценивать регрессию на основе всех вероятных функций, останавливаясь на функции, в наибольшей степени объясняющей изменения зависимой переменной. Если коэффициент детерминации измеряет в одном случае объясненную регрессией долю дисперсии, а в другом — объясненную регрессией долю дисперсии логарифма этой зависимой переменной, то выбор делается без затруднений. Другое дело, когда эти значения для двух моделей весьма близки и проблема выбора существенно осложняется.
Тогда следует применять стандартную процедуру в виде теста Бокса — Кокса . Если нужно всего лишь сравнить модели с использованием результативного фактора и его логарифма в виде варианта зависимой переменой, то применяют вариант теста Зарембки . В нем предлагается преобразование масштаба наблюдений у, при котором обеспечивается возможность непосредственного сравнения среднеквадратичной ошибки (СКО) в линейной и логарифмической моделях. Соответствующая процедура включает следующие шаги.
· Вычисляется среднее геометрическое значений у в выборке, совпадающее с экспонентой среднего арифметического значений логарифма от у.
· Пересчитываются наблюдения у таким образом, что они делятся на полученное на первом шаге значение.
· Оценивается регрессия для линейной модели с использованием пересчитанных значений у вместо исходных значений у и для логарифмической модели с использованием логарифма от пересчитанных значений у. Теперь значения СКО для двух регрессий сравнимы, и поэтому модель с меньшей суммой квадратов отклонений обеспечивает лучшее соответствие с истинной зависимостью наблюденных значений.
· Для проверки того, что одна из моделей не обеспечивает значимо лучшее соответствие, можно использовать произведение 1/2 числа наблюдений на логарифм отношения значений СКО в пересчитанных регрессиях с последующим взятием абсолютного значения этой величины. Такая статистика имеет распределение χ2 с одной степенью свободы (обобщение нормального распределения).
top.document.title=document.title; chid="part-008"; chnum=8; chkurl(); // doStart(sa); doStart(sa);

