




Множество всех дискретных состояний образует дискретное пространство состояний (далее просто пространство состояний): S = {s1, s2, …, sm}, где m количество всех состояний множества S. Всякое состояние si из S характеризуется множеством признаков K = {k1, k2, …, kn}.
1)подмножество родовых признаков состояний KR ⊆K,
2)подмножество видовых признаков состояний KV ⊆ K.
Пространство состояний можно охарактеризовать отношением «часть – целое»: 
где Si подмножества множества S.
Причем должно быть выполнено условие 
Отношение «часть – целое» обуславливает то, что пространство состояний включает в свой состав:
1) подмножество So начальных состояний
2) подмножество St целевых состояний.
3) подмножество Sс текущих состояний.
Важным понятием, используемым при решении задач в пространстве состояний, является понятие пространство поиска SR. Необходимость введения понятия SR продиктовано, прежде всего, возможными ситуациями, когда пространство состояний состоит из нескольких несвязных подпространств состояний, каждое из которых представляет собственное пространство поиска.
В отличие от пространства состояний для пространства поиска выполняется следующее условие. Для любой пары состояний (si, sj) ∈ SR всегда найдется одна и более цепочек операторов Li = (f1, f2, …, fn), применение которой к состоянию si приведет к состоянию sj. Причем все текущие состояния, представляющие некоторый путь от состояния si до состояния sj, также будут принадлежать данному пространству SR. Следовательно, множество SR – это всегда связная область.
Между пространством состояний и пространством поиска существуют следующие отношения: S ⊇ SR и
|S | ≥ |SR|. Пространство поиска в составе пространства состояний образуется за счет дальнейшего обобщения видовых признаков некоторых состояний.
Организацию состояний можно отобразить с помощь матриц смежности и инцидентности. Матрица инцидентности позволяет представить отношения между количеством входящих и выходящих дуг некоторой вершины xiÎG:
[aij] xi,yj = [n * m],
где aij – отношение инцидентности дуги yj к вершине xi орграфа G, n – количество строк вершин орграфа, m - количество столбцов дуг орграфа.
Отношение aij обозначается «1», если дуга yj выходит из вершины xi, иначе «0» (если дуга yj входит в вершину xi).
Видовые признаки:
1) расположение вершин в пространстве,
2) порядок,
Родовые признаки:
1) цифры,
2) количество цифр(4 цифры),
3) количество расположений вершин.
Анализ матрицы смежности для прямого правила:
Матрица симметрична относительно главной диагонали, а главная диагональ состоит из нулей. Матрица состоит из совокупности матриц для орграфов «Дерево» и «Кольцо».
Орграф состоит из множества колец. Каждое кольцо содержит три вершины. Из каждой вершины выходит три кольца. Отсутствуют корневые и терминальные вершины. Каждая вершина имеет равное количество входящих и исходящих вершин (три входящих и три исходящих). Одна из связей дублирует сама себя – то есть из одной вершины xi направлена связь к другой xi+1, из которой в свою очередь тоже направлена связь на эту вершину xi.

Анализ матрицы смежности для обратного правила:
Матрица симметрична относительно главной диагонали, а главная диагональ состоит из нулей. Матрица состоит из совокупности матриц для орграфов «Дерево» и «Кольцо».
Отсутствуют корневые и терминальные вершины. Каждая вершина имеет равное количество входящих и исходящих вершин (три входящих и три исходящих). Две связи дублируют самих себя. Внутри орграфа имеются прямоугольные плоскости.
Между состояниями пространства поиска существует отношение «род-вид»:
Родовые признаки:
1. Элементы пространства состояний – цифры.
2. Равное количество цифр – числа четырехзначные.
3. Нет корневых и терминальных вершин.
4. Количество связей (шесть связей). Выходит 3 связи (n-1) и 3 связи входят (n-1).
5. У каждой вершины есть хотя бы одна связь, которая повторяется.
6. Если поменять местами соседние цифры в вершине – то вершина станет принадлежать другому подпространству.
Видовые признаки:
1. Правила перебора (прямое правило, обратное правило).
2. Количество вершин.
3. Расположение в пространстве.
4. Без повторяющихся связей орграф, образованный прямым правилом, имеет пять связей, а орграф, образованный обратным правилом – четыре связи.
Между состояниями пространства поиска существует отношение «часть-целое», так как имеется подмножество начальных состояний, из которых начинается поиск, подмножество целевых состояний, где поиск заканчивается, и подмножество текущих состояний, которое является промежуточным звеном.
Вывод:
Всякое состояние характеризуется множеством родовых и видовых признаков.
Представление пространства состояний в виде орграфа G = (X{xi},Y{yj}) позволяет выделить дополнительные свойства и организацию состояний:
1) если |Yin{yj}| = 1 и |Yout{yj}| = 1, то орграф представляет собой
кольцо;
2) если |Yin{yj}| =  и |Yout{yj}| = , то граф является несвязным;
и |Yout{yj}| = , то граф является несвязным;
3) если |Yin{yj}| = 1 и |Yout{yj}|≠ 1, то орграф представляет собой
расходящееся от корня дерево;
4) если |Yin{yj}| ≠1 и |Yout{yj}| = 1, то орграф представляет собой
сходящееся к корню дерево;
5) если |Yin{yj}|≠ 1 и Yout{yj}= , то вершина является терминальной;
6) если |Yin{yj}| = и |Yout{yj}| ≠ 1, то вершина является корневой.
Матрица смежности позволяет представить бинарные отношения между вершинами орграфа.
Матрица инцидентности позволяет представить отношения между количеством входящих и выходящих дуг вершин орграфа.
Условия задачи.
Описание метода А*:
Методы реализуются в следующих условиях:
1) задано одно начальное и целевое состояние;
2) оценочная функция f (x) определена для всех состояний простран-
ства поиска;
3) относительно оценочной функции пространство поиска должно
быть монотонно;
4) состояния в пространстве поиска связны.
Предварительно, до начала поиска, задается оценочная функция следующего вида: f (x) = g (x) + h (x), где g (x) – расстояние от начального до текущего состояния, h (x) – оценка, представляющая отличие свойств текущего и целевого состояния.
Алгоритм поиска А* включает следующие этапы:
1. Раскрыть очередное состояние si Å Fi=Si+1
2. Если $ siÎ Si, º sjtÎSt, то задача решена, иначе – п. 3.
3. Выбрать из Si состояния si, для которых оценка f (x)min, а операторы, образовавшие данные состояния, записать в цепочку Li = { f 1, f 2, … fi- 1, fi,…}. Далее перейти к п. 1 для si.
В алгоритме А* используется генерация в глубину. Однако выбор
очередного si определяется значением f (x). Для выделения минимального
пути используется соответственно значение f (x)min. Причем анализ значений f (x) состояний в алгоритме А* происходит только на текущем фронте.
Так, в алгоритме А* осуществляется эвристическое управление направлением поиска.
При применении алгоритма А* возможна ситуация, в которой некоторое подмножество состояний фронта будет иметь тождественные оценки f (x)min (свойства состояний в пространстве поиска распределены немонотонно относительно принятой системы оценок).
Такое событие ставит под сомнение эффективность априорной эвристической функции. В алгоритме А*, как и в задаче про волка, зайца и капусту, в этом случае осуществляется раскрытие всех состояний текущего фронта, имеющих минимальную оценку. В дальнейшем это обычно приводит к существенному увеличению ресурсных затрат в связи с экспоненциальным ростом последующих текущих фронтов.
В результате искомый путь может включать в себя неопределенные, альтернативные участки такого вида: Li = { f 1, f 2, …, Fi- 1, Fi, Fi+ 1, … fn },
где "| Fi | > 1.
Для преодоления таких участков необходимо в корне изменить схему оценки состояний применяемую в алгоритме А*. В первую очередь
стоит принять во внимание то, что оценка состояний происходит только на текущем фронте без учета прошлых оценок текущих состояний. Такое решение разработчиков алгоритма А* является следствием того, что оценка g (x) с каждой итерацией увеличивается на единицу. Если даже оценка h (x) будет иметь относительно предыдущих итераций меньшее значение, то за счет роста g (x) суммарное значение f (x) будет относительно большим.
Предполагается, что сравнение оценок состояний должно происходить не
только на текущем фронте (как это выполняется в алгоритме А*), но и относительно оценок состояний всех ранее полученных фронтов.
В результате алгоритм поиска примет следующий вид:
1. Раскрыть очередное состояние si Å Fi=Si+1
2. Если $ siÎ Si, º sjtÎSt, то задача решена, иначе – п. 3.
3. Для всех siÎ Si определить значение оценки f (x) и записать в память MF (x), перейти к п. 4.
В памяти MF (x) хранятся оценки f (x) всех ранее раскрытых состояний
в ранжированном виде. При записи новых состояний в MF (x) их оценки
ранжируются вместе с ранее раскрытыми состояниями. Причем ранее раскрытые состояния должны быть помечены.
Следует также отметить, что в механизме управления формированием памяти должна быть предусмотрена работа алгоритмов, учитывающих наличие терминальных состояний и колец (повторов).
Отличие MF (x) от MS, применяемой в методе Мура, заключается в том, что оригинальные состояния ранжируются на основе оценки f (x), а не на основе порядка поступления.
4. Выбрать из MF (x) любое состояние si, ранее не раскрытое, для которого оценка f (x)min; если таких нет, то выбрать любое состояние, для которого f (x)min.
5. Оператор fi, образовавший очередное состояние, записать в цепочку Li = { f 1, f 2, … fi- 1, fi, …}, далее перейти к п. 1 для состояния si.
В программе алгоритм A* будет реализован в работе принцессы, а алгоритм с памятью будет реализован у преследователя.
4. Создание программы, реализующей работу алгоритмов А*:
Для количества поисков 500:

Для количества поисков 1000:
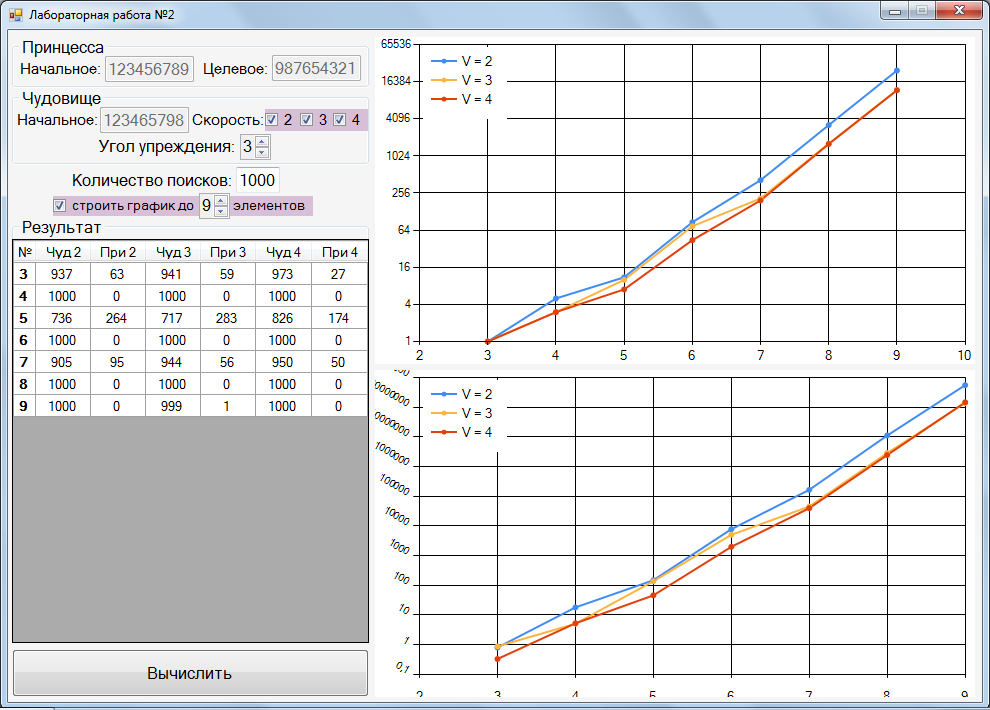
Для количества поисков 1500:

Выводы.
В ходе проведения лабораторной работы замечено, что алгоритм преследования с упреждением эффективнее, так как «чудовище» перехватывало «принцессу» чаще при использовании именно этого алгоритма.
Для сравнения алгоритмов преследования, надо определиться с критериями сравнения и с исходными ограничениями, что и с какой точностью замеряется. В зависимости от объема информации, вычислительных мощностей, которыми обладает преследователь, можно определить какой алгоритм преследования предпочтителен в данных условиях.
Анализируя классические методы преследования можно выяснить, что по помехоустойчивости и простоте реализации на первом месте стоит метод погони, а затем уже идут методы постоянного угла упреждения, пропорционального наведения, параллельного сближения. По точности наведения, требуемому нормальному ускорению, вероятности ошибки, гладкости траектории на первом месте стоит метод параллельного сближения, а затем следуют методы пропорционального наведения, постоянного угла упреждения и метод погони.
Оценивая игровые алгоритмы преследования, можно сделать вывод, что они более помехоустойчивы, чем соответствующие оптимальные алгоритмы преследования.
На основании вышесказанного можно сформулировать общий принцип: чем жестче требования к точности и сложнее условия наведения, тем совершеннее и сложнее должен быть алгоритм наведения. В то же время, чем сложнее алгоритм наведения, чем больше ему требуется информации, тем меньшую помехоустойчивость он обеспечивает, и тем больше ужесточаются требования к точности измерений.
В последнее время в вычислительной технике продолжается прогресс в повышении быстродействия вычислительных средств и одновременном уменьшении их физических размеров, поэтому в новых разработках предпочтение отдается сложным, но более точным алгоритмам, а не простым в реализации, но менее точным. Так как разница по времени реализации этих алгоритмов мала, то нет необходимости поступаться точностью наведения ради скорости и оперативности вычислений.

