




Чтобы дать более полное представление о многопроцессорных вычислительных системах, помимо высокой производительности необходимо назвать и другие отличительные особенности. Прежде всего это необычные архитектурные решения, направленные на повышение производительности (работа с векторными операциями, организация быстрого обмена сообщениями между процессорами или организация глобальной памяти в многопроцессорных системах и др.).
Цели, которым должна служить хорошо построенная классификация архитектур:
• облегчать понимание того, что достигнуто на сегодняшний
день в области архитектур вычислительных систем, и какие
архитектуры имеют лучшие перспективы в будущем;
• подсказывать новые пути организации архитектур — речь идет о тех классах, которые в настоящее время по разным причинам пусты;
• показывать, за счет каких структурных особенностей достигается увеличение производительности различных вычислительных систем; с этой точки зрения классификация может служить моделью для анализа производительности.
В 1966 г. М. Флинном (Flynn) был предложен следующий подход к классификации архитектур вычислительных систем. В основу было положено понятие потока, под которым понимается последовательность элементов, команд или данных, обрабатываемая процессором. Соответствующая система классификации основана на рассмотрении числа потоков инструкций и потоков данных и описывает четыре базовых класса. См. вставку ниже.
Коротко рассмотрим отличительные особенности каждой из архитектур.

Процесс решения задачи можно представить как воздействие определенной последовательности команд программы (потока команд) на соответствующую последовательность данных (поток данных), вызываемых этой последовательностью команд. Различные способы организации параллельной обработки информации можно представить как способы организации одновременного воздействия одного или нескольких потоков команд на одни или несколько потоков данных.
Для такой классификации оказывается полезным ввести понятие множественности потоков команд и данных. Под множественным потоком команд или данных будем понимать наличие в системе нескольких последовательностей команд, находящихся в стадии реализации, или нескольких последовательностей данных, подвергающихся обработке командами.
Исходя из возможности существования одиночных и множественных потоков, все системы могут быть разбиты на четыре больших класса.
Архитектура ОКОД (SISD) охватывает все однопроцессорные и одномашинные варианты систем, т. е. с одним вычислителем. Все ЭВМ классической структуры попадают в этот класс. Здесь параллелизм вычислений обеспечивается путем совмещения выполнения операций отдельными блоками АЛУ, а также параллельной работой устройств ввода-вывода информации и процессора. Закономерности организации вычислительного процесса в этих структурах достаточно хорошо изучены.
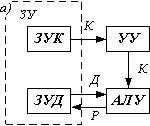
Системы этого класса – обычные однопроцессорные ЭВМ (рис. а), включающие в себя запоминающее устройство (ЗУ) для команд и данных (оно чаще всего бывает общим) и один процессор, содержащий арифметическо-логическое устройство (АЛУ) и устройство управления (УУ). В современных системах этого класса наиболее широко используется первый путь организации параллельной обработки – совмещение во времени различных этапов решения разных задач, при котором в системе одновременно работают различные устройства: ввода, вывода и собственно обработки информации. В общем виде это достаточно подробно рассмотрено в предыдущей главе, однако практическая реализация этого принципа предусматривает и более широкое совмещение работы различных устройств. В отношении ввода–вывода информации – это введение нескольких одновременно работающих каналов ввода–вывода, а также нескольких устройств одного типа: перфокарточных устройств ввода и вывода, печатающих устройств, различного рода накопителей и др. Введение большого числа параллельно работающих периферийных устройств позволяет существенно сократить время на ввод информации и оперативное запоминающее устройство: (ОЗУ), уменьшая общее время решения задачи, и до некоторой степени сгладить разрыв между скоростями работы центральных (процессор и ОЗУ) и периферийных устройств. Значительный эффект в производительности однопроцессорной системы дает разделение ОЗУ на несколько модулей, функционально самостоятельных, что позволяет им работать независимо друг от друга. Производительность увеличивается за счет уменьшения простоев устройств из-за так называемых конфликтов при обращении к ОЗУ.
При параллельной работе многих устройств ввода–вывода и процессора неизбежны ситуации, когда нескольким устройствам требуется обращение к ОЗУ для записи или чтения информации. Такая ситуация и называется конфликтной. Естественно, разрешить этот конфликт можно только путем введения системы приоритетов, которая устанавливает определенную очередность удовлетворения запросов в ОЗУ. При этом неизбежны очереди, а, следовательно, и простои устройств, не имеющих высшего приоритета. В наибольшей степени от этого страдает процессор, так как по принципу своей работы он может ожидать в очереди обслуживания сколь угодно долго, в то время как большинство периферийных устройств, в основном электромеханических, ждать долго не могут или это будет приводить к слишком большим потерям времени. Так, например, если вовремя не считать информацию с накопителя на магнитном диске, то придется потерять несколько миллисекунд (один оборот диска) до следующего момента, когда эта информация может быть считана. При наличии нескольких модулей ОЗУ с независимым управлением есть определенная вероятность того, что различные устройства будут обращаться к различным модулям, а следовательно, очередь к ОЗУ разделится на несколько меньших очередей и время ожидания (т. е. простой устройства) в очереди будет уменьшено. Кроме совмещения во времени различных этапов обработки информации в системах класса ОКОД существенное увеличение производительности достигается за счет введения конвейерной обработки, точнее конвейера команд.
По существу конвейер команд – это также совмещение во времени работы нескольких различных блоков, выполняющих отдельные части общей операции. Если совмещение во времени работы различных устройств можно назвать «макросовмещением», то конвейер является как бы «микросовмещением». При организации конвейера команд очень часто применяются также способы увеличения производительности, базирующиеся на использовании многомодульных ОЗУ. Во-первых, если программы и данные размещать в разных модулях памяти, то это позволит совмещать во времени выборку команды и операнда, что при выполнении ОЗУ в виде одного функционального устройства было бы невозможно. Во-вторых, используется тот факт, что команды и данные обычно при обработке выбираются из некоторой последовательности ячеек памяти с последовательно возрастающими адресами. Если организовать ОЗУ таким образом, что все четные адреса будут принадлежать одному модулю ОЗУ, а все нечетные – другому, и сдвинуть начало цикла работы этих двух модулей на ½ цикла, то при выполнении программы среднее время обращения к ОЗУ существенно уменьшается (в пределе в 2 раза). Этот принцип может быть распространен и на большее число модулей ОЗУ с независимым управлением. При N модулях ОЗУ среднее время обращении к ОЗУ оказывается равным 1/N-й цикла ОЗУ. Такая намять называется памятью с чередованием адресов или расслоением обращений.
В системах класса ОКОД возможна реализация и еще одного способа увеличения производительности – конвейер арифметических и логических операций, который вполне вписывается в этот класс систем, так как поток команд остается один: просто команды разбиваются на некоторое число микроопераций, образуя, таким образом, несколько потоков микрокоманд. По этой причине системы с конвейером арифметических и логических операций относится к следующему классу – МКОД.
Архитектура ОКМД (SIMD) предполагает создание структур векторной или матричной обработки. Системы этого типа обычно строятся как однородные, т. е. процессорные элементы, входящие в систему, идентичны, и все они управляются одной и той же последовательностью команд. Однако каждый процессор обрабатывает свой поток данных. Под эту схему хорошо подходят задачи обработки матриц или векторов (массивов), задачи решения систем линейных и нелинейных, алгебраических и дифференциальных уравнений, задачи теории поля и др. В структурах данной архитектуры желательно обеспечивать соединения между процессорами, соответствующие реализуемым математическим зависимостям. Как правило, эти связи напоминают матрицу, в которой каждый процессорный элемент связан с соседними. Узким местом подобных систем является необходимость изменения коммутации между процессорами, когда связь между ними отличается от матричной. Кроме того, класс задач, допускающих широкий матричный параллелизм, весьма узок. Структуры ВС этого типа, по существу, являются структурами специализированных суперЭВМ.
Элементы технологии SIMD реализованы в процессорах Intel начиная с Pentium MMX (1997 г.).
Системы этого класса также ориентированы на использование параллелизма объектов или данных для повышения производительности. В этой системе по одной и той же (или почти по одной и той же) программе обрабатывается несколько потоков данных, каждый из этих потоков обрабатывается своим АЛУ, работающим однако под общим управлением, за счет чего и достигается высокая производительность системы.
Общая схема может реализоваться разными способами.
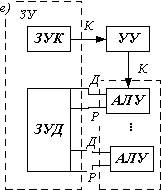
Так, например, АЛУ может представлять собой достаточно сложное устройство, содержащее обрабатывающий процессор и оперативное ЗУ. В этом случае поток данных в каждый процессор поступает из собственного ЗУ. Управление и память команд реализуются отдельной ЭВМ, управляющей ансамблем процессоров. Память данных может иметь не только адресную выборку, но и ассоциативную, т. е. по содержимому памяти.
В системах класса ОКМД могут использоваться для достижения высокой производительности и другие пути параллельной обработки, однако определяющим является одновременная обработка нескольких потоков несколькими процессорами. Поэтому все системы класса ОКМД можно разделить на матричные и ассоциативные
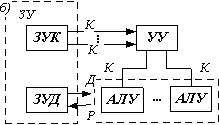
Третий тип архитектуры — МКОД (MISD)(б) предполагает построение своеобразного процессорного конвейера, в котором результаты обработки передаются от одного процессора к другому по цепочке.
Выгоды такого вида обработки понятны. Прототипом таких вычислений может служить схема любого производственного конвейера. В современных ЭВМ по этому принципу реализована схема совмещения операций, в которой параллельно работают различные функциональные блоки, и каждый из них делает свою часть в общем цикле обработки команды. В ВС этого типа конвейеры должны образовывать группы процессоров, Однако при переходе на системный уровень очень трудно выявить подобный регулярный характер в универсальных вычислениях. Кроме того, на практике нельзя обеспечить и «большую длину» такого конвейера, при которой достигается наивысший эффект. Вместе с тем конвейерная схема нашла применение в так называемых скалярных процессорах суперЭВМ, в которых они применяются как специальные процессоры для поддержки векторной обработки.
Структуру систем этого класса можно представить в виде схемы, изображенной на рис. б: несколько потоков команд воздействуют на единственный поток данных. Однако не существует такого класса задач, в которых одна и та же последовательность данных подвергалась бы обработке по нескольким разным программам. По этой причине в чистом виде такая схема до сих пор не реализована.
Как уже отмечалось, реализована другая схема обработки, представленная на рис. в.
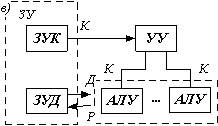
Здесь один поток команд K разделяется устройством управления на несколько потоков микрооперации, каждая из которых реализуется специализированным, настроенным на выполнение именно данной микрооперации, устройством. Поток данных проходит последовательно через, все (или часть) этих специализированных ЛЛУ. Именно такого класса системы принято называть конвейерными или системами с магистральной обработкой информации.
Разумеется, в системах МКОД с целью достижения высокой производительности используется не только конвейер операции. Обычно в таких системах используется и конвейер команд, и различные способы совмещения работы многих устройств. Однако при этом главным, определяющим признаком является наличие конвейера арифметических и логических операций. Заметим также, что системы этого класса развивают максимальную производительность только при решении задач определенного типа, в которых существуют длинные последовательности (цепочки) однотипных операций над достаточно большой последовательностью данных, т. е. когда имеет моего параллелизм объектов или данных.
Архитектура МКМД (MIMD) предполагает, что все процессоры системы работают по своим программам с собственным потоком команд. В простейшем случае они могут быть автономны и независимы. Такая схема использования ВС часто применяется на многих крупных вычислительных центрах для увеличения пропускной способности центра. Большой интерес представляет возможность согласованной работы ЭВМ (процессоров), когда каждый элемент делает часть общей задачи. Общая теоретическая база такого вида работ практически отсутствует. Но можно привести примеры большой эффективности этой модели вычислений. Подобные системы могут быть многомашинными и многопроцессорными. Например, отечественный проект машины динамической архитектуры (МДА) — ЕС-2704, ЕС-2727 — предполагал одновременное использование сотни процессоров.
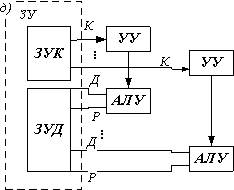
Обобщенная структура представлена на рис d. В этой системе по одной и той же (или почти по одной и той же) программе обрабатывается несколько потоков данных, каждый из этих потоков обрабатывается своим АЛУ, работающим однако под общим управлением, за счет чего и достигается высокая производительность системы.
Общая схема, представленная на рис. d, может реализоваться разными способами. Так, например, АЛУ может представлять собой достаточно сложное устройство, содержащее обрабатывающий процессор и оперативное ЗУ. В этом случае поток данных в каждый процессор поступает из собственного ЗУ. Управление и память команд реализуются отдельной ЭВМ, управляющей ансамблем процессоров. Память данных может иметь не только адресную выборку, но и ассоциативную, т. е. по содержимому памяти.
В системах класса ОКМД могут использоваться для достижения высокой производительности и другие пути параллельной обработки, однако определяющим является одновременная обработка нескольких потоков несколькими процессорами. Поэтому все системы класса ОКМД можно разделить на матричные и ассоциативные.
Характеристики ВС
Производительность.
Производительность – характеристика вычислительной мощности системы, определяющая количество вычислительной работы, выполняемой системой за единицу времени.
Время ответа.
Время ответа, иначе время пребывания заданий, (задач) в системе, – длительность промежутка времени от момента поступления задания в систему до момента окончания его выполнения.
Характеристики надежности.
Надежность – свойство системы выполнять возложенные на нее функции в заданных условиях функционирования с заданными показателями качества(достоверностью результатов, пропускной способностью, временем ответа и др.).
Стоимость.
Стоимость ВС – это суммарная стоимость технических средств и программного обеспечения.
Емкость памяти, которая влияет на характеристики вычислительной системы.
Коэффициент готовности вычислительной системы, который определяет вероятность безотказной работы в текущий момент времени.

