




Следует сразу же отметить, что принципиальной разницы между многофакторным и однофакторным дисперсионным анализом нет. Многофакторный анализ не меняет общую логику дисперсионного анализа, а лишь несколько усложняет ее, поскольку, кроме учета влияния на зависимую переменную каждого из факторов по отдельности, следует оценивать и их совместное действие. Таким образом, то новое, что вносит в анализ данных многофакторный дисперсионный анализ, касается в основном возможности оценить межфакторное взаимодействие. Тем не менее, по-прежнему остается возможность оценивать влияние каждого фактора в отдельности. В этом смысле процедура многофакторного дисперсионного анализа (в варианте ее компьютерного использования) несомненно более экономична, поскольку всего за один запуск решает сразу две задачи: оценивается влияние каждого из факторов и их взаимодействие.
Общая схема двухфакторного эксперимента, данные которого обрабатываются дисперсионным анализом имеет вид:
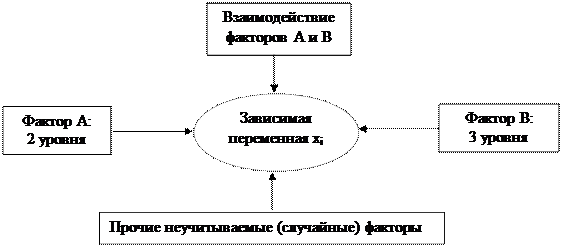 |
Данные, подвергаемые многофакторному дисперсионному анализу, часто обозначают в соответствии с количеством факторов и их уровней.
Предположив, что в рассматриваемой задаче о качестве различных m партий изделия изготавливались на разных t станках и требуется выяснить, имеются ли существенные различия в качестве изделий по каждому фактору:
А – партия изделий;
B – станок.
В результате получается переход к задаче двухфакторного дисперсионного анализа.
Все данные представлены в таблице 1.2, в которой по строкам - уровни Ai фактора А, по столбцам – уровни Bj фактора В, а в соответствующих ячейках, таблицы находятся значения показателя качества изделий xijk (i=1,2,...,m; j=1,2,...,l; k=1,2,...,n).
Таблица 1.2 – Показатели качества изделий
| B1 | B2 | … | Bj | … | Bl | |
| A1 | x11l,…,x11k | x12l,…,x12k | … | x1jl,…,x1jk | … | x1ll,…,x1lk |
| A2 | x21l,…,x21k | x22l,…,x22k | … | x2jl,…,x2jk | … | x2ll,…,x2lk |
| … | … | … | … | … | … | … |
| Ai | xi1l,…,xi1k | xi2l,…,xi2k | … | xijl,…,xijk | … | xjll,…,xjlk |
| … | … | … | … | … | … | … |
| Am | xm1l,…,xm1k | xm2l,…,xm2k | … | xmjl,…,xmjk | … | xmll,…,xmlk |
Двухфакторная дисперсионная модель имеет вид:
xijk=м+Fi+Gj+Iij+еijk,
где xijk - значение наблюдения в ячейке ij с номером k;
м - общая средняя;
Fi - эффект, обусловленный влиянием i-го уровня фактора А;
Gj - эффект, обусловленный влиянием j-го уровня фактора В;
Iij - эффект, обусловленный взаимодействием двух факторов, т.е. отклонение от средней по наблюдениям в ячейке ij от суммы первых трех слагаемых в модели;
еijk - возмущение, обусловленное вариацией переменной внутри отдельной ячейки.
Предполагается, что еijk имеет нормальный закон распределения N(0; с2), а все математические ожидания F*, G*, Ii*, I*j равны нулю.
В таблице представлен общий вид вычисления значений, с помощью дисперсионного анализа.
Базовая таблица дисперсионного анализа
| Компоненты дисперсии | Сумма квадратов | Число степеней свободы | Средние квадраты |
| Межгруп-повая (фактор А) | 
| m-1 | 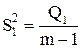
|
| Межгруп-повая (фактор B) | 
| l-1 | 
|
| Взаимодействие | 
| (m-1)(l-1) | 
|
| Остаточная | 
| mln - ml | 
|
| Общая | 
| mln - 1 |
Проверка нулевых гипотез HA, HB, HAB об отсутствии влияния на рассматриваемую переменную факторов А, B и их взаимодействия AB осуществляется сравнением отношений  ,
,  ,
,  (для модели I с фиксированными уровнями факторов) или отношений
(для модели I с фиксированными уровнями факторов) или отношений  ,
, 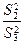 , (для случайной модели II) с соответствующими табличными значениями F – критерия Фишера–Снедекора. Для смешанной модели III проверка гипотез относительно факторов с фиксированными уровнями производится также как и в модели II, а факторов со случайными уровнями – как в модели I.
, (для случайной модели II) с соответствующими табличными значениями F – критерия Фишера–Снедекора. Для смешанной модели III проверка гипотез относительно факторов с фиксированными уровнями производится также как и в модели II, а факторов со случайными уровнями – как в модели I.
Если n=1, т.е. при одном наблюдении в ячейке, то не все нулевые гипотезы могут быть проверены так как выпадает компонента Q3 из общей суммы квадратов отклонений, а с ней и средний квадрат  , так как в этом случае не может быть речи о взаимодействии факторов.
, так как в этом случае не может быть речи о взаимодействии факторов.
Отклонение от основных предпосылок дисперсионного анализа – нормальности распределения исследуемой переменной и равенства дисперсий в ячейках (если оно не чрезмерное) – не сказывается существенно на результатах дисперсионного анализа при равном числе наблюдений в ячейках, но может быть очень чувствительно при неравном их числе. Кроме того, при неравном числе наблюдений в ячейках резко возрастает сложность аппарата дисперсионного анализа. Поэтому рекомендуется планировать схему с равным числом наблюдений в ячейках, а если встречаются недостающие данные, то возмещать их средними значениями других наблюдений в ячейках. При этом, однако, искусственно введенные недостающие данные не следует учитывать при подсчете числа степеней свободы.
Библиография
1. Ермолаев, О.Ю. Математическая статистика для психологов / О.Ю. Ермолаев. - М.: МПСИ: Флинта. - 2002. – 325 с.
2. Наследов, А.Д. Математические методы в психологическом исследовании. Анализ и интерпретация данных / А.Д. Наследов. - СПб.: Речь. - 2004.
3. Бурлачук, Л.Ф., Морозов С.М. Словарь – справочник по психодиагностике / Л.Ф. Бурлачук, С.М. Морозов – СПб: Питер Ком. - 1999. – 528 с.

