




Ќад≥йний ≥нтервал. ѕерев≥рка статистичних г≥потез
ћета роботи:
навчитис€ застосовувати розрахунки над≥йного ≥нтервалу випадкових величин з метою анал≥зу в≥дпов≥дност≥ ознак друкованих та мультимед≥йних видань њхн≥м нормативам;
набути досв≥ду перев≥рки статистичних г≥потез стосовно р≥вн€ €кост≥ технолог≥чних процес≥в у сфер≥ пол≥граф≥њ та мультимед≥а.
Ќавчальний матер≥ал
1. ѕриклади закон≥в розпод≥лу де€ких випадкових величин
–≥вном≥рний розпод≥л. –≥вном≥рний розпод≥л ймов≥рност≥ Ї простим ≥ може бути €к дискретним, так ≥ неперервним.
ƒискретний р≥вном≥рний розпод≥л Ц це такий розпод≥л, дл€ €кого ус≥ значенн€ випадковоњ величини Ї р≥вноймов≥рними:
 ,
,
де k Ц к≥льк≥сть можливих значень випадковоњ величини.
–озпод≥л в≥рог≥дност≥ неперервноњ випадковоњ величини ’, €ка приймаЇ значенн€ з в≥др≥зку [а, b], називаЇтьс€ р≥вном≥рним, €кщо щ≥льн≥сть розпод≥лу випадковоњ величини на цьому в≥др≥зку Ї пост≥йною, а поза ним дор≥внюЇ нулю (рис. 4-5):

| (8) |

–ис. 4. √раф≥к функц≥њ F(x) р≥вном≥рного розпод≥лу

–ис. 5. √раф≥к функц≥њ f(x) р≥вном≥рного розпод≥лу
ƒл€ р≥вном≥рного розпод≥лу випадковоњ величини ’ математичне спод≥ванн€ Ї серединою в≥др≥зку [а; b]:
 , ,
| (9) |
 . .
| (10) |
Ќормальний розпод≥л. Ќормальним називаЇтьс€ розпод≥л ймов≥рност≥ неперервноњ випадковоњ величини, €кий описуЇтьс€ щ≥льн≥стю ймов≥рност≥
 , ,
| (11) |
де:
m ≠Ц математичне спод≥ванн€ випадковоњ величини,
≠  Ц середньоквадратичне в≥дхиленн€ випадковоњ величини.
Ц середньоквадратичне в≥дхиленн€ випадковоњ величини.
Ќормальний закон розпод≥лу займаЇ центральне м≥сце в теор≥њ ймов≥рност≥ ≥ математичн≥й статистиц≥. ÷е обумовлено тим, що нормальний закон про€вл€Їтьс€ у вс≥х випадках, коли випадкова величина Ї результатом д≥њ великого числа р≥зних чинник≥в. Ќаприклад, помилки вим≥рювань розпод≥лен≥ за нормальним законом.
Ќа практиц≥ багато випадкових величин розпод≥лен≥ нормально або майже нормально: помилки стр≥льби; в≥дхиленн€ напруги в мереж≥ в≥д ном≥налу; сумарна ви≠плата страхового товариства за довгостроковий пер≥од; дальн≥сть польоту снар€ду; зр≥ст чолов≥к≥в (ж≥нок) одного в≥ку ≥ нац≥ональност≥, й тому под≥бне (рис 6).

–ис. 6. √раф≥к щ≥льност≥ розпод≥лу випадковоњ величини, розпод≥леноњ за нормальним законом
ƒл€ випадкових величин, €к≥ розпод≥лен≥ за нормальним законом, д≥Ї правило трьох сигм.
ѕравило трьох сигм: €кщо випадкова величина розпод≥лена за нормальним законом, то ймов≥рн≥сть њњ в≥дхиленн€ в≥д свого математичного спод≥ванн€ на величину б≥льше н≥ж 3 , (де ≠ Ц середньоквадратичне в≥дхиленн€ випадковоњ величини), близька до нул€ (точн≥ше, дор≥внюЇ 0,0027). ≤ншими словами, практично достов≥рно, що нормальна випадкова вели≠чина приймаЇ значенн€ з ≥нтервалу [m-3 , m+3 ] (ймов≥рн≥сть цього дор≥внюЇ 0,9973).
2. Ќад≥йний ≥нтервал випадковоњ величини
Ќад≥йний ≥нтервал D випадковоњ величини з р≥внем дов≥ри (над≥йн≥стю) g Ц це ≥нтервал, €кий з ймов≥рн≥стю g покриваЇ вс≥ виб≥рков≥ значенн€ випадковоњ величини. “обто вс≥ виб≥рков≥ значенн€ випадковоњ величини з ймов≥рн≥стю g потрапл€ють в д≥апазон  , де
, де  Ц виб≥ркове середнЇ (рис. 7).
Ц виб≥ркове середнЇ (рис. 7).
|
|
|
≤нтервал D дл€ випадковоњ величини, €ка маЇ нормальний розпод≥л, визначаЇтьс€ за формулою:
| D = s Ј z, | (12) |
де:
s Ц середнЇ квадратичне в≥дхиленн€;
z Ц аргумент функц≥њ Ћапласа, €кий визначаЇтьс€ за допомогою в≥дпов≥дноњ таблиц≥ дл€ функц≥њ Ћапласа ‘(z): вибираЇтьс€ таке z, дл€ €кого виконуЇтьс€ умова: ‘(z) = g/2, де g Ц над≥йна ймов≥рн≥сть.
“аблицю з≥ значенн€ми функц≥њ Ћапласа подано у ƒодатку ј.
якщо не в≥доме середнЇ квадратичне в≥дхиленн€ σ, то у формул≥ розрахунку використовуЇтьс€ виправлене виб≥ркове середнЇ квадратичне в≥дхиленн€ s та коеф≥ц≥Їнт —тьюдента t:
| D = s Ј t, | (13) |
де:
t Ц коеф≥ц≥Їнт —тьюдента, €кий вибираЇтьс€ з в≥дпов≥дноњ таблиц≥ залежно в≥д значенн€ над≥йноњ ймов≥рност≥ g ≥ к≥лькост≥ ступен≥в свободи (к≥льк≥сть ступен≥в свободи дор≥внюЇ n Ц1).
“аблицю з≥ значенн€ми коеф≥ц≥Їнту t розпод≥лу —тьюдента подано у ƒодатку Ѕ.
«ауважимо, що при розрахунках над≥йного ≥нтервалу дл€ малоњ виб≥рки (при n<30) також використовуЇтьс€ коеф≥ц≥Їнт —тьюдента t (а не аргумент функц≥њ Ћапласа).



–ис. 7. ѕриклади над≥йних ≥нтервал≥в ≥з р≥зними значенн€ми над≥йноњ ймов≥рност≥
Ќад≥йний ≥нтервал Dм математичного спод≥ванн€ випадковоњ величини Ц це ≥нтервал, €кий з великою ймов≥рн≥стю м≥стить значенн€ математичного спод≥ванн€ випадковоњ величини.
Ќад≥йна в≥рог≥дн≥сть gм Ц це ступ≥нь упевненост≥ в тому, що дов≥рчий ≥нтервал м≥ститиме д≥йсне (нев≥доме) значенн€ математичного спод≥ванн€ генеральноњ сукупност≥.
¬еличина над≥йного ≥нтервалу Dм залежить €к в≥д над≥йноњ ймов≥рност≥ gм, так ≥ в≥д об'Їму виб≥рки n:
Dм=  . .
| (14) |
ѕриклад 1. Ѕ уло зд≥йснено виб≥рку 1600 ос≥б ≥з сукупност≥ ус≥х передплатник≥в журналу Ђ¬идавничий б≥знесї. —ередн≥й в≥к за виб≥ркою Ц 30 рок≥в, середньоквадратичне в≥дхиленн€ Ц 10 рок≥в. Ќеобх≥дно знайти над≥йний ≥нтервал математичного спод≥ванн€.
ѕерш за все, необх≥дно задати над≥йну ймов≥рн≥сть оц≥нки. ¬≥зьмемо 95% над≥йн≥сть. ќск≥льки виб≥рка велика, скористаЇмос€ таблицею значень функц≥њ Ћапласа (див. ƒодаток ј) ≥ знайдемо коеф≥ц≥Їнт дов≥ри z=1,96. “од≥ розрахуЇмо над≥йний ≥нтервал D випадковоњ величини за формулою (11):
D= 1,96*10=19,6.
«алишилос€ розрахувати над≥йний ≥нтервал математичного спод≥ванн€ формулою (13):
Dм=  =0,49.
=0,49.
« ймов≥рн≥стю 95% ≥стинний середн≥й в≥к у генеральн≥й сукупност≥ знаходитьс€ в ≥нтервал≥ в≥д 29,51 рок≥в до 30,49 рок≥в.
3. ѕерев≥рка статистичних г≥потез
—татистичною г≥потезою називають де€ке твердженн€ щодо значенн€ (або значень) €кого-небудь параметра випадковоњ величини. Ќаприклад, твердженн€ M(’)=5 (г≥потеза про те, що математичне спод≥ванн€ дор≥внюЇ п'€ти) або твердженн€ D(’)=D(Y) (г≥потеза про р≥вн≥сть двох дисперс≥й).
ѕ≥д процедурою перев≥рки статистичних г≥потез розум≥ють посл≥довн≥сть д≥й, €к≥ дозвол€ють з т≥Їю або ≥ншою м≥рою достов≥рност≥ п≥дтвердити або спростувати г≥потезу.
‘ормал≥зац≥€ статистичних г≥потез з математичноњ точки зору приводить до описанн€ г≥потез двох вид≥в:
Ќ0 Ц нульова г≥потеза,
Ќ1 Ц аль≠тернативна г≥потеза.
Ќульова г≥потеза (Ќ0) формулюЇтьс€ €к г≥потеза про в≥дсутн≥сть в≥дм≥нностей у виб≥рках, про схож≥сть двох розпод≥л≥в ≥ тому под≥бне. јльтернативна г≥потеза (Ќ1) протилежна за смислом ≥ означаЇ в≥дм≥нн≥сть у виб≥рках, в≥дм≥нн≥сть двох розпод≥л≥в ≥ тому под≥бне. ƒв≥ г≥потези утворюють повну групу несум≥сних под≥й: €кщо приймаЇтьс€ одна, то ≥нша в≥дхил€Їтьс€.
|
|
|
√≥потези перев≥р€ютьс€ за допомогою статистичних критер≥њв.
—татистичний критер≥й Ц це правило, €ке дозвол€Ї приймати ≥стинну ≥ в≥дхил€ти помилкову г≥потезу з високою ймов≥рн≥стю. ћатематично критер≥й Ї формулою, результатом розрахунк≥в за €кою Ї де€ке число. ритер≥й Ї випадковою величиною, розпод≥л €коњ залежить в≥д числа ступен≥в свободи.
ƒл€ встановленн€ схожост≥-в≥дм≥нност≥ середн≥х арифметичних значень в двох виб≥рках (€к≥ вибираютьс€ з генеральних сукупностей, що мають нормальний розпод≥л) використовуЇтьс€ t-критерий —тьюдента:
 , ,
| (15) |
де: s2 Ц виправлена виб≥ркова дисперс≥€,
n1 Ц обТЇм першоњ виб≥рки;
n2 Ц обТЇм другоњ виб≥рки.
≤нший вар≥ант формули:
 , ,
| (16) |
де: s2 Ц зм≥щена виб≥ркова дисперс≥€.
–озраховане за наведеними формулами емп≥ричне значенн€ критер≥ю —тьюдента зр≥внюЇтьс€ з критичним значенн€м цього критер≥ю. ритичне значенн€ критер≥ю —тьюдента вибираЇтьс€ з в≥дпов≥дноњ таблиц≥ (див. ƒодаток Ѕ) залежно в≥д р≥вн€ значущост≥ a (0,05; 0,01; 0,001) та к≥лькост≥ ступен≥в свободи f (f = n1 + n2 - 2).
якщо емп≥ричне значенн€ критер≥ю —тьюдента не перевищуЇ його критичного значенн€, то приймаЇтьс€ нульова г≥потеза про в≥дсутн≥сть статистично значимих в≥дм≥нностей середн≥х арифметичних значень в двох виб≥рках. ” протилежному випадку нульова г≥потеза в≥дхил€Їтьс€.
ƒл€ встановленн€ схожост≥-в≥дм≥нност≥ дисперс≥й в двох незалежних виб≥рках (€к≥ вит€гують з генеральних сукупностей, що мають нормальний розпод≥л) використовуЇтьс€ критер≥й ‘≥шера:
 , ,
| (17) |
де:  Ц б≥льша дисперс≥€,
Ц б≥льша дисперс≥€,
 Ц менша дисперс≥€.
Ц менша дисперс≥€.
–озраховане за наведеною формулою емп≥ричне значенн€ критер≥ю ‘≥шера зр≥внюЇтьс€ з критичним значенн€м цього критер≥ю. ритичне значенн€ критер≥ю ‘≥шера вибираЇтьс€ з в≥дпов≥дноњ таблиц≥ (див. ƒодаток ¬) залежно в≥д р≥вн€ значимост≥ a (0,05; 0,01; 0,001) ≥ к≥лькост≥ ступен≥в свободи. ≥льк≥сть ступен≥в свободи визначаЇтьс€ окремо дл€ чисельника та знаменника за формулами:
| f1 = n1 - 1, f2 = n2 - 1, | (18) |
де: n1 Ц обТЇм виб≥рки з б≥льшою дисперс≥Їю,
n2 Ц обТЇм виб≥рки з меншою дисперс≥Їю.
якщо емп≥ричне значенн€ критер≥ю ‘≥шера не перевищуЇ його критичного значенн€, то приймаЇтьс€ нульова г≥потеза про в≥дсутн≥сть статистично значимих в≥дм≥нностей дисперс≥й в двох виб≥рках. ” протилежному випадку нульова г≥потеза в≥дхил€Їтьс€.
«ауважимо що р≥вень значущост≥ a характеризуЇ ймов≥рн≥сть помилки в≥дхилити ≥стинну г≥потезу.
ѕриклад 2. ” двох друкарських цехах були проведен≥ заходи щодо п≥двищенн€ €кост≥ продукц≥њ. ” кожному цеху використовувалас€ сво€ методика п≥двищенн€ €кост≥. ƒо проведенн€ заход≥в в обох цехах мало м≥сце однакове розс≥юванн€ (розкид) параметр≥в виданн€. ѕ≥сл€ проведенн€ заход≥в в кожному цеху зд≥йснен≥ виб≥рков≥ досл≥дженн€ формату виданн€, результати €ких представлен≥ в таблиц≥ 4.
¬изначити, чи д≥йсно методика, використана в 1 цеху, дала найб≥льше вир≥внюванн€ параметр≥в видань (вз€ти р≥вень значущост≥ a=0,05).
“аблиц€ 4
–езультати досл≥дженн€ формату виданн€,
отриман≥ в двох цехах
| ѕоказник | 1 цех | 2 цех |
| к≥льк≥сть перев≥рених екземпл€р≥в виданн€ | ||
| виб≥ркова дисперс≥€ | 0,16 (мм) | 0,36 (мм) |
ƒл€ розвТ€занн€ ц≥Їњ задач≥ розрахуЇмо емп≥ричне значенн€ критер≥ю ‘≥шера:
F = 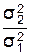 = 0,36/0,16 = 2,25,
= 0,36/0,16 = 2,25,
де: Ц дисперс≥€ формату виданн€ в 1 цеху,
Ц дисперс≥€ формату виданн€ в 2 цеху.
≥льк≥сть ступн≥в свободи:
f1=20,
f2=15.
ритичне значенн€ критер≥ю ‘≥шера знайдемо по таблиц≥, наведеноњ в ƒодатку ¬ (дл€ a=0,05):
Fк= 2,203.
ќск≥льки F > Fк, то ми робимо висновок про на€вн≥сть статистично значимих в≥дм≥нностей дисперс≥й в 1 ≥ 2 цеху. ќтже, методика, використана в 1 цеху, оказала б≥льший вплив на стаб≥л≥зац≥ю технолог≥чного процесу.

