




Информационно-статистические методика применяется также для выяв-ления лингвистических коррелятов для изменённых стрессогенных функцио-нальных состояний. Принципиальное различие между речевыми сдвигами при изменённых состояний сознания (ИСС), с одной стороны, и информационно-статистическими отклонениями эндогенного происхождения – с другой, зак-лючается в следующем. В первом случае эти сдвиги должны, по всей вероятно-сти, ослабевать по мере выхода испытуемого из стрессового состояния. Во вто-ром, как показывает клинический опыт, патологические речевые от-клонения имеют устойчивый характер, определяемый психическим недугом пациента.
Для проверки этого предположения были проведены пилотные исследования устных текстов, продуцированных женщинами – носительни-цами русского языка, испытывавших пред= и постродовой стрессы. Выбор та-кой модели стресса обусловлен тем, что медицинская практика свидетель-ствует о наличии у женщин в период беременности, родов и последующего ма-теринства особого психического состояния, связанного с временными качес-твенными перестройками в работе центральной нервной системы и общей организации функционального состояния в целом.
Эксперимент проводился в 2003 – 2005 годах. в НИИ акушерства и гинекологии им. Д.О.Отта (Санкт-Петербург) членами группы "Статистика речи" под руководством проф. Д.Л.Спивака (см. [71]). Всего в опыте приняло участие 36 рожениц в возрасте от 18 до 45 лет, без психопатологии в анамнезе, для которых русский являлся родным языком.
Эксперимент с каждой из рожениц проводился дважды – в предродовой (текст Э*) и послеродовый (текст Э**) периоды. Перед проведением каждого эксперимента информантки обследовались на наличие качественных измене-ний психического состояния и признаков ИСС. Каждой из испытуемых пред-лагалось рассказать о своих переживаниях в эти периоды. Все рассказы роже-ниц (нарративы) записывались на магнитофон, а затем переносились для ком-пьютерной обработки на ЭВМ-носители. Средний объем одного нарратива (Э* или Э**), полученного от одной роженицы, составляет в среднем около 2100 с/у. Общий объём устного текстового массива, полученного от всех испытуемых, равен примерно 151300 с/у.
Из нарративов было образовано два класса выборок. Первый класс включал две выборки, из которых первая представляла собой сумму всех предродовых
36 36
нарративов (ΣЭi*), а во второй суммировались постродовые тексты (ΣЭj**).
i=1 j=1
Всего получено 36 пар выборок, каждая из которых представляла нарративы одной испытуемой. В табл. 12 представлены данные по обеим коллективным выборкам.
Сопоставление полученных результатов с данными "нормальной" устной речи, полученными от практически здоровых носителей русского языка в возрасте от 20 до 25-ти лет, (табл. 12, стлб. 2 и 7 - 8), показывает, что стрессовая речь рожениц по значениям параметров γ, ρ и 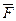 дает незна-чительные отклонения от статистических параметров современной разго-ворной речи. Об этом можно судить по характеризующим речь испытуемых в предродовом и в послеродовом состояниях. Это свидетельствует о том, что оба процесса находятся в целом в границах нормы.
дает незна-чительные отклонения от статистических параметров современной разго-ворной речи. Об этом можно судить по характеризующим речь испытуемых в предродовом и в послеродовом состояниях. Это свидетельствует о том, что оба процесса находятся в целом в границах нормы.
Вместе с тем величины ¡ и H заметно отклоняются от нормативных значений, что указывает на постепенное накопление каких-то речевых девиаций, свидетельствующих по всей видимости о тенденции к изменению РМД и его адаптации к необычным условиям. Одновременно обращает на себя внимание снижение величины параметра связанности текста ¡ у испытуемых в послеродовом состоянии, что соответствует наблюдаемому обычно у молодых матерей в этот период ослаблению ИСС и постепенному движению их РМД к нормальному состоянию.
Заключительные замечания.
Итак, описанные исследования имели следующиецель:
– обнаружить в текстах разных языков следы работы глубинных синергетических механизмов;
– получить по возможности их численные оценки;
– выбрать и развить экспериментальную методику, достаточно чувствительную в отношении лингво-синергетического феномена.
Среди информационно-статистических опытов, проводимых над текс-тами разных жанров и тематик, наиболее содержательный материал о синер-гетических механизмах речи в первую очередь удаётся получить, анализируя эндогенные речевые патологии, связанные с устойчивыми нарушениями пла-на содержания РМД носителей языка. Ведь, как говорил когда-то И.П.Павлов [42. С. 317-318], патологическое состояние “ открывает нам, расчленяя и упрощая, то, что было скрыто от нас в физиологической норме”.
Познавательная ценность синергетического анализа ПатР имеет несколько аспектов.
Во-первых, соотнесение информационно-статистических характери-стик патологических нарушений с соответствующими измерениями “нор-мальной” речи позволяет лингвистической синергетике очертить общий круг тех величин, которые предположительно выступают в качестве глубинных системных параметров РМД как у отдельной личности, так и у социума в це-лом. В этом состоит общетеоретическая ценности указанных сопоставлений.
Во-вторых, такие сопоставления дают технологический результат. Дело в том, что синергетический анализ непатологичеких текстов обнаруживает обычно недифференцируемое сочетание разнородных признаков, каждый из которых может сигнализировать о нескольких синергетических феноменах. Сравнительный анализ непатологической и патологической речи позволяет отсепарировать отдельные синергетические индикаторы от взаимодействую-щих с ним определителей.
В-третьих, получаемые показатели имеют прикладную диагностичес-кую ценность. Они не только cмогут надёжно отграничивать эндогенные психические заболевания от стрессогенных функциональных состояний и, возможно, от нейропсихологических нарушений. Эти параметры могут стать основой для объективных психолингвистичских методик, которые будут применяться не только в лечебной практике при диагностике психических расстройств, но и в условиях судебно-психиатрической экспертизы.
Глава 5. СИНЕРГЕТИКА И ИНФОРМАЦИОННЫЕ МОДЕЛИ ЯЗЫКА И ТЕКСТА*)
5.0. Вводные замечания
Термин информация служит обозначением очень емкого и широкого понятия, в основе которого лежат категории разнообразия и отражения. Этот термин трактуется двояко. С одной стороны, информация рассматривается как мера организации некоторого разнообразия (точнее, системы или процеc-са). С другой, информация может служить оценкой отражения од-ного разнообразия в другом. Это значит, что, если в ходе взаимодействия (коммуникации) систем или процессов А и В в системе (процессе) В произо-шли изменения, отражающие воздействие системы (процесса) А, то можно считать, что система В стала носителем информации о системе А.
*) Эта глава использует материалы и идеи, изложенные в работе автора: “Quantitative linguistics and information theory"// Quantitative Linguistik/ Quantitative Linguistics. Ein internationales Handbuch/ An International Handbook. Hgg von/ ed. by R.Köhler – G.Altmann – R.G.Piotrowski. Berlin – N.Y.: Walter de Gruyter,.2005. C. 857 – 878
Как показали в своей статье, посвящённой уточнению понятия ииформации, А.Г. Ханжин и А.А. Кожокару [77. C. 2] выделяется две группы вопросов в дефиниции этого понятия. К первой относится проблема уточнения природы информации через выявление её признаков. Вторая направлена на выяснение соотношния этого понятия в информационном тезаурусе со связанными с ним родового и видовых понятий для выявления через это соотношение существенных для окончательной дефиниции рассматриваемого понятия признаков. Опираясь на эти подходы, авторы рассматривают около тридцати определений понятия информации, которые обобщаются ими в следующее определение: “Информация – это идеальный коммуникативный феномен, проявляющийся в формах сигналов и записей, содержание которых сохраняется при их взаимном превращении и с помощью которых осуществляется управление или ментальный процесс” [77. C. 5 – 9]. Несмотря на некоторую расплывчатость этого определения, мы будем в дальнейшем ориентироваться на него, помня при этом, что оно
должно применяться к языку и РМД человека как к знаковой системе.
5.1. Виды информации и их измерения
Знаки, реализующие сообщение, имеют сложное построение. Поэтому РМД и коммуникативный процесс служат хранилищем и проводником раз-личных форм информации. Среди них с точки зрения создания ЛА и ОЛА интерес представляют следующие виды информации:
– п р а г м а т и ч е с к а я и., которая, рассматривая отношения знака и участников коммуникативного процесса (см. рис. 4, отношения R17→R1→R13, R14), количественно определяет ценность сообщения относительно целей как отправителя, так и приемника сообщения;
с и г м а т и ч е с к а я и., которая оценивает отношение между денота-том и отражаемым им референтом, т.е. фактом или объектом внешнего мира (R3); эта информация имеет обычно лексический характер;
– с е м а н т и ч е с к а я и., оценивающая отношение между десигна том и референтом (R5); ее можно подразделить на л е к с и ч е с к у ю и г р а м-м а т и ч е с к у ю в зависимости от того, заключена ли она в лексическом или грамматическом знаке (морфеме);
– к о н н о т а т и в н а я (стилистическая) и., которая описывает экспрессивные свойства знака (R2, R4, R15) и перспективы его переозначивания (т.е. вторичного семиозиса);
– с и н т а к т и ч е с к а я и., оценивающая статистику и комбинаторику сигналов.
Возможностям и приемам измерения этих видов информации, а также испо-льзованию результатов их измерений будут посвящены разделы 5.1, 5.5- 5.7.
При изучении РМД и коммуникативных процессов человек-человек и человек-машина наибольший интерес представляло бы измерение прагмати-ческой, сигматической и семантической информаций (в дальнейшем эти три вида информаций будут объединяться под названием смысловая и.). Ведь именно на смысловом уровне осуществляется во всей полноте реальный про-цесс речевого общения. К сожалению, при расчете смысловой информации необходимо иметь вероятностные оценки всех тех ситуаций, в которых могут оказаться коммуниканты, отправившие и правильно расшифровавшие осмыс-ленное сообщение. Поскольку относительно реальной коммуникации на есте-ственном языке эту задачу напрямую решить невозможно, информацион-ное описание текста приходится начинать с более доступного приема, како-ым является измерение синтактической информации. Здесь используется два подхода: комбинаторный и вероятнстный.
Первый предполагает, что переменная x способна принимать значения, принадлежащие множеству (алфавиту) А, которое состоит из S элементов (в нашем случае – букв, фонем, слов и т.д.). При использовании двоичных логарифмов, э н т р о п и я (т.е. неопределенность) переменной х будет равна H(x) = log 2 S bits. Указывая определенное значение х = i, мы снимаем эту эн-тропию и сообщаем синтактическую информацию (I), равную I= H(x) bits. Если переменные х 1, x 2 ,..., xn cпособны независимо пробегать множества, состоящие соответственно из S 1, S 2 …, S n элементов, то
H(х 1, x2 ,...,x n ) = H(x 1 ) + H( x2 ) + … + H(x n ) bits. (5.1)
Комбинаторный подход дает возможность оценить гибкость речи, т. е. оп-ределить степень разветвленности ее продолжения для обоих коммуникан-тов на каждом шаге текста. Т.о. появляется возможность оценить то струк-турное разнообразие, которое характеризует либо алфавит языка в целом, ли-бо потенциально возможный набор лингвистических единиц, употребляем-ых в данном участке текста. Энтропия и соответственно количество синтак-тической информации, характеризующие эти наборы, будут обозначаться символами Н 0 = I 0 .
Комбинаторный подход дает завышенные количественные оценки комбинаторно-статистической организации текста. Он не учитывает того об-стоятельства, что норма приписывает каждому элементу ЕЯ (фонеме, слову и т. д.) определенные вероятности его употребления в речи. Более содержате-льные результаты в информационных исследованиях дает второй – вероят-ностныйподход. Так, имея распределение только безусловных вероятностей p 1, р 2 ..., р S для элементов, образующих алфавит S, мы можем вычислить среднюю удельную энтропию первого порядка, приходящуюся на один элемент алфавита S. Она определяется как:
S
H I = - S p i log 2 p i bits. (5.2)
i=1
Задача усложняется, когда необходимо учесть изменения в распре-
делении вероятностей появления элементов алфавита в зависимости от их по-ложения в тексте. Энтропия рассчитывается тут, исходя из следующих сооб-ражений. Обозначим цепочку лингвистических элементов l 1, l 2, … l n-1 сим-волом b n-1. Она есть случайное событие, принимающее значение i. Непосред-ственно за цепочкой b n-1 следует позиция l n. Появление некоторого элемен-та в этой позиции также рассматривается как случайная величины, имеющая значение j k (1£ k £ S). Для каждого значения i, которое может принять b n-1,
имеется условная вероятность р (j i, k /b n-1i) того, что l nпримет значение j k. Средняя условная энтропия H n =In для позиции l n будет получена в результате осреднения энтропии, сосчитанной по всем b n-1i с весами, соответствующими вероятностям цепочек n-1. Тогда
S S
H n = – S p(b n-1i ) S р(j i, k / b n-1i ) log р (j i, k / b n-1i ) (5.3)
b n-1 k= 1
Эта величина показывает, какова в среднем неопределенность выбора лингвистического элемента в позиции n, когда известна цепочка n- 1. Если взаимосвязи элементов распространяются как угодно далеко, то энтропия на один лингвистический элемент будет равна
H¥= lim H n(n ®¥)
Величины средней условной энтропии и соответственно информации) зави-сят от распределения вероятностей элементов на n-м шаге текста и от вероятностей появления b n-1 Поэтому эти величины могут быть определе-ны из статистики k-элементых сочетаний по вытекающей из выражения (5.1) формуле:
H k = H (j/ b n-1i ) = H (b ni ) - H (b n-1i ) (5.4)
Так, H 3 =I 3, т.е. энтропию третьей буквы трехбуквенного сочетания, можно получить как разность энтропий три= и диграмм (H III - H II). Программно рас-считать оценки H II, H III, H IV для буквенных алфавитов из машинных корпус-ов текстов сейчас достаточно легко. Cуществуют также реалистичные спосо-бы оценки H I для слогов, слоговой и морфемной структуры слова, а кроме того при использовании частотных словарей для слов, с/ф и даже с/с [62. С. 140].
. Полученные с помощью вероятностной методики оценки H k= I k нахо-дятся ближе, чем H 0 = I 0, к истинным значениям синтактической информа-ции, характеризующей структуру текста. Однако и эти оценки представляют ограниченный интерес для теоретического и прикладного языкознания. Во-первых, эти методы не дают возможность проследить распределение инфор-мации на глубину не более четырех буквенных шагов текста (соответственно два слога). Во-вторых, получаемые из буквенной статистики величины
H k = I k, отражают только синтактическую информацию, характеризующую разнообразие источника сообщения и возможно некоторые структурные осо-бенности того языка, на котором передано сообщение. Численные оценки, полученные из анализа лексической статистики, содержат слитые воедино смысловую и синтактическую информации, которые разъединить невозмож-но. В-третьих, описанные измерения производятся в отвлечении от информа-ционых свойств приемника сообщения и механизма его декодирования, ко-личественные характерики которых представляют особый интерес для при-кладной лингвистистики и информатики.
Оценить величину информации, извлекаемой адресатом из разных уча-стков текста, в том числе из достаточно удаленных от его начала, можно только экспериментальным путем, наблюдая выходные реакции адресата-приёмника на получаемые им лингвистические сигналы. В нашем случае та-ким приёмником может выступать или коллектив испытуемых, или один ад-ресат. И в том и другом случае адресат может быть носителем исследуемого языка, а может быть и иноязычником (подробнее см. ниже).
Эксперимент с носителями языка имеет обычно целью получить мак-симально приближённые к реальной действительности информациионно-синергетические характеристики исследуемого языка. Для решения этой за-дачи необходимы два условия.
Во-первых, должна существовать уверенность, что РМД коллективно-го адресата или индивидуального испытуемого опирается в ходе эксперимен-та на достаточно полный тезаурус и лингвистическую компетенцию в данном языке, включая и профессиональные знания, если речь идет о специальном подъязыке. Кроме того, ЛК и Θ испытуемого должны содержать достаточно полные знания о валентностях лингвистических единиц и вероятностях их появления в тексте.
Во-вторых, испытуемые должны находиться в бодром состоянии, а их психика и нервная система не может обнаруживать каких-либо отклонений. Наконец, реакции адресата должны иметь такой вид, который был бы приго-ден для применения процедур измерения информации.
Всем этим условиям отвечает описываемый ниже эксперимент по уга-ыванию текста “образцовыми” носителями языка. Он организован следую-щим образом. У экспериментатора имеется текст, полностью или частично неизвестный испытуемым. Последние должны восстановить неизвестную часть текста, последовательно отгадывая его буквы (иероглифы, слоги, фоне-мы). Решая эту задачу, угадчик или коллектив угадчиков исходит из своей убежденность по поводу того, какие лингвистические единицы более пред-почтительны в данной позиции текста. Такая убежденность опирается на:
- содержание уже расшифрованной части текста (цепочка n -1);
- заложенные в тезаурус и лингвистическую компетенцию угадчика субъективные вероятности возможных продолжений;
- собственную оценку содержания текста и ситуацию общения;
- вспомогательный статистический [72] и лексикографический аппарат. Имея эти сведения, угадчик формирует для каждой следующей позиции текста спектр вероятностей возможных букв (слогов, морфем и т.п.). Каждый спектр отражает разнообразие и неопределенность в выборе продолжения. Приме-няя к спектру соответствующую математическую процедуру, можно оценить энтропию, равную той информации, которую получает адресат после того, как ему сообщено правильное продолжение текста.
Как уже было сказано, применяется два вида угадывания – коллек-тивное и индивидуальное.
Коллективное угадывание.
Этот вид угадывания используется в тех случаях, когда к опыту мож-но привлечь большой коллектив испытуемых. Угадывание осуществля-ется здесь по следующей схеме. Испытуемым предлагается предсказать букву, находящуюся в n -ой позиции текста или слова при условии, что предшест-вующая этой букве n -1 буквенная цепочка испытуемым известна. Каждый из испытуемых записывает независимо от других участников наиболее вероят-ную с его точки зрения букву для n -ой позиции. После этого эксперимента-тор сообщает испытуемым правильное решение и они переходят к угдыа-ванию буквы в n +1-ой позиции. Частное от деле-ния числа испытуемых, предложивших букву i для n -ой позиции текста на общее количество угад-чиков можно рассматривать как оценку условной вероятности pi /n- 1 появления i -той буквы в n -ой позиции текста.
Коллектив испытуемых подбирается для эксперимента с целью стать устройством, опирающимся на идеальный тезаурус и полную линг-вистическую компетенцию. Это позволять такому устройству предсказывать появление букв оптимальным образом. Потому на каждом шаге текста наи-большее число предлагаемых испытуемыми продолжений должно приходи-ться на наиболее вероятную для данной позиции букву. Следующее количе-ство предложений даст вторая по вероятности буква и т.д. В итоге, используя языковое чутьё испытуемых относительно родного языка, мы получаем для каждой n -ой позиции текста спектр относительных частот букв, близкий к распределению их вероятностей в рассматриваемой позиции текста. Обрабо-тка этого спектра с помощью выражения 5.2 даёт численную оценку величин H n = I n для каждой буквенной позиции исследуемого текста.

