




Фундаментальным понятием математической статистики является понятие группы, или совокупности, которое обычно определяется как генеральная совокупность. Генеральная совокупность — это совокупность, множество элементов, обладающих каким-то одним или многими признаками[119].
Признак является переменной величиной для каждого элемента генеральной совокупности и называется вариантой.
Количественная варианта может быть прерывной (дискретной н непрерывной. Если дана генеральная совокупность N лиц, которые изучаются, например, по своему доходу, то в этом случае варианта (доход) является непрерывной величиной, которая может в определенных пределах принимать любые значения. Если же эти N лиц изучаются по их семейному положению, например, какова величина семьи, в которой живет данный индивид, то в этом случае варианта является величиной прерывной, поскольку она может принимать только целочисленные значения 1, 2, 3... и т.д.
Рассмотрим случай прерывной варианты.
Предположим, что дана генеральная совокупность объема N, каждый элемент которой характеризуется прерывной вариантой Х. Как можно охарактеризовать эту генеральную совокупность по данному признаку (варианте)?
Самый естественный и простой путь — сгруппировать члены генеральной совокупности по всем возможным значениям признака. Сначала группируем элементы генеральной совокупности, имеющие наименьшее значение варианты, а именно значение X1. Затем члены, имеющие значения X2, X3 … и т.д. Наконец, отбираем члены, имеющие наибольшее значение варианты — Xk. Количество членов генеральной совокупности в каждой группе, соответствующей определенному значению варианты, называется частотой варианты X и обозначается через ni.

В результате мы получаем два ряда чисел, которые можно расположить один под другим таким образом:
X1 X2 … Xi … Xk
nx n1 n2 … ni … nk
Получилась таблица, которая дает частотное распределение варианты X в генеральной совокупности. Очевидно, что 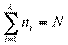 .
.
Иногда частотное распределение представляют графически: на оси X откладывают значение варианты, на оси Y — частоту. Полученные точки соединяют ломаной, которая называется полигоном распределения (рис. 1).
Ломаную принято соединять с осью X в смежных точках оси X, в которых, полагают, частоты равны 0 (в данном случае в точках X0 и Xk+1).
В том случае, если варианта – непрерывная величина, дело несколько усложняется: нельзя непосредственно сгруппировать элементы генеральной совокупности по значениям варианты, поскольку может оказаться, что каждый член имеет свое, отличное от других значение варианты. Тогда поступают следующим образом. Предположим, что все значения варианты находятся на отрезке [a, b]. Этот отрезок разбивают на n равных
частей, которые называют разрядами, интервалами, классами или класс-интервалами. Отбирают члены генеральной совокупности, варианты которых попадают в первый класс-интервал, затем элементы, попавшие во второй класс-интервал, и т.д. вплоть до последнего n-ro класс-интервала. Число элементов генеральной совокупности, попавших в определенный класс-интервал, называется частотой этого класс-интервала. Очевидно, что класс-интервал определяется по формуле
Äx= 
Выбор n зависит от многих причин и должен быть таким, чтобы класс-интервал был не очень малым (чтобы класс-интервалов было не слишком много) и не очень большим (чтобы не исчезла специфика изменения варианты).
Существует ряд приближенных формул для определения не- обходимого Äх, а также ряд допущений в отношении значений варианты на границах класс-интервалов, за которыми мы отсылаем к соответствующей литературе[120].
Частотное распределение (в случае непрерывной варианты) будет иметь следующий вид:
Класс-интервалы I II III…
Частоты 

 …
…
В класс-интервалы кроме первого и последнего включаются варианты по своему значению больше нижней грани и равные верхней грани или меньше ее и условно принимается, что члены генеральной совокупности, попавшие в данный класс-интер- вал, имеют одинаковую варианту, равную середине данного класс-интервала.
Частотное распределение в случае непрерывной варианты также может быть изображено графически.
На оси Х прямоугольной системы координат отмечаются точки а и b нижней и верхней грани изменения варианты. Определяется класс-интервал. На интервале (а, b) откладываются выбранные класс-интервалы. На каждом класс-интервале как на основании строится прямоугольник с высотой, пропорциональной частоте этого класс-интервала. Верхние основания всех построенных таким образом прямоугольников образуют некоторую ступенчатую линию, называемую гистограммой, ко-
торая и является графическим изображением данного частот- ного распределения (рис. 2).
Если соединим середины верхних оснований прямоугольни- ков гистограммы, то получим полигон данного распределения. Тем самым генеральную совокупность непрерывной варианты можно представлять двумя видами графиков — полигоном и гистограммой, а прерывной варианты — только одним видом —

полигоном. Площадь всей гистограммы пропорциональна объе- му генеральной совокупности.
Иногда вместо частоты применяют относительную частоту, равную отношению частоты к объему генеральной совокупности.
Если мы исследуем данную генеральную совокупностЬ по варианте Х, то прежде всего мы получаем частотное распределение, которое может быть представлено в виде таблицы или графика. Полученное в процессе исследования частотное распределение называется эмпирическим распределе- нием.
Возьмем эмпирический полигон какой-либо непрерывной варианты. При достаточно большом объеме генеральной совокупности N будем одновременно увеличивать число и, следовательно, одновременно уменьшать величину класс-интервалов. У полигона будет увеличиваться число все уменьшающихся звеньев, и если продолжать этот процесс до бесконечности, то в пределе полигон перейдет в некоторую гладкую кривую, которая называется кривой распределения.
Каждый полигон эмпирического распределения является некоторым приближением определенной кривой распределения (рис. 3).
Эта кривая распределения, являющаяся предельным случаем полигона данного эмпирического распределения, называется по установившейся терминологии функцией плотности распре- деления и обозначается f (х). Интеграл от нее по области
изменения варианты называется функцией распределения и обозначается
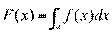
Иногда f(x) и F(x) называют дифференциальным и интегральным законами распределения соответственно.
Возьмем какие-то эмпирические гистограмму и полигон и соответствующую им кривую распределения (рис. 4).

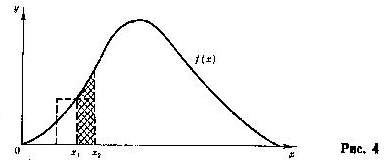
Гистограмма и полигон в пределе стремятся к кривой распределения f(x). По определению гистограммы, частота значений варианты Х равна площади прямоугольников, построенных на класс-интервалах. Частота события по частотному определению вероятности при бесконечном увеличении числа испытаний стремится к вероятности события[121].
Следовательно, для кривой распределения площадь под ней между значениями х, и х, это вероятность того, что варианта
примет значения между 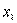 и
и  [122]. Это можно записать таким образом:
[122]. Это можно записать таким образом:
 .
.
Частотные распределения обычно характеризуются двумя типами параметров:
I — параметры положения или средние;
II — параметры или меры рассеивания.
Наибольшее значение имеют три вида средних: средняя арифметическая, медиана и мода.
Средняя арифметическая (М) для прерывной варианты reнеральной совокупности объема N определяется выражением

или

где k — яисло различных значений:варианты Х, а 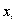 — значения
— значения
варианты.
Для непрерывной варианты Х, изменяющейся в интервале
{а, b} генеральной совокупности объема N,

где f(х) — функция плотности распределения. Иначе говоря, средняя арифметическая есть абсцисса центра тяжести площади фигуры, образованной кривой распределения и осью абсцисс.
Медиана (Me) — это такое значение варианты, когда половина генеральной совокупности имеет значения меньше его, половина — больше.
Геометрически медиана означает абсциссу прямой, которая делит пополам площадь под кривой распределения.
Мода (Md) — значение варианты, соответствующее наибольшей частоте (вероятности). Графически мода — это значение абсциссы самой высокой точки кривой распределения (рис. 5).
Для симметричного распределения средняя арифметическая медиана и мода совпадают.
В качестве меры рассеивания наиболее распространены понятия дисперсии и квадратного корня из дисперсии, который называется стандартом или средним квадратическим отклонением.
Дисперсия есть средний квадрат отклонения варианты от ее среднего арифметического; она обозначается  .
.

стандарт :

На рис.6 кривая I характеризуется малой дисперсией; кривая II — большой дисперсией.

Наибольшее значение для социологических исследований имеют три теоретических закона распределения.
1) Нормальное распределение, или распределение Гаусса (для непрерывной варианты):


2) Биноминальное распределение, или распределение Бернулли (для прерывной варианты).
Если при каждом испытании вероятность осуществления события есть р, неосуществления — q=1 — р, то вероятность того, что при и испытаниях это событие осуществится т раз, равна

3) Распределение Пуассона, или закон малых чисел, представляет собой предельный случай биноминального распределения: когда  , a
, a  , то, обозначая np=a, имеем
, то, обозначая np=a, имеем

Это распределение имеет место в случае большого числа испытаний маловероятных событий.
Статистический вывод
Статистика имеет дело с большим числом предметов и явлений, которые образуют генеральную совокупность. Однако исследователь обычно имеет дело с ограниченной частью генеральной совокупности, называемой выборочной совокупностью, или просто выборкой, по изучению которой он делает определенные выводы о генеральной совокупности[123].
Каковы же математические основания этих выводов?
Если F (х) — интегральная функция распределения генеральной совокупности, определяющая вероятность того, что х<Х, и если  (х) — эмпирическая функция распределения выборки, то по теореме Бернулли при бесконечном увеличении объема выборки эмпирическое распределение по вероятности стремится к распределению теоретическому:
(х) — эмпирическая функция распределения выборки, то по теореме Бернулли при бесконечном увеличении объема выборки эмпирическое распределение по вероятности стремится к распределению теоретическому:
 .
.
Характеристики распределения генеральной совокупности принято называть параметрами  , а характеристики выборочного распределения — оценками параметров
, а характеристики выборочного распределения — оценками параметров 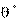 .
.
Статистическую выборку можно производить многократно, используя множество способов, и всякий раз будут получаться новые значения оценок параметров.
Следовательно, каждый параметр имеет выборочное распределение оценок. В этой связи вводится понятие точности оценки 
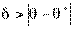
и надежности (или доверительной вероятности) у как вероятности того, что  <
< 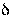 , а именно
, а именно 
При исследовании генеральной совокупности, подчиняющейся нормальному закону, находят оценки параметров а и ; в случае распределения Пуассона — оценку параметра m.
Результат, полученный в выборке (обычно это среднеарифметическое или дисперсия), еще мало о чем говорит. Необходимо определить точность () и надежность ( ) этой оценки. Без этого результат выборки не имеет смысла, поскольку оценка пара- метра является случайной величиной.
) этой оценки. Без этого результат выборки не имеет смысла, поскольку оценка пара- метра является случайной величиной.
Точность оценки рассчитывается при определенных предположениях о распределении в генеральной совокупности. Может случиться, что генеральная совокупность отклоняется от предполагаемого теоретического распределения и, следовательно, расхождение эмпирического и теоретического распределения обусловлено не случайностью выборки, а тем, что данная генеральная совокупность характеризуется другим теоретическим распределением.
Всякое предположение о распределении генеральной совокупности называется статистической гипотезой. Встает проблема проверки статистической гипотезы. Гипотеза может касаться общего вопроса соответствия выборочного эмпирического и теоретического распределения. Она может относиться и к сопоставлению тех или иных параметров, например средних или дисперсий.
Обычно, следуя идее Дж.Неймана и Э.Пирсона, принимается начальная, или нулевая, гипотеза об отсутствии различия, которая обозначается 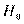 [124].
[124].
В каждом отдельном случае определяется характеристика (критерий), по которой идет проверка. Если проверяется какой- либо параметр, а выборочное распределение его при данной гипотезе хорошо известно, то устанавливается предел вероятности, или уровень значимости. Значения характеристики, вероятности которых меньше уровня значимости, образуют так называемую критическую область, а значения, вероятности которых больше уровня значимости — область допустимых значений. Пусть дано выборочное распределение некоторой характеристики и (рис. 7).
Возможны два типа ошибок — так называемые ошибки первого и второго рода. Ошибка первого рода состоит в отбрасыва-
нии нулевой гипотезы , когда она верна. Ошибка второго рода связана с принятием нулевой гипотезы, когда она неверна.
Уровень значимости  определяет вероятность ошибки первого рода. Обозначим вероятность ошибки второго рода
определяет вероятность ошибки первого рода. Обозначим вероятность ошибки второго рода  . С уменьшением увеличивается . Величина 1 — называется мощностью критерия, с увеличением которой уменьшается вероятность ошибки второго рода[125].
. С уменьшением увеличивается . Величина 1 — называется мощностью критерия, с увеличением которой уменьшается вероятность ошибки второго рода[125].
При проверке гипотез приходится находить разумное соотношение уровня значимости и мощности критерия. Нельзя сделать
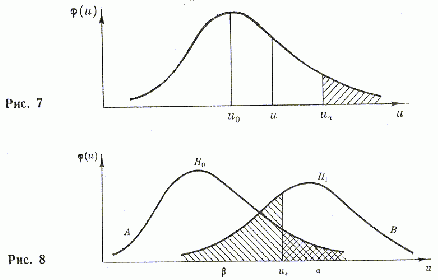
как угодно малыми одновременно и  , и
, и  . Здесь следует учитывать сложившуюся ситуацию. Это можно представить графически (рис. 8).
. Здесь следует учитывать сложившуюся ситуацию. Это можно представить графически (рис. 8).
Кривая А связана с гипотезой . Кривая В связана с альтернативной гипотезой  ;
; 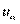 — значение критерия, соответствующее уровню значимости .
— значение критерия, соответствующее уровню значимости .
Площадь справа от под кривой дает — вероятность ошибки первого рода.
Значение  соответствует генеральной характеристике. Точка определяет критическую область в том смысле, что вероятность значений
соответствует генеральной характеристике. Точка определяет критическую область в том смысле, что вероятность значений 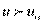 оказывается меньше уровня значимости (заштрихованная площадь справа от равна ); обычно полагают равным 1, 2 и 5%. Для каждого критерия строятся специальные таблицы, в которых имеются значения для каждой вели- чины значения и объема выборки.
оказывается меньше уровня значимости (заштрихованная площадь справа от равна ); обычно полагают равным 1, 2 и 5%. Для каждого критерия строятся специальные таблицы, в которых имеются значения для каждой вели- чины значения и объема выборки.
Если уменьшать , то, следовательно, будет уменьшаться вероятность отбрасывания верной гипотезы, иначе говоря, станет меньше вероятность ошибки первого рода, но вместе с тем расширится область допустимых значений критерия. Таким образом, если в действительности нулевая гипотеза неверна, то увеличивается вероятность принятия неверной гипотезы.
Когда нулевая гипотеза неверна, то тем самым верна какая-то другая, альтернативная гипотеза  . Возможны такие случаи:
. Возможны такие случаи:
1) критерий отвергает , и верна ;
2) критерий отвергает , а верна ;
3) критерий допускает , и верна ;
4) критерий допускает , а верна .
Во втором и третьем случаях проверка гипотезы приводит к правильному выводу. Первый случай обусловливает ошибку первого рода, четвертый случай — второго рода.
Площадь слева от под кривой определяет , вероятность ошибки второго рода, т.е. вероятность принять гипотезу, когда она неверна.
Таковы некоторые положения о статистическом выводе. Использование математического аппарата статистического вывода имеет исключительно большое значение для социологии, так как, во-первых, социолог практически может проанализировать всю генеральную совокупность, а во-вторых, элементы генеральной совокупности в социологии гораздо более сложны и специфичны, чем в других областях науки.
Если ставится задача установить по выборке закон распределения, то используется так называемый критерий 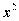 . При сравнении двух выборочных средних используется t-критерий, при сравнении двух выборочных дисперсий — F-критерий[126].
. При сравнении двух выборочных средних используется t-критерий, при сравнении двух выборочных дисперсий — F-критерий[126].
Измерение связи
Из школьного курса математики известно понятие функциональной связи, когда каждому значению независимой перемен- ной (аргумента х) ставится определенное значение зависимой переменной (функции у):
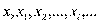

Функция может быть однозначной и многозначной. Так, дли- на окружности есть однозначная функция радиуса: 1=2  . Квад-
. Квад-
ратный корень из действительного числа — двузначная функция этого числа: у=  . Обратные тригонометрические функции угла дают простейший пример многозначных функций.
. Обратные тригонометрические функции угла дают простейший пример многозначных функций.
На графике, в случае однозначной функции, каждой паре значений х и у соответствует точка плоскости. Множество этих точек на плоскости представляет собой графическое изображение функциональной связи, или график функции у=1(х).
Однако в природе существуют не только функциональные связи такого рода.
Рассмотрим обычную игру в карты. При сдаче игрок получает некоторое множество карт. При следующей — другое множество карт и т.д. При каждой сдаче получается новая комбинация. Налицо — связь между сдачей и комбинацией карт игрока.
В этом случае с изменением одной переменной происходит изменение распределения другой переменной. Связь этих переменных называется статистической. Если оказывается, что с изменением одной переменной изменяется среднее значение другой, то говорят, что между этими переменными существует корреляционная связь.
Например, требуется определить зависимость между ростом жены и мужа. Для примера рассмотрим 100 супружеских пар. На плоскости дана прямоугольная система координат, по оси х откладывается рост мужа, по оси у — рост жены. Точкой на плоскости отмечается каждая супружеская пара. Полученное графическое изображение называется корреляционным полем (рис. 9).

В нашем случае должно быть 100 точек, которые как-то заполняют плоскость этого корреляционного поля. Для каждого класс-интервала х отбираем все соответствующие ему точки. Находим их среднее значение 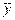 . Эту точку наносим на график, обозначая ее крестиком, чтобы выделить среди прочих. Соединяем ломаной все отмеченные крестиком точки. Полученная линия показывает изменение среднего значения роста жены с изменением
. Эту точку наносим на график, обозначая ее крестиком, чтобы выделить среди прочих. Соединяем ломаной все отмеченные крестиком точки. Полученная линия показывает изменение среднего значения роста жены с изменением
роста мужа от одного класс-интервала к другому. Эта линия называется эмпирической линией регрессии.
Если рассмотреть 100 других пар, то получится несколько иная эмпирическая линия регрессии. Если уменьшить величину класс-интервала, то линия покажет увеличение числа звеньев, сохранив в целом контур. Можно убедиться, что все эмпирические линии регрессии каких-либо двух переменных всегда лежат около некоторой плавной линии, называемой теоретической линией регрессии, или просто линией регрессии[127]. Ее уравнение называется уравнением регрессии. Если мы рассматриваем изменение среднего у от х, то получится уравнение регрессии у на х:

Если рассматриваем изменение среднего  от
от  , то уравнение регрессии
, то уравнение регрессии  на ;
на ;
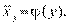
При  говорят о линейной регрессии на , т.е.
говорят о линейной регрессии на , т.е.  . Аналогично можно ввести уравнение регрессии х на у:
. Аналогично можно ввести уравнение регрессии х на у:

Как найти коэффициенты уравнений регрессии? Предположим, что дано и объектов, характеризующихся двумя переменными:  и
и 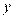 . Для простоты полагаем, что средние и равны 0. Выбираем прямоугольную систему координат , строим корреляционное поле, устанавливаем класс-интервалы для и для , проводим эмпирические линии регрессии, полагая, что искомые линии регрессии — прямые (рис. 10). Символически данная зависимость обозначается так:
. Для простоты полагаем, что средние и равны 0. Выбираем прямоугольную систему координат , строим корреляционное поле, устанавливаем класс-интервалы для и для , проводим эмпирические линии регрессии, полагая, что искомые линии регрессии — прямые (рис. 10). Символически данная зависимость обозначается так:  .
.
Линия ACDF — эмпирическая линия регрессии на ; PQ— линия регрессии, а ее уравнение  , коэффициенты котороro
, коэффициенты котороro  и
и  неизвестны и их надо найти.
неизвестны и их надо найти.
Коэффициенты теоретической линии регрессии находят по методу наименьших квадратов: ищут эту линию при том условии, чтобы сумма квадратов расстояний эмпирической линии регрессии от теоретической была бы минимальной. Иначе говоря, теоретическая линия регрессии должна иметь наиближайшее расположение ко всем точкам эмпирической линии регрессии.
Если мы обозначили ординату теоретической линии регрессии  , эмпирической —
, эмпирической —  , то надо найти минимум величины:
, то надо найти минимум величины:


Это означает, что
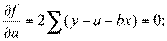
 .
.
Получаем нормальные уравнения для определения коэффициентов линии регрессии:


или
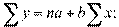

Поскольку средние и , как мы предположили, равны нулю
то 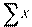 = 0;
= 0;  = 0 и, следовательно, = 0;
= 0 и, следовательно, = 0; 
где  — дисперсия .
— дисперсия .
Найденный коэффициент называется коэффициентом регрессии на и обозначается  .
.
Аналогично можно построить линию регрессии на и соответственно найти коэффициент:

где  — дисперсия y.
— дисперсия y.
Коэффициент корреляции определяют как среднее геометрическое из коэффициентов регрессии[128]:

Дадим геометрическую интерпретацию коэффициенту корреляции[129] (рис. 11).

OP — это линия регрессии у на х;
OQ — линия регрессии х на у;  ;
;  по определению коэффициентов регрессии
по определению коэффициентов регрессии
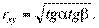
Если корреляции нет, то или линия OP, или OQ или обе вместе совпадают с осями координат, так как: =0 или =0 и, следовательно, r = 0.
Еcли корреляционная связь переходит в функциональную, то обе линии регрессии совпадают. Тогда 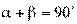 ,
, 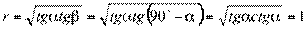 , т.е. коэффициент корреляции равен 1.
, т.е. коэффициент корреляции равен 1.
Чем теснее связь между переменными, тем меньше угол меж- ду обеими линиями регрессии.
Рассмотренный коэффициент корреляции измеряет линейную связь между двумя количественными переменными. Этим, одна-
ко, не исчерпывается все возможное многообразие связей в социологии.
Во-первых, переменные могут иметь криволинейную регрессию: линия регрессии может быть параболой, кубической параболой, экспонентой и т.п. В каждом случае надо находить пути измерения связи между данными переменными.
Во-вторых, возможно наличие связи между более чем двумя переменными. Это проблема множественной корреляции, или многофакторного корреляционного анализа.
В-третьих, возможно существование связи между не только количественными переменными. В этом случае в статистике и социологии используются специальные показатели связи.
В случае криволинейной регрессии вместо коэффициента корреляции (иногда говорят «коэффициента линейной, или парной, корреляции») вводится корреляционное отношение[130].

где  — среднее квадратичное отклонение условных средних
— среднее квадратичное отклонение условных средних 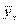 от их средней,
от их средней,  — среднее квадратичное отклонение (аналогично для
— среднее квадратичное отклонение (аналогично для  и
и 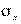 ) и корреляционное отношение
) и корреляционное отношение
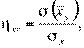
Следовательно, прежде чем определять связь между количественными переменными социального объекта, необходимо сначала построить их линии регрессии и оценить характер регрессии. В том случае, если эмпирическая линия регрессии находится близко от некоторой прямой, можно вычислить коэффициент линейной корреляции Пирсона. Если же эмпирическая линия регрессии — явный изгиб, то надо использовать корреляционное отношение. При наличии более двух количественных переменных применяют частные коэффициенты корреляции[131].
Если, например, рассматривают три переменные х, у, z, то вводят частные коэффициенты корреляции 


 определяет связь между х и r при исключении влияния переменной у:
определяет связь между х и r при исключении влияния переменной у:

где справа находятся обычные коэффициенты парной корреляции. Выражения для двух других коэффициентов получаются простой круговой перестановкой индексов в правой части.
Можно также ввести понятия частых коэффициентов корреляции и сводный коэффициент для и переменных.
Для измерения связи между качественными (номинальными) переменными используется таблица сопряженности.
| B1 | B2 | … | Bj | … | |
| A1 | n11 | n12 | … | n1j | n1. |
| A2 | n21 | n22 | … | n2j | n2. |
| … | … | … | … | … | … |
| Ai | ni1 | ni2 | … | nij | ni. |
| … | n. 1 | n. 2 | … | n. j | n |
Имеются два номинальных признака (переменные) А и В, которые принимают соответственно значения 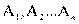 и
и  . Это могут быть, например, образование (начальное, неполное среднее, среднее и высшее), социальное положение (рабочий, крестьянин, служащий, военный), возрастная группа (ученики, молодые рабочие, средний возраст, пожилые кадровые рабочие), участие в общественной жизни (не участвуют, слабо участвуют, участвуют, активно участвуют) и др.
. Это могут быть, например, образование (начальное, неполное среднее, среднее и высшее), социальное положение (рабочий, крестьянин, служащий, военный), возрастная группа (ученики, молодые рабочие, средний возраст, пожилые кадровые рабочие), участие в общественной жизни (не участвуют, слабо участвуют, участвуют, активно участвуют) и др.
Рассмотрим N лиц и их распределение по признакам А и В.
В каждой клетке первой строки пишется число лиц, которые одновременно обладают значением А, признака А и соответствующими значениями признака В, т.е. в левой клетке первой строки стоит и,, число лиц, обладающих признаками А, и В, одновременно, во второй клетке —  число лиц, обладающих признаками
число лиц, обладающих признаками  и
и  и т.д. Вообще в клетке на пересечении i-й строки и j-го столбца находится число
и т.д. Вообще в клетке на пересечении i-й строки и j-го столбца находится число  , обозначающее число лиц, обладающих признаками
, обозначающее число лиц, обладающих признаками  и
и  .
.
Таблица сопряженности в данном случае очень сходна с корреляционной таблицей с той лишь разницей, что первая дает со-
вместные частоты качественных значений признаков, а вторая — совместные частоты класс-интервалов количественных признаков.
Вместо введем относительную частоту  .
.
Пирсон предложил следующий коэффициент связи признаков А и В:
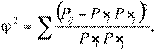
который сконструирован так, что квадраты отклонений взвешенны по отношению к ожидаемым частотам и нейтрализованно влияние значков (как, в случае диоперсии).
При полной независимости переменных  = 0, при полной зависимости число строк равняется t — числу столбцов, и в таком случае = t — 1.
= 0, при полной зависимости число строк равняется t — числу столбцов, и в таком случае = t — 1.
Иногда используют так называемый коэффициент сопряженности в виде
где — только что рассмотренный коэффициент. Коэффициент С
дает более прямое непосредственное указание на связь между признаками.
Для определения связи между ранжированными переменными можно использовать так называемый ранговый коэффициент Спирмена:

где n — число объектов;  — разности между значениями переменных для i-го объекта.
— разности между значениями переменных для i-го объекта.
Рассмотрим числовой пример: даны 13 лиц, проранжированных по двум признакам. Результаты таковы:
| Лица | Ранги | Разности | Лица | Ранги | Разности | ||||
| I | II | Di | 
| I | II | Di |
| ||
| А | Ж | -2 | |||||||
| Б | З | -5 | |||||||
| В | И | ||||||||
| Г | 4,5 | 3,5 | 12,25 | К | 4,5 | 6,5 | 42,25 | ||
| Д | -1 | 8,5 | -1,5 | 2,25 | |||||
| Е | -2 | 8,2 | -2,5 | 6,25 |
И первом столбце — лица; во втором — их ранги по первой переменной (признаку); в третьем — их ранги по второй переменной (признаку); в четвертом — разность рангов этих лиц. В последнем столбце — квадраты разностей, которые используются в формуле.
Можно произвести вычисления. Получим

Большое значение для социологических исследований имеет бисериальный коэффициент корреляции, определяющий связь между, количественной переменной и дихотомической качественной переменной. Он вычисляется по формуле

где 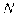 , — число индивидов с положительным ответом по признак;
, — число индивидов с положительным ответом по признак;  — число индивидов с отрицательным ответом по признаку;
— число индивидов с отрицательным ответом по признаку;
N — общее число индивидов;  — средняя в
— средняя в  ;
;  — средняя в ; у — средняя всей группы;
— средняя в ; у — средняя всей группы;
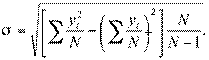
Пример[132].
| Лица | Количественные переменные | Качественная переменная | Лица | Количественные переменные | Качественная переменная | ||
| + | – | + | – | ||||
| А | Ж | ||||||
| Б | З | ||||||
| В | И | ||||||
| Г | К | ||||||
| Д | Л | ||||||
| Е | М |
Вычисления дают:  =0,57.
=0,57.
Представляет интерес для социологии группа коэффициентов для измерения корреляции в четырехклеточной таблице, которые измеряют связь между дихотомическими переменными.
Для таблицы в виде
| – | + | ||
| + | A | B | A + B |
| – | C | D | C + D |
| A + C | B + D |
имеют место коэффициенты

При измерении связи в конкретном социологическом исследовании мы вычисляем коэффициент корреляции по выборке. По сути дела, мы всегда располагаем только некоторой оценкой коэффициента корреляции генеральной совокупности. Любая выборочная оценка, как мы уже отмечали, требует проверки. Без указания точности расчета и проверки статистической гипотезы выборочная оценка не имеет смысла, к ней неизвестно как подступиться.
Остановимся на статистических оценках коэффициента парной корреляции r и рангового коэффициента корреляции Спирмена ρ.
Критические величины коэффициента корреляции Спирмена ρ
| № | Уровень существенности | № | Уровень существенности | ||
| 0,05 | 0,01 | 0,05 | 0,01 | ||
| 1,000 | 0,506 | 0,712 | |||
| 0,900 | 1,000 | 0,456 | 0,645 | ||
| 0,829 | 0,943 | 0,425 | 0,601 | ||
| 0,714 | 0,893 | 0,399 | 0,564 | ||
| 0,643 | 0,833 | 0,377 | 0,534 | ||
| 0,600 | 0,783 | 0,359 | 0,508 | ||
| 0,564 | 0,746 | 0,343 | 0,485 | ||
| 0,329 | 0,465 | ||||
| 0,317 | 0,448 | ||||
| 0,306 | 0,432 |
В случае нормального распределения для r дается выражение ошибки:


Это означает, что коэффициент корреляции 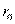 генеральной совокупности с вероятностью 0,997 находится в интервале
генеральной совокупности с вероятностью 0,997 находится в интервале

Если использовать специальные таблицы, то можно построить доверительный интервал при данной доверительной вероятности и проверить нулевую гипотезу равенства выборочного и генерального коэффициентов корреляции.
Для проверки ρ Спирмена используют таблицу критических величин. Если 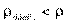 при данном количестве объектов и данном уровне существенности, то считается, что связь между ранговыми переменными существует. В нашем примере, вычисляя коэффициент Спирмена, мы получим значение
при данном количестве объектов и данном уровне существенности, то считается, что связь между ранговыми переменными существует. В нашем примере, вычисляя коэффициент Спирмена, мы получим значение  =0,36. Используя таблицу, мы получим для n = 10 и уровня существенности 0,05
=0,36. Используя таблицу, мы получим для n = 10 и уровня существенности 0,05  =0,564. Следовательно, , и мы полагаем, что ранжирование коррелировано.
=0,564. Следовательно, , и мы полагаем, что ранжирование коррелировано.
Глава третья
Психологические тесты и социологические шкалы

