




Для запису символів аі кодуючого алфавіту А використовують різні позначення у вигляді цифр, букв та спеціальних знаків.
Кодове слово довжини l, у якому використовуються тільки цифри системи числення з основою Q, можна розглядати як l – розрядне число
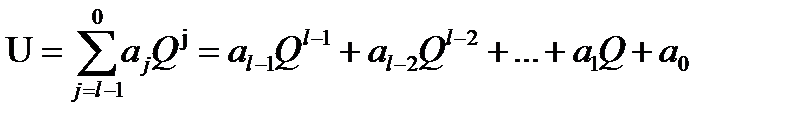
 (1.1)
(1.1)
Правила кодування (взаємнооднозначного відображення  ) можуть бути задані у вигляді таблиць, певних співвідношень (формул) чи словесних правил (алгоритмів).
) можуть бути задані у вигляді таблиць, певних співвідношень (формул) чи словесних правил (алгоритмів).
Спосіб кодування залежить від мети, заради якої він здійснюється: зручність опрацювання чи передавання інформації певними каналами зв’язку, її зберігання (шифрування), скорочення записів тощо. Простим прикладом є кодування за допомогою вуличного світлофора:
| Повідомлення | Кодові слова (кольори світлофора) |
| Переходь вулицю | Зелений |
| Увага! | Жовтий |
| Стій! | Червоний |
Якщо кодові слова мають одинакову довжину l, то такий код називають рівномірним. Наприклад, назви сторін світу можна закодувати таким рівномірним кодом:
Схід – 00
Захід – 01
Південь – 10
Північ – 11
Тут усі кодові слова мають довжину l=2.
Практичний рівномірний код (для телеграфії) вперше створив французький винахідник Жан Бодо (1845-1903). Його рівномірний 5-значний двійковий код (код Бодо) був уперше практично застосований у 1877 році на телеграфній лінії Париж—Бордо.
Кожне кодове слово в рівномірному коді має одну й ту ж довжину l. Тому закодовані в цьому коді повідомлення легко декодувати (розшифрувати). Для цього досить розбити даний код на групи по l символів і кожне, виділене таким чином кодове слово, замінити відповідним елементом повідомлення, виходячи зі співвідношення 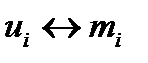 .
.
Дуже важливою є теорема про рівномірні коди.
Теорема 1.1. Над кодуючим алфавітом потужності n можна утворити рівно nl кодових слів довжини l.
Доведемо цю теорему методом повної математичної індукції.
1. Нехай  – елементи (букви) кодуючого алфавіту А потужності n
– елементи (букви) кодуючого алфавіту А потужності n

Із цього алфавіту можна утворити рівно n слів довжини: 

Отже, для k=1 дане твердження є правильним: n=n1.
2. Припустимо, що дане твердження є правильним для l=k-1, і покажемо, що тоді воно справджується і для l=k.
За припущенням, число слів довжини k-1 дорівнює  . Щоб утворити всі можливі слова довжини k, слід до кожного слова довжини k-1 долучити в його кінці послідовно кожну із букв а1, а2,....аn алфавіту А. Таким чином, з кожного слова довжини k утвориться n різних слів довжини k і ми одержимо всі можливі слова довжини k. Оскільки слів довжини k-1 є nk-1, то всіх слів довжини k буде nk-1. n=nk. Припустивши істинність твердження для l=k-1, ми довели, що воно є правильним для l=k.
. Щоб утворити всі можливі слова довжини k, слід до кожного слова довжини k-1 долучити в його кінці послідовно кожну із букв а1, а2,....аn алфавіту А. Таким чином, з кожного слова довжини k утвориться n різних слів довжини k і ми одержимо всі можливі слова довжини k. Оскільки слів довжини k-1 є nk-1, то всіх слів довжини k буде nk-1. n=nk. Припустивши істинність твердження для l=k-1, ми довели, що воно є правильним для l=k.
Отже, відповідно до пунктів 1 і 2, наше твердження, за аксіомою повної математичної індукції, є справедливим для будь-якого натурального числа l.
Теорема 1 дає, зокрема, можливість розв’язати таку важливу проблему в теорії кодування: якої найменшої (мінімальної) довжини l повинні бути кодові слова, побудовані над алфавітом А (а1, а2,...,аn) потужності n, щоб ними можна було закодувати всі k елементів повідомлень із множини M (m1, m2,..., mk).
Згідно із теоремою 1.1 усіх різних кодових слів довжини l можна утворити nl. Їх повинно бути стільки, щоб ними можна було закодувати всі k повідомлень із множини M. Отже, звідси випливає нерівність k≤nl, де невідомим є l.
Приклад. Якої мінімальної довжини треба взяти кодуючі слова рівномірного коду з алфавіту A={0,1}, щоб закодувати ними всі символи римської нумерії Арн={ I, V, X, L, С, D, М}. В нашому випадку К=7, n=2. З нерівності 7≤2l, одержуємо l=3.
Можемо тепер побудувати такий код:
I↔001
V↔010
X↔011
L↔100
C↔101
D↔110
M↔111
Наприклад, римське число MCMLVI (1956) буде закодоване так:
Якщо дано код повідомлення 111111011001001, то його легко розшифрувати (декодувати). Для цього даний код слід розбити на кодові слова по три букви в кожному, і кожне кодове слово замінити елементом повідомлення, відповідно до кодової таблиці. Отримаємо:
MMXIIрн (2012(10)).
Нерівномірні коди
Код, у якому кодові слова мають різну довжину, називають нерівномірним кодом.
Перший практичний нерівномірний код створив американський художник та винахідник Семюель Морзе (1794-1872). У 1837 році він винайшов електромагнітний телеграф, а в 1838 році розробив телеграфний код – азбуку Морзе. Алфавіт цього коду складається із трьох символів: крапки, тире і пропуску.
Для прикладу наведемо фрагмент цього коду (таб.1).
Таблиця 1
| Букви українського алфавіту | Кодові слова азбуки Морзе |
| А | ∙ − |
| Б | − ∙ ∙ ∙ |
| Н | ─ ∙ |
| Я | ∙ ─ ∙ ─ |
Наприклад, слово БАНЯ кодом Морзе запишуть так:
─ ∙ ∙ ∙ │ ∙ ─ │ ─ ∙ │ ∙ ─ ∙ ─
Основні напрями кодування
Відповідно до мети кодування є декілька напрямів кодування, серед яких можна виділити два основні.
Перший напрям кодування пов’язаний із захистом інформації.
Проблеми захисту інформації люди почали розв’язувати ще з сивої глибини віків. Під захистом інформації розуміють:
а) обмеження доступу до інформації особам, що не мають відповідного дозволу (несанкційований, нелегальний доступ);
б) обмеження незумисного або недозволеного використання, зміни чи руйнування інформації.
Захист інформації є необхідним для зменшення ймовірності її розголошення, зумисного спотворення (модифікації) або втрати, знищення інформації, яка має певну цінність для її власника. Руйнування чи зміни інформації можуть мати місце в результаті збоїв або нестабільності роботи технічних пристроїв, які використовують для зберігання інформації (техногенний фактор), а також у результаті несвідомої діяльності людини (людський фактор).
Проблеми захисту інформації шляхом такого її перетворення, що унеможливлює її розуміння сторонніми особами, людство почало розв’язувати ще на світанку людської цивілізації, в період створення мовних засобів. З розвитком людського суспільства, появою приватної власності, державного устрою, боротьби за владу, інформація почала набувати значної ціни. Цінною стає та інформація, яка дає можливість її дійсним та потенційним власникам одержати певні дивіденди — матеріальні, політичні, військові тощо.
Проблеми захисту інформації від самовільного (несанкціонованого) доступу особливо загострилася в наш час. Поява комп’ютерів та створення на їх базі інформаційних систем порушила проблему створення методів захисту інформації (криптографічних) ще більш актуально. Це обумовлено двома причинами. Першою причиною є те, що різко розширилося використання комп’ютерних мереж, зокрема комп’ютерної мережі Інтернет, по якій передаються величезні обсяги інформації державного, військового та комерційного характеру, що не допускають можливості доступу до неї сторонніх осіб. Отже, всю цю інформацію потрібно надійно засекретити (зашифрувати). Другою причиною є те, що поява потужних комп’ютерних систем, технологій мереживних та нейтронних обчислень створили можливості для розкриття систем, які вважалися такими, яких практично розкрити неможливо. Виникла проблема створення на базі комп’ютерів нових більш надійних шифросистем. А для цього необхідна відповідна теорія їх побудови.
Для ефективного розв’язання проблеми захисту інформації створено спеціальну науку криптологію (kryptos – таємний, logos – наука). Криптологія має дві складові: криптографію та криптоаналіз. Криптографія займається пошуком та дослідженням методів засекречення (шифрування) інформації. Криптоаналіз досліджує можливості розшифрування інформації.
Другий напрям у теорії і практиці кодування тісно пов’язаний із проблемами ефективного передавання інформації каналами зв’язку, зберігання інформації.
Тут можна виділити три основних аспекти:
1) подання повідомлення (інформації) у вигляді, який є найбільш зручним для передавання його каналом зв’язку;
2) кодування повідомлення з мінімальною можливою кількісно двійкових символів (оптимальне кодування);
3) кодування повідомлення, яке забезпечує надійність одержання його адресатом без спотворень (завадостійке кодування).
Тема 8. Основи економного кодування.
План
1. Передавання інформації каналами зв’язку.
2. Теоретичні основи побудови економних кодів. Перша теорема Шенона.
3. Алгоритм Шенона—Фано для побудови економного коду.
4. Алгоритм Хаффмена для побудови оптимального коду
5. Оптимальні нерівномірні коди і проблеми стискування інформації
1. Передавання інформації каналами зв’язку
В усіх галузях людської діяльності доводиться мати справу з передаванням інформації. Специфіка різних видів діяльності вимагає різних специфічних систем передавання інформації. Наприклад, система передавання інформації телефонними каналами зв’язку не схожа на систему космічного зв’язку. Проте в принципах побудови та призначення окремих систем передавання інформації є чимало спільного.
Виділивши й проаналізувавши це, Клод Шенон запропонував у 1949р. структурну схему передавання інформації, яку подано на рисунку.
| Передавач |
| Лінія зв’язку |
| Приймач |
| Кодуючий пристрій |
| Декодуючий пристрій |
| Джерело інформації |
| Одержувач Інформації (адресат) |
Рисунок 1. Схема передачі інформації
За цією схемою можна передавати найрізноманітніші за фізичною природою повідомлення: цифрові дані, одержані від комп’ютера, мову, тексти програм, результати вимірювання фізичних величин тощо. Всі ці повідомлення попередньо повинні бути перетворені в електричні сигнали, які повністю зберігають властивості вихідних повідомлень, а тоді уніфіковані, тобто подані у формі, яка є зручною для наступної передачі:
Під джерелом інформації розуміють пристрій, у якому виконані перераховані вище операції.
Зазначимо тільки, що кожне джерело має свій алфавіт Хдж.= { x1,x2,...,xn }, за допомогою якого формуються повідомлення.
Для більш економного використання лінії зв’язку, а також зменшення впливу різних завад (шумів) і спотворень, інформація, що передається джерелом, знову перетворюється за допомогою кодуючого пристрою. Це перетворення, як правило, складається із цілого ряду операцій, які включають облік статистики інформації, що поступає для усунення надмірності (статистичне кодування), а також введення додаткових елементів для зменшення впливу завад (перешкод) та спотворювань (завадостійке кодування).
У результаті ряду перетворень на виході кодуючого пристрою утворюється послідовність елементів, яка за допомогою передавача перетворюється у форму, яка є зручною для передавання лінією зв’язку.
Лінія зв’язку — це середовище, в якому відбувається передача сигналів від передавача до приймача.
Урахування впливу середовища є необхідним.
Зауважимо, що в теорії передавання інформації часто трапляються поняття «канал зв’язку».
Канал зв’язку — це сукупність засобів, які забезпечують передавання сигналів. Лінія зв’язку може містити багато каналів зв’язку.
Канал зв’язку має дві визначні характеристики: пропускну здатність та перешкодозахищеність (завадозахищеність);
Пропускна здатність каналу (С) — це максимальна кількість біт, що передається по ньому за відсутності перешкод. Вона залежить від фізичних властивостей каналу.
Швидкість передавання інформації каналом (Н) — це кількість біт, які передаються за одну секунду. (1 бод = 1 біт/с).
Похідні одиниці для бода такі ж як і для біта та байта.
На вихід приймача, крім сигналів, як формує передавач, потрапляють також різноманітні перешкоди (шуми). Приймач виділяє із суміші сигналів і перешкод послідовність, яка повинна відповідати послідовності на вході кодуючого пристрою. Проте через дію перешкод, впливу середовища, похибок різних перетворень, таку відповідність одержати неможливо. Тому така послідовність уводиться в декодуючий пристрій, який виконує операції з перетворення її в інформацію, яка відповідає тій, що була передана. Повнота цієї відповідності залежить від якості коректування. Корекція повинна бути виконана так, щоб різниця між інформацією, яка одержується від джерела та інформацією, переданою одержувачу, була незначною і не перевищувала деякої допустимої величини. Основними показниками якості передавання інформації є її достовірність — ступінь відповідності прийнятого повідомлення тому, яке було передано.
Чисельно достовірність передавання інформації характеризується коефіцієнтом похибок: Кnox = Nnox / N, де Nnox - кількість неправильно прийнятих повідомлень; N — загальна кількість прийнятих повідомлень.
При збільшені N коефіцієнт помилок прямує до ймовірності помилкового прийму чи просто до ймовірності похибки.

2. Теоретичні основи побудови економних кодів. Перша теорема Шенона
Найважливішою складовою започаткованої Клодом Шеноном теорії інформації є теорія передачі інформації. Вона вивчає оптимальні й близькі до них методи передачі інформації каналами зв’язку за умови, що можливо змінювати методи кодування повідомлень у сигнали на вході каналу зв’язку і декодувати їх на виході.
В праці «Математична теорія зв’язку» Шенон запропонував розв’язання основної проблеми про знаходження швидкості передавання інформації, яку можна досягнути при оптимальному методі кодування та декодування так, щоб ймовірність помилки при передачі інформації була б як завгодно малою.
Зазначимо, що зберігання інформації можна розглядати як передавання інформації, але не в просторі, а в часі. Тому проблеми, пов’язані з оптимальним способом зберігання повідомлень, принципово не відрізняються від проблем оптимального передавання інформації каналами зв’язку без перешкод.
Перша теорема Шенона (для каналу без завад)
Сформулюємо її так, як це зробив сам Шенон.
Нехай джерело має ентропію Н (біт на символ), а канал має пропускну здатність С (біт за секунду). Тоді можна закодувати повідомлення на виході джерела таким чином, щоб передавати символи каналом із середньою швидкістю С / Н – ε символів за одну секунду, де ε — як завгодно мале. Передавати із середньою швидкістю, більшою ніж С / Н неможливо.
К. Шенон довів цю теорему двома різними способами.
У більш сучасній редакції першу теорему Шенона формулюють так:
Для каналу без завад кодування дискретних повідомлень можна здійснити так, щоб середня кількість двійкових знаків на елемент кодуючого алфавіту А була як завгодно близька до ентроропії джерела Н, але не менша за неї.
Першу теорему Шенона ще називають основною теоремою про кодування. Вона лежить в основі економного кодування.
Економним називається кодування, яке проводять з метою скорочення обсягу інформації та підвищення швидкості її передавання.
Економне кодування називають ще ефективним кодуванням, а також стискуванням даних.
В економному кодуванні користуються такими визначальними інформаційними характеристиками, як ентропія джерела, надлишковість джерела, середнє число символів у коді, надмірність коду.
1. Ентропія джерела повідомлень (див.7,п.4) визначається за формулою
Н (х)= – 
де  — ймовірність появи в повідомлення елемента (букви) джерела
— ймовірність появи в повідомлення елемента (букви) джерела  , а m — потужність алфавіту джерела.
, а m — потужність алфавіту джерела.
Якщо  =
=  , де
, де  =1,2,..., m, то Н (х)
=1,2,..., m, то Н (х)  =log
=log  m
m
2. Надмірність джерела. Реальні джерела з однією й тією ж потужністю алфавіту m можуть мати різну ентропію (тексти, музика, мова, зображення тощо). Тому вводять таку характеристику джерела повідомлень як надмірність
P  = 1- H (х)/ H (х)
= 1- H (х)/ H (х)  = 1- H (х)/log
= 1- H (х)/log  m, де Н (х) — ентропія реального джерела, log m — максимально досяжна ентропія для джерела з обсягом (потужністю) алфавіту в m символів.
m, де Н (х) — ентропія реального джерела, log m — максимально досяжна ентропія для джерела з обсягом (потужністю) алфавіту в m символів.
Наприклад, доведено, що для букв українського алфавіту (32, включаючи ь) реальна кореляція Н (х)=2,0 біт/букву (з урахуванням різної ймовірності букв у тексті та їх кореляцію). Оскільки максимально досяжна тут ентропія Н (х)  =log
=log  m =log
m =log  32=5,то
32=5,то
P = 1-(2 біти/букву) / (5 біт/букву)=0,6
Тобто при передачі тексту каналом зв’язку кожні 6 букв із 10-ти не несуть ніякої інформації.
3. Середнє число двійкових символів, що припадають на одну букву джерела повідомлення, визначається за формулою  , де l
, де l  — довжина коду, що відповідає букві x
— довжина коду, що відповідає букві x  , p (x
, p (x  ) — ймовірність букви x
) — ймовірність букви x  .
.
Для рівномірних кодів  дорівнює довжині слова
дорівнює довжині слова  .
.
4. Надмірність коду визначається за формулою P  =1 –
=1 –  Зіставимо ці характеристики для двох прикладів.
Зіставимо ці характеристики для двох прикладів.
Приклад 1. Джерелом повідомлень є алфавіт вісімкової системи числення А  = {0,1,2,3,4,5,6,7}. Букви його закодовані рівномірним тризначним кодом: 0↔000, 1↔001, 2↔010,..., 7↔111. Визначимо основні інформаційні характеристики джерела з таким алфавітом:
= {0,1,2,3,4,5,6,7}. Букви його закодовані рівномірним тризначним кодом: 0↔000, 1↔001, 2↔010,..., 7↔111. Визначимо основні інформаційні характеристики джерела з таким алфавітом:
1) Ентропія джерела Н (А  )
)  = log
= log  8=3;
8=3;
2) Надлишковість джерела
P = 1 –  ;
;
3) середнє число символів в коді дорівнює  (код рівномірний);
(код рівномірний);
4) надлишковість коду

Отже, надлишковість рівномірного коду дорівнює нулю.
Приклад 2. Візьмемо те ж джерело з алфавіту А  , але з різною ймовірністю появи букв у тексті (вісімковому числі), яку подано в таблиці 4.
, але з різною ймовірністю появи букв у тексті (вісімковому числі), яку подано в таблиці 4.
Таблиця 4
а 
| ||||||||
Р (а  ) )
| 0,04 | 0,01 | 0,015 | 0,1 | 0,6 | 0,025 | 0,01 | 0,2 |
1) Ентропія джерела Н (А  )= 1,781;
)= 1,781;
2) Середнє число символів при використанні цього рівномірного тризначного коду  ;
;
3) Надлишковість коду
P  = 1 -
= 1 -  ≈ 0,41.
≈ 0,41.
Отже, порівняно з результатами прикладу 1, надлишковість коду тут доволі значна. Вана свідчить про те, що в середньому 4 символи із 10 не несуть ніякої інформації.
Отже, при кодуванні нерівноймовірних повідомлень рівномірним кодом виникає велика надлишковість. Тому цілком логічною була пропозиція використати нерівномірні коди, довжина кодових слів яких була б узгоджена з ймовірністю появи різних букв у тексті.
При цьому нерівномірні коди повинні бути такими, щоб за кодовою послідовністю, побудованою на їх основі, можна було однозначно відновити початковий текст, без додаткових розділових знаків (повинні бути однозначно декодовані).
Тому при їх побудові важливе значення має теорема Мак-Міланна, яка стверджує, що для однозначного кодування має виконуватися співвідношення  , де k – загальна кількість кодових слів, l i - довжина i-того кодового слова, Q – основа (потужність) коду (Теорема 3.2).
, де k – загальна кількість кодових слів, l i - довжина i-того кодового слова, Q – основа (потужність) коду (Теорема 3.2).
Важливими економними кодами є коди без пам’яті, в яких кожний символ вектора, що кодується, замінюється кодовим словом із префіксної множини двійкових послідовностей чи слів.
Префіксна множина двійкових послідовностей S — це така множина, у якій жодний із її елементів не є префіксом (початком) жлдного іншого елемента цієї множини.
Наприклад, множина двійкових слів S1= {01,10,11,000,001} є префіксною множиною двійкових послідовностей, оскільки жоден її елемент не є префіксом будь-якого іншого елемента цієї послідовності. В цьому легко переконатися, якщо перевірити будь-яку із 20 можливих пар елементів множини S1.
Множина S2= {0,01,011,111} не є префіксною, оскільки її перший елемент є префіксом (початком) другого та третього елемента, а другий — третього.
Для побудови префіксного коду деякого повідомлення m = (m  , m
, m  ,…, m
,…, m  ) з алфавітом А користуються такими правилами [11,п.2.2]:
) з алфавітом А користуються такими правилами [11,п.2.2]:
1. Складають повний список символів a  , a
, a  , a
, a  ,…, a
,…, a  алфавіту А так, щоб вони були розташовані в міру спадання їх ймовірностей появи в m: на першому місці стоятиме символ, який найчастіше з’являється в m, на другому місці — менш часто і т.д.
алфавіту А так, щоб вони були розташовані в міру спадання їх ймовірностей появи в m: на першому місці стоятиме символ, який найчастіше з’являється в m, на другому місці — менш часто і т.д.
2. Кожному символу a  приписують (ставлять у взаємно однозначну відповідність) кодове слово
приписують (ставлять у взаємно однозначну відповідність) кодове слово  із префіксної множини двійкових послідовностей S.
із префіксної множини двійкових послідовностей S.
3. Вихід кодера одержують об’єднанням в одну послідовність усіх одержаних двійкових слів.
Але як для кожного конкретного випадку відшукати префіксну множину S? Які є необхідні та достатні умови для того, щоб існував відповідний префіксний код? Відповідь на ці запитання одержують на основі розгляду так званого вектора Крафта
Нехай S ={ v  , v
, v  ,…, v
,…, v  } — префіксна множина, а V (S)=(l
} — префіксна множина, а V (S)=(l  , l
, l  ,…, l
,…, l  ) — вектор, який складається з чисел, що є довжинами відповідних префіксних послідовностей, тобто l
) — вектор, який складається з чисел, що є довжинами відповідних префіксних послідовностей, тобто l  є довжиною (i=1,2,..,k).
є довжиною (i=1,2,..,k).
Вектор (l ,l ,…,l ), який складається з довільних чисел, що задовольняють умову l  ≤l
≤l  , називають вектором Крафта.
, називають вектором Крафта.
Для цього вектора виконується нерівність Крафта:
2  + 2
+ 2  +...+ 2
+...+ 2  ≤1 (3.7)
≤1 (3.7)
У теорії економних кодів дуже важливою є:
Теорема 3.3.
Для того щоб існував префіксний код з довжинами кодових слів l ,l ,…,l , необхідно й достатньо, щоб виконувалася нерівність Крафта (3.7).
Якщо нерівність (3.7) переходить у строгу нерівність, то такий префіксний код називають компактним. Такий код має найменшу серед усіх кодів, що побудовані для даного алфавіту А, довжину, тобто він є оптимальним.
Нехай необхідно побудувати код без пам’яті для стискування вектора даних m =(m  , m
, m  ,…, m
,…, m  ) з алфавіту А, потужність якого К. Для цього уведемо в розгляд так званий вектор частот P=(P
) з алфавіту А, потужність якого К. Для цього уведемо в розгляд так званий вектор частот P=(P  ,P
,P  ,...,P
,...,P  ) де P
) де P  — частота появи i -того символа з А в m. Закодуємо тепер Х кодом без пам’яті, для якого вектор Крафта l = (l , l ,…, l ). У цьому випадку кодова послідовність на виході кодера матиме довжину L (m)
— частота появи i -того символа з А в m. Закодуємо тепер Х кодом без пам’яті, для якого вектор Крафта l = (l , l ,…, l ). У цьому випадку кодова послідовність на виході кодера матиме довжину L (m)
L (m)=(l  * P 1+ l
* P 1+ l  * P
* P  +…+ l
+…+ l  * P
* P  ) (3.8)
) (3.8)
Легко зрозуміти, що кращим префіксним кодом є такий, для якого довжина L (m) мінімальна.
Для побудови такого коду потрібно знайти вектор Крафта l, для якого сума (3.8) була б мінімальною.
Це питання розглядатиметься в наступних параграфах.
Наприкінці даного параграфа розглянемо приклади простих префіксних множин і відповідних їм векторів Крафта. Подамо цю інформацію у вигляді таблиці 5.
Таблиця 5
| Префіксна множина | Вектор Крафта | |
| {0,10,11} | (1,2,2) | |
| {0,10,110,111} | (1,2,3,3) | |
| {0,10,110,1110,1111} | (1,2,3,4,4) | |
| {0,10,1100,1101,1110,1111} | (1,2,4,4,4,4) | |
| {0,10,1100,1101,1110,11110,11111} | (1,2,4,4,5,5) |
3. Алгоритм Шенона—Фано для побудови економного коду
На основі першої теореми Шенона (основної теореми про кодування) логічно виникає питання про побудову такого нерівномірного коду, в якому елементам повідомлення, що трапляються часто, присвоюються більш короткі кодові слова (кодові комбінації), а тим, що трапляються рідше – довші.
Першим, хто це зробив, виходячи з досвіду, був Морзе. Розповідають, що, створюючи свій код, Морзе ходив у найближчу типографію і підраховував число літер у набраних касах. Буквам і знакам, яких у цих касах було заготовлено більше, він зіставляв більш короткі кодові слова (адже ці букви трапляються частіше). Наприклад, в українському варіанті азбуки Морзе буква «Е» передається однією крапкою, а буква «Ш» — чотирма тире.
Ідею Морзе використали сучасні творці нерівномірних кодів, зокрема Шенон, Фано та Хаффмен. Методи побудови нерівномірних кодів уперше запропонували незалежно один від одного Роберт Фано та Клод Шенон.
Код Шенона—Фано є префіксним кодом. Алгоритм побудови цього коду забезпечує пошук вектора Крафта, який наближається до оптимального (але в загальному випадку не є ним). Основний принцип, який покладено в основу кодування за методом Шенона—Фано, полягає в тому, що при виборі кожного символу кодового повідомлення необхідно прагнути до того, щоб кількість інформації, яка міститься в ньому, була найбільшою. Це означає, щоб незалежно від значень усіх попередніх символів, цей символ приймав обидва можливі для нього значення („0” та „1”) за можливості з однаковою ймовірністю.

