Исходным материалом для статистического исследования служит:совокупность из N наблюдений, которая может быть извлечена из еще большей совокупности, называемой генеральной.
N = 1000
Выбрать из генеральной совокупности выборку
Основой любых выводов о вероятностных свойствах генеральной совокупности X, т.е. статистических выводов, является выборочный метод, суть которого заключается в том, что свойства случайной величины X устанавливаются путем изучения тех же свойств на случайной выборке и генеральной совокупности.
n = 100
Назначить для выборки анализируемый признак
Исследуемый признак Х
Записать выборку (по назначенному признаку) в (произвольной последовательности) последовательности значений
Каждое значение исследуемой величины хi (n = 1 … n)Значения хi называются вариантами
Пример.
Имеется выборка значений механической скорости бурения vм коронкой И4ДП-59 в трещиноватых и абразивных породах X — XI категорий по буримости:
0,67
0,70
0,75
0,72
0,71
0,80
0,78
0,77
0,71
0,74
0,78
0,68
0,85
0,74
0,77
0,71
0,77
0,72
0,84
0,76
0,74
0,76
0,80
0,75
0,74
0,74
0,81
0,79
0,75
0,71
0,69
0,76
0,79
0,73
0,78
0,73
0,75
0,76
0,77
0,75
0,70
0,82
0,85
0,80
0,72
0,77
0,79
0,83
0,77
0,75
0,82
0,71
0,85
0,78
0,75
0,75
0,73
0,72
0,73
0,75
0,76
0,74
0,76
0,76
0,78
0,84
0,75
0,74
0,73
0,82
0,69
0,81
0,81
0,76
0,78
0,72
0,71
0,83
0,73
0,77
Построить вариационный ряд
Последовательность, записанная в возрастающем порядке — вариационным рядом
Вариационным рядом для этой выборки служит последовательность значений механической скорости бурения, м/час:
0,67
0,73
0,76
0,78
0,68
0,73
0,76
0,79
0,69
0,73
0,76
0,79
0,69
0,74
0,76
0,79
0,70
0,74
0,76
0,80
0,70
0,74
0,76
0,80
0,71
0,74
0,76
0,80
0,71
0,74
0,76
0,81
0,71
0,74
0,77
0,81
0,71
0,74
0,77
0,81
0,71
0,75
0,77
0,82
0,71
0,75
0,77
0,82
0,72
0,75
0,77
0,82
0,72
0,75
0,77
0,83
0,72
0,75
0,77
0,83
0,72
0,75
0,78
0,84
0,72
0,75
0,78
0,84
0,73
0,75
0,78
0,85
0,73
0,75
0,78
0,85
0,73
0,75
0,78
0,85
Вычислить характеристики вариационного ряда
Объем выборки 80 значений.
Минимальное значение вариационного ряда xmin = ___.
Максимальное значение ряда xmax = ____.
Размах выборки R = xmax - xmin = ______.
Построить группированный статистический ряд
Статистическим рядом (распределением) выборки - перечень вариант и соответствующих им частот или относительных частот.Статистический ряд с абсолютными частотами для исходной выборки:
yi
-3
-2
-1
0
1
2
ni
1
1
3
2
2
1
Статистический ряд с относительными частотами
yi
-3
-2
-1
0
1
2
0,1
0,1
0,3
0,2
0,2
0,1
Статистический группированный ряд
Механическая скорость бурения, хi м/ч
0,67
0,68
0,69
0,70
0,71
0,72
0,73
0,74
Абсолютная частота совпадений значений СВ, ni
1
1
2
2
6
5
6
7
xi, м/ч
0,75
0,76
0,77
0,78
0,79
0,80
0,81
0,82
ni
10
8
7
6
3
3
3
3
xi, м/ч
0,83
0,84
0,85
ni
2
2
3
Построить интервальный статистический ряд
Группированный статистический ряд - совокупность середин интерваловzk = (xk+xk+1)/2и соответствующих им частот nk.Группированный статистический ряд используется преимущественно при анализе вида распределения случайных величин по данным наблюдений.
Выбрать число интервалов
Выбор числа интервалов зависит от размаха и объема выборкиЧисло интервалов группировки выбирается произвольно,обычно не менее пяти и не более 15Число интервалов при n = 200-300 и более ряд авторов рекомендуют брать в пределах от 10 до 20Следует учитывать, чтопри большом числе интервалов картина распределения искажается случайными зигзагами частот,при слишком малом характерные особенности распределения получается слишком сглаженнойДля построения группированного ряда принятоt = ______ интервалов.Ширина интервалов оправляются по формуле:rt = R/t + Δt,
Вычислить границы интервалов
Границы определяются так:
Значение левой границы + ширина интервала
Значения границ интервалов
Номер интервала, t
Значение левой границе интервала
Значение правой границе интервала
Построить таблицу с группированным рядом
Среднее значение xi определяется как среднее арифметическое значений случайной величины, попавших в интервал
Группированный статистический ряд
Номер интервала
Границы интервалов
Среднее значение xi
Частоты попадания в интервал
Накопленная частота
Определитьотносительные частоты (частости)
Числа ni называются частотами,Отношения частот к объему выборки n называются относительными частотами WiWi = ni/n (1)
Группированный статистический ряд
Номер интервала
Границы интервалов
Среднее значение xi
Относительные частоты попадания в интервал
Проверить правильность определения относительных частот
Контроль: ∑Wi = 1
W = 0,1+0,2+0,25+0,3+0,15 = 1.
Построить статистические диаграммы
Для наглядности сгруппированные статистические ряды представляют графиками:гистограмма, полигон, кумулята; огива.
Построить гистограмму и полигон
Гистограмма представляет собой столбиковую диаграмму частот.
По горизонтальной оси диаграммы откладывают измеренные значения из набора данных, по вертикальной – частоту встречаемости этих значений.
Высота каждого столбца показывает частоту (количество) значений из набора данных, принадлежащих соответствующему интервалу, равному ширине этого столбца.
Визуальный анализ гистограмм позволяет выявить характер распределения данных и ответить на следующие шесть вопросов:
1. Какие значения типичны для заданного набора данных?
2. Как различаются между собой значения (диапазон значений)?
3. Сконцентрированы ли данные вокруг некоторого типичного значения?
4. Какой характер имеет эта концентрация данных? В частности, одинаков ли характер «затухания» для малых и больших значений данных?
5. Есть ли в заданном наборе такие значения, которые сильно отличаются от остальных и требуют специальной обработки (выбросы)?
6. Можно ли сказать, что в целом это однородный набор или отчетливо наблюдается наличие групп, которые надо анализировать отдельно?
Определить накопленные частоты
Таблица 5 - Группированный статистический ряд
Номер интервала
Границы интервалов
Среднее значение xi
Частоты попадания в интервал
Накопленная частота
Построить кумуляту и огиву
Определить среднее значение СВ
Среднее арифметическое значение определяется тогда, когда все варианты (значения СВ) имеют одну и ту же частоту, равную единице (нет одинаковых значений СВ), что характерно для малых выборок
Определить средневзвешенное значение СВ
Если варианты имеют различные частоты, что характерно для больших выборок, то рассчитывают среднее взвешанное значение СВ по следующей формуле:
Определить моду
Мо́да — значение во множестве наблюдений, которое встречается наиболее часто.
(Мода = типичность.)
Выборочной модой М0 называется элемент выборки, имеющий наибольшую частоту.
Мода этого вариационного ряда равна 12.
Модой m0 называют варианту, которая имеет наибольшую частоту, т.е. соответствует вершине распределения (это наиболее вероятное значение случайной величины).
Оценивают моду по следующей формуле
,
где:
- нижняя граница модального интервала, т.е. интервала, имеющего наибольшую частоту;
h – длина интервала разбиения (шаг);
- частота модального интервала;
- частота интервала, предшествующего модальному интервалу;
- частота интервала, следующего за модальным интервалом.
Иногда в совокупности встречается более чем одна мода
(например: 6, 2, 6, 6, 8, 9, 9, 9, 10; мода = 6 и 9).
В этом случае можно сказать, что совокупность мультимодальна.
Как правило мультимодальность указывает на то, что набор данных не подчиняется нормальному распределению.
Определить выборочную медиану
Выборочной медианой те называется варианта (элемент выборки), которая делит пополам вариационный ряд на две части с одинаковым числом вариант в каждой.
Медиана (m0,5) – это значение СВ, которое делит вариационный ряд или площадь, ограниченную кривой распределения, на две равные части.
Выполнить оценку степени разброса значений СВ
Для оценки степени разброса пользуются несколькими показателями, из которых наиболее широко распространены следующие:
ДИСПЕРСИЯ (D) – это среднее арифметическое значение квадратов отклонений отдельных вариант от их средней арифметической
Определить дисперсию
Одна из причин проведения статистического анализа заключается в необходимости учитывать влияние на исследуемый показатель случайных факторов (возмущений), которые приводят к разбросу (рассеянию) данных.
Решение задач, в которых присутствует разброс данных, связано с риском, поскольку даже при использовании всей доступной информации нельзя точно предугадать, что же произойдет в будущем.
Для адекватной работы в таких ситуациях целесообразно понимать природу риска и уметь определять степень рассеяния набора данных.
Существуют три числовые характеристики, описывающие меру рассеяния:
стандартное отклонение, размах и коэффициент вариации (изменчивости).
В отличие от типических показателей (среднее, медиана, мода), характеризующих центр, характеристики рассеяния показывают, насколько близко к этому центру располагаются отдельные значения набора данных.
Формула для вычисления дисперсии выглядит следующим образом (для интервального ряда):
D =
Определить среднее квадратическое отклонение
СРЕДНЕЕ КВАДРАТИЧЕСКОЕ ОТКЛОНЕНИЕ (s) – это значение корня квадратного из дисперсии (для вариационного ряда).
Определить коэффициент вариации
Коэффициент вариации представляет собой относительную меру изменчивости данных и определяется как результат деления стандартного отклонения на среднее значение.
Коэффициент вариации показывает, какой процент от среднего (или доля среднего) составляет стандартное отклонение.
Коэффициент вариации является безразмерной величиной, поэтому он может быть полезен при сравнении изменчивости данных, представленных в разных единицах.
Коэффициент вариации часто используют при проведении сравнений в условиях различных объемов.
Следует отметить, что при ассиметричном (скошенном) распределении данных коэффициент вариации может превысить 100%.
Такой результат означает, что в изучаемой ситуации наблюдается очень сильный разброс данных относительно среднего.
КОЭФФИЦИЕНТ ВАРИАЦИИ () – это отношение среднего квадратического отклонения к среднему значению СВ, выраженное в процентах
. (12)
Чем больше коэффициент вариации , тем больше разброс значений СВ вокруг среднего значения, тем менее представительно .
Применить в Excel модуле Анализ данных включает в себя два инструмента для анализа одномерного набора данных: «Описательная статистика».
С помощью инструмента Описательная статистика рассчитываются показатели, характеризующие типические значения, изменчивость и ассиметрию данных.







 ,
где:
,
где:
 - нижняя граница модального интервала, т.е. интервала, имеющего наибольшую частоту;
h – длина интервала разбиения (шаг);
- нижняя граница модального интервала, т.е. интервала, имеющего наибольшую частоту;
h – длина интервала разбиения (шаг);
 - частота модального интервала;
- частота модального интервала;
 - частота интервала, предшествующего модальному интервалу;
- частота интервала, предшествующего модальному интервалу;
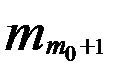 - частота интервала, следующего за модальным интервалом.
Иногда в совокупности встречается более чем одна мода
(например: 6, 2, 6, 6, 8, 9, 9, 9, 10; мода = 6 и 9).
В этом случае можно сказать, что совокупность мультимодальна.
Как правило мультимодальность указывает на то, что набор данных не подчиняется нормальному распределению.
- частота интервала, следующего за модальным интервалом.
Иногда в совокупности встречается более чем одна мода
(например: 6, 2, 6, 6, 8, 9, 9, 9, 10; мода = 6 и 9).
В этом случае можно сказать, что совокупность мультимодальна.
Как правило мультимодальность указывает на то, что набор данных не подчиняется нормальному распределению.



 ) – это отношение среднего квадратического отклонения к среднему значению СВ, выраженное в процентах
) – это отношение среднего квадратического отклонения к среднему значению СВ, выраженное в процентах
 . (12)
Чем больше коэффициент вариации
. (12)
Чем больше коэффициент вариации  .
. 


